
各模型選擇及工作流程
阿新 • • 發佈:2018-11-23
速度問題
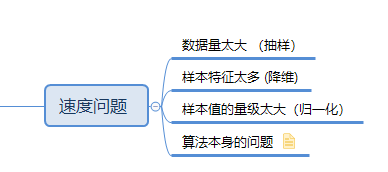
不同的演算法之間,必然有不同的應用場景,比如knn的訓練時間特別短,但是使用的時候消耗的時間就比較長,因為訓練的時候他只是記錄了各個點的位置,並沒有做別的事
而lgc(邏輯迴歸)訓練的時間比較長,要計算各種權重,通過梯度下降找到最優解,但是使用的過程中就比較快,因為模型已經訓練完畢了,後續只需要代入樣本的資料就可以拿到結果
所以選擇什麼演算法,和我們的速度有很大的關係!
模型總結
1.思維導圖

2.完整流程演示
導包
import numpy as np import pandas as pd import matplotlib.pyplot as plt
df = pd.read_table('./data/wheats.tsv',header=None) # 讀取需要我們處理的檔案資料
回顧之前的做法
# 特徵值 目標值 target = df.iloc[:,7] data = df.iloc[:,:-1]
資料需要預處理的情況
先以0.25的預設比例分割資料集 選擇合適的資料處理方式
from sklearn.model_selection import train_test_split # 使用sklearn模組提供的切分方法來做訓練集和測試集的切分 X_train,X_test,y_train,y_test = train_test_split(data,target)from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier() knn.fit(X_train,y_train).score(X_test,y_test) # 0.83
sklearn官網可以檢視各個方法之間的區別,這裡簡單的敘述一下:
MinMaxScaler 區間歸一化 (當前值-最小值)/(最大值-最小值) 把數值的範圍縮放到0-1之間
StandardScaler 標準化 (當前值-平均值)/標準差 均值變成了0 標準差變成了1 把資料集變成標準正態分佈
Normalizer 歸一化 (當前值-平均值)/(最大值-最小值) 對區間進行縮放 -1 1
Binarizer 二值化 (這裡就不嘗試了 主要用來處理圖片)二值化 其實就是把很多值變成兩個值
from sklearn.preprocessing import MinMaxScaler,StandardScaler,Normalizer mms = MinMaxScaler() data.shape mms.fit(data) # mms.fit_transform 如果訓練和轉換用的是同樣的資料集 可以使用fit_transform mms_data = mms.transform(data) # 使用處理後的資料去訓練模型 # 對處理後的資料集進行切分 分成 訓練集 和測試集 X_train1,X_test1,y_train1,y_test1 = train_test_split(mms_data,target) knn.fit(X_train1,y_train1).score(X_test1,y_test1) # 資料量比較小 打分可能有偶然因素 #0.88
可以看出做了區間歸一化的資料對我們的結果預測的準確率有一定的提高
封裝一個方法,專門用來測試資料更適合哪個歸一化的模型(資料預處理模型)


def cross_verify(model,data,target): scores = [] # 按照不同比例去切分 訓練集 和 測試集 for i in np.arange(5,35,1): X_train,X_test,y_train,y_test = train_test_split(data,target,test_size=i/100) score = model.fit(X_train,y_train).score(X_test,y_test) scores.append(score) return np.array(scores).mean()cross_verify
多次打分求平均分
使用不同的資料預處理方式 對資料進行處理
看看不同模型的差異
然後封裝一個測試 最合適的分類模型的函式
# 傳入指定的模型 和 沒有處理之前的 資料的特徵值和目標值(在函式中 我們會進行各種預處理) def prepro(model,data,target): # 先做區間縮放MinMaxScaler mms_data = MinMaxScaler().fit_transform(data) # 列印輸出平均分 print('使用MinMaxScaler預處理得分是:',cross_verify(model,mms_data,target)) # StandardScaler ss_data = StandardScaler().fit_transform(data) print('使用StandardScaler預處理得分是:',cross_verify(model,ss_data,target)) # Normalizer n_data = Normalizer().fit_transform(data) print('使用Normalizer預處理得分是:',cross_verify(model,n_data,target)) # 注意:沒有做過資料預處理的 資料集 也打下分 print('沒有做資料預處理得分是:',cross_verify(model,data,target))prepro
from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier() from sklearn.linear_model import LogisticRegression lgc = LogisticRegression() from sklearn.tree import DecisionTreeClassifier dtree = DecisionTreeClassifier() from sklearn.naive_bayes import GaussianNB gnb = GaussianNB() from sklearn.svm import SVC svc = SVC()
prepro(knn,data,target)
prepro(lgc,data,target)
....
資料不進行預處理的情況
假設 資料 不需要預處理 先做要考慮的是選擇哪種模型,那麼應該怎麼做呢
除了平均分 比較 重要 得分的差異情況也需要參考一下(演算法的穩定性)
def cross_verify2(model,data,target): scores = [] for i in np.arange(5,35,1): X_train,X_test,y_train,y_test = train_test_split(data,target,test_size=i/100) score = model.fit(X_train,y_train).score(X_test,y_test) scores.append(score) # 除了要計算平均值 還要計算標準差 就不返回了 列印輸出 # return np.array(scores).mean() print('使用{}模型,平均分{},標準差是{}'.format(model.__class__.__name__,np.array(scores).mean(),np.array(scores).std()))cross_verify2
# 以列表的形式 傳入多個備選模型 以及資料 def select_model(models,data,target): for model in models: cross_verify(model,data,target)
選擇完模型之後 還需要 看看 不同的引數 對分類的準確率 能否提高
這裡就拿SVC來做例子
# C=1.0 # C指的是 對 誤差樣本的容忍程度 # C越大表示 容忍度越低 容易過擬合 # C越小表示 容忍度越高 容易欠擬合 svc = SVC() # svc.set_params 建立好模型之後 還可以重新對模型的引數進行設定 for i in [0.01,0.1,1.0,10,100,1000,10000]: # svc = SVC(C=i) svc.set_params(C=i) cross_verify(svc,data,target)
工作流程
