
ML筆記 - 模型的選擇及評估
基本概念
誤差(Error):是模型的預測輸出值與其真實值之間的差異。
訓練(Training):通過已知的樣本資料進行學習,從而得到模型的過程。
訓練誤差(Training Error):模型作用於訓練集時的誤差。
泛化(Generalize):由具體的、個別的擴大到一般的,即從特殊到一般,稱為泛化。對機器學習的模型來講,泛化是指模型作用於新的樣本資料(非訓練集)。
泛化誤差(Genaralization Error):模型作用於新的樣本資料時的誤差。
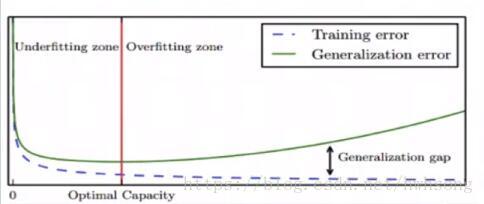
過擬合和欠擬合
模型容量(Model Capacity):是指其擬合各種模型的能力。
過擬合(Overfitting)
模型選擇
模型選擇(Model Selection):針對某個具體的任務,通常會有多種模型可供選擇,對同一個模型也會有多組引數,可以通過分析、評估模型的泛化誤差,選擇泛化誤差最小的模型。
模型評估
通過實驗測試,對模型的泛化誤差進行評估,選出泛化誤差最小的模型。待測資料集全集未知,使用測試集進行泛化測試,測試誤差即為泛化誤差的近似。
- 測試集和訓練集儘可能互斥
- 測試集和訓練集獨立同分布
常用的模型評估方法:
留出法(Hold-out)
將已知資料集分成兩個互斥的部分,其中一部分用來訓練模型,另一部分用來測試模型,評估其誤差,作為泛化誤差的估計。
- 兩個資料集的劃分要儘可能保持資料分佈的一致性,避免因資料劃分過程引入人為的偏差。
- 保持樣本的類別比例相似,即採用分層取樣(Stratified Sampleing)。
- 資料分割存在多種形式會導致不同的訓練集、測試集劃分,單次留出法結果往往存在偶然性,其穩定性較差,通常會進行若干次隨機劃分、重複實驗評估取平均值作為評估方法。
- 資料集拆分成兩部分,每部分的規模設定會影響評估結果,訓練、測試的比例通常為7:3、8:2等。
交叉驗證法(Cross Validation)
將資料集劃分k個大小相似的互斥的資料子集,子集資料儘可能保證資料分佈的一致性(分層取樣),每次從中選取一個數據集作為測試集,其餘用作訓練集,可以進行k次訓練和測試,得到評估均值。
該驗證方法也稱作k折交叉驗證(k-fold Cross Validation)。使用不同的劃分,重複p次,稱為p次k折交叉驗證。
留一法(Leave-One-Out, LOO)
是k折交叉驗證的特殊形式,將資料集分成兩個,其中一個數據集記錄條數為1,作為測試集使用,其餘記錄作為訓練集訓練模型。
訓練出的模型和使用全部資料集訓練得到的模型接近,其評估結果比較準確。
缺點是當資料集較大時,訓練次數和計算規模較大。
自助法(Bootstrapping)
是一種產生樣本的抽樣方法,其實質是有放回的隨機抽樣。即從已知資料集中隨機抽取一條記錄,然後將該記錄放入測試集,同時放回原資料集,繼續下一次抽樣,直到測試集中的資料條數滿足要求。
採用該方法,資料集中的有些資料會在測試集中出現多次,還有一些資料不會出現。
通過有放回的抽樣獲得的訓練集去訓練模型,不在訓練集中的資料(約總數量的1/3)去用於測試,這樣的測試結果被稱作包外估計(Out-of-Bag Estimate, OOB)。
常用模型評估方法的適用場景
留出法
- 實現簡單、方便,在一定程度上能評估泛化方法
- 測試集和訓練集分開,緩解了過擬合
- 一次劃分,評估結果偶然性大
- 資料被拆分後,用於訓練,測試的資料更少了
交叉驗證法/留一法
- k可以根據實際情況設定,充分利用了所有樣本
- 多次劃分,評估結果相對穩定
- 計算比較繁瑣,需要進行k次訓練和評估
自助法
- 樣本集較小時可以通過自助法產生多個自助樣本集,且有約36.8%的測試樣本
- 對於總體的理論分佈沒有要求
- 無放回抽樣引入了額外的偏差
幾種方法的選擇
- 已知資料集數量充足時,通常採用流出法或者k折交叉驗證法
- 對於已知資料集較小且難以有效劃分訓練集和測試集的時候,採用自助法
- 對於已知資料集較小且可以有效劃分訓練集和測試集的時候,採用留一法