Learning Invariant Deep Representation for NIR-VIS Face Recognition
查詢異質影象匹配的過程中,發現幾篇某組的論文,都是關於NIR-VIS的識別問題,提到了許多處理異質影象的處理方法,網路結構和idea都很不錯,記錄其中一篇。
摘要
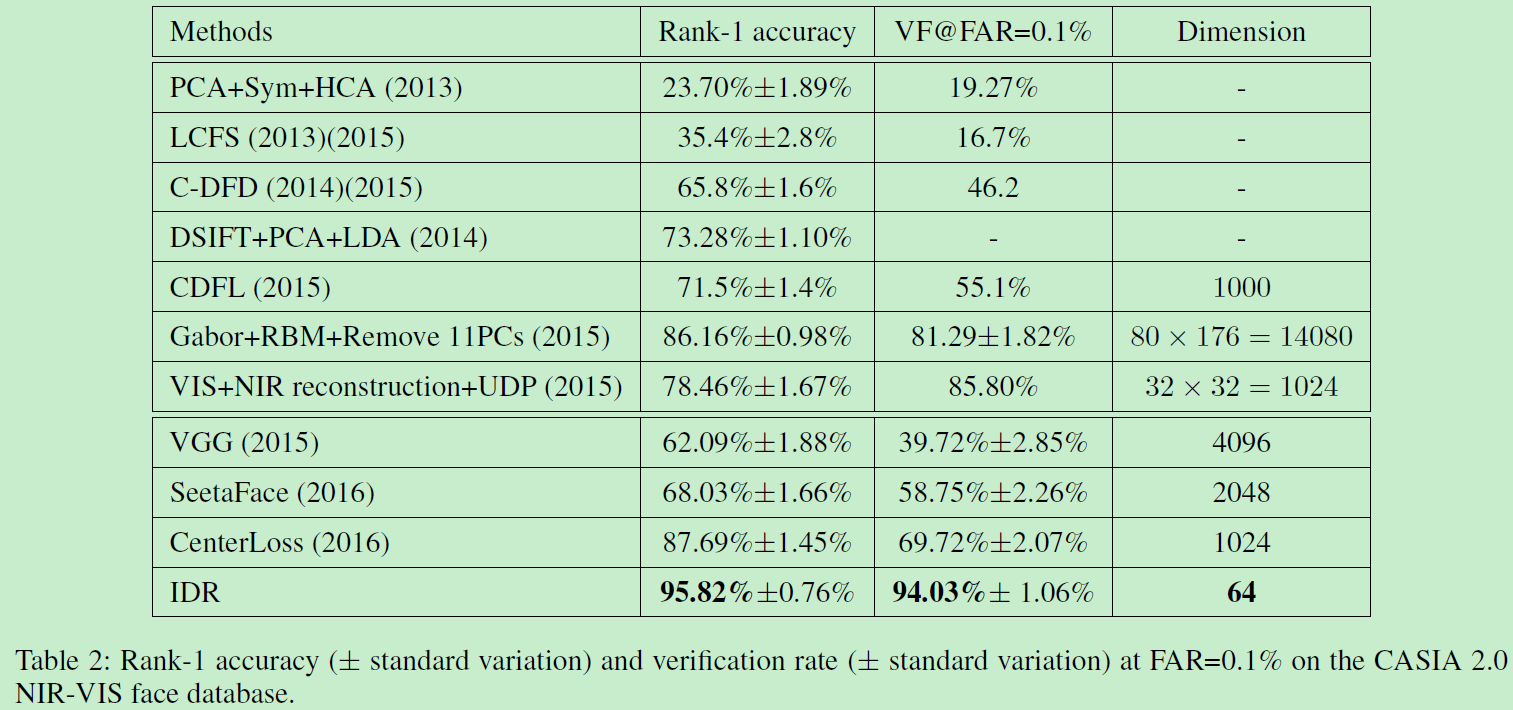
VIS-NIR(可見光與近紅外)面部識別仍然是異質影象識別中的挑戰。本文只用一個網路來對映NIR和VIS影象至一個緊湊的歐式空間。網路的低階層僅僅在大規模VIS資料中訓練。每個卷積層由簡單的maxout operator實現。網路的高階層被劃分為兩個正交的子空間,分別包括模態不變身份資訊(modality-invariant identity information)和模態變化光譜資訊(modality-variant spectrum information)。我們的聯合公式在訓練時引導交替最小化方法得到深度表示,測試時高效計算異質資料。實驗證明了在CASIA NIR-VIS 2.0面部識別資料中實現94 percent的正確率,僅僅有64D大小的表示,比之前低了58 percent的錯誤率。
1. 介紹
NIR影象提供了廉價且簡單的方式來提高在低光照情況下的面部識別能力。對於光照變換沒有VIS那麼敏感,所以被廣泛應用於安檢等。在真實應用中,NIR往往需要和VIS一起使用,導致了兩者之間的匹配問題。這個問題可稱為:NIR-VIS 異質面部識別問題。
NIR與VIS屬於不同光譜,自然有很大的外表差異。所以深度網路在VIS資料訓練後不含有NIR光譜資訊,所以無法很好的解決NIR問題。怎樣利用大規模VIS面部資料來探索NIR和VIS面部模態不變表示值得思考。得益於網路資料,我們可以容易獲得大量VIS面部資料,然而成對的NIR資料難以獲得。怎樣在小規模NIR-VIS資料中學習也是一箇中心問題。
之前的NIR-VIS匹配方法經常利用trick來減輕外觀差異,通過移除一些可能含有光譜資訊的主子空間。Chen在2012提出面部外觀由身份資訊(identity information)和變化資訊(variation information eg.,lighting,poses,expressions)組成。受啟發於此,本文提出一個網路來學習Invariant Deep Representation (IDR)同時包含NIR和VIS人臉資訊,利用一個單一網路來將NIR和VIS影象同時對映到一個壓縮後的歐式空間,使得NIR和VIS影象在嵌入空間embedding space中可以直接對應到面部相似性。
我們的網路首先在大規模VIS資料中訓練,卷積層和全連線由簡化形式的maxout operator實現。 這個網路使得我們學習的到的表示對於類內個體變化很魯棒。然後,網路底層固定,微調NIR資料。高層劃分為兩個正交子空間:模態不變身份資訊(modality-invariant identity information)和模態變化光譜資訊(modality-variant spectrum information)。這個正交限制和maxout operator在高層可以縮減引數空間,因此避免了在小的NIR-VIS資料集上的過擬合。本文提出的IDR達到了SOTA,貢獻如下:
- 一個高效深度網路結構學習模態不變表示,交替最小化高效優化。這個結構可以自然結合之前的不變特徵提取和子空間學習到一個統一網路。
- 兩個正交子空間嵌入網路中來建模身份和光譜資訊。使得可以提取壓縮後的表示,減小了小資料中的過擬合問題。
- 在資料集CASIA NIR-VIS 2.0面部資料上以64維的表示達到SOTA。
2. 相關工作
許多工作提出來減輕異質影象的外觀差異。大多數方法可以分為三類:image synthesis, subspace learning、invariant feature extraction。
1)Image synthesis
主要從一個模態合成面部影象到另一個模態使得異質影象可在同一距離空間比較。
2)subspace learning
學習對映異質資料到一個共同的空間。當前sota方法是通過移除一些主子空間成分來解決。
3)Invariant feature extraction
即尋找模態不變特徵使得對光照魯棒。傳統方法較多。
儘管很多方法,NIR-VIS識別表現仍然很low。遠不如VIS資料結果好。很少有dl方法處理NIR-VIS,所以本文用DL方法來解決。
3. Invariant Deep Representation
本節介紹子空間分解和不變性特徵提取,來學習模態不變深度表示。

注意到移除光譜資訊有助於提高NIR-VIS識別表現。我們進一步三個對映矩陣(W,P,見上圖)來建模身份不變資訊和不變光譜資訊。所以特徵表示可以表示如下:
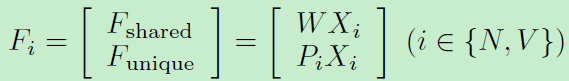
WX和PX分別代表共享特徵和獨立特徵。考慮到子空間分解特性關於矩陣W和P:我們進一步提出一個正交限制使他們互相無關:
![]()
利用softmax函式來訓練整個網路:

優化方法:
上式包含一些非凸變數,我們利用一種交替優化方法來最小化目標函式。首先根據朗格朗日乘子,重寫上述函式:
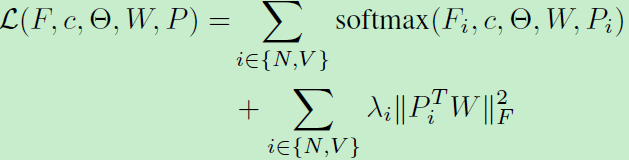
待優化引數有網路引數、W、P。利用交替優化更新,網路引數初始化利用Xavier,W和P初始化:
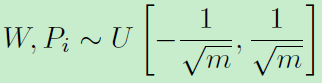
網路結構:lightened CNN B network(同作者另一作品:A Light CNN for Deep Face Representation with Noisy Labels)網路包括9個卷積層+4個最大池化層+全連線。Dropout設為0.7。初始學習率0.001,降到0.00001。基於該網路實現本文,特徵層用來對映低階特徵到兩個正交子空間。
4. 其他要點
演算法分析:分析本文提出的不變性深度表徵: invariant deep representation (IDR)
我們實現了兩種版本的IDR:DR表示IDR沒有NIR特徵和VIS特徵。即僅僅訓練卷積網路,沒有子空間分解。這會導致大量引數在全連線和特徵層,導致在小資料NIR-VIS上過擬合。特徵層的maxout operator也有助於減少過擬合。因此,IDRm表示IDR沒有maxout operator在特徵層。
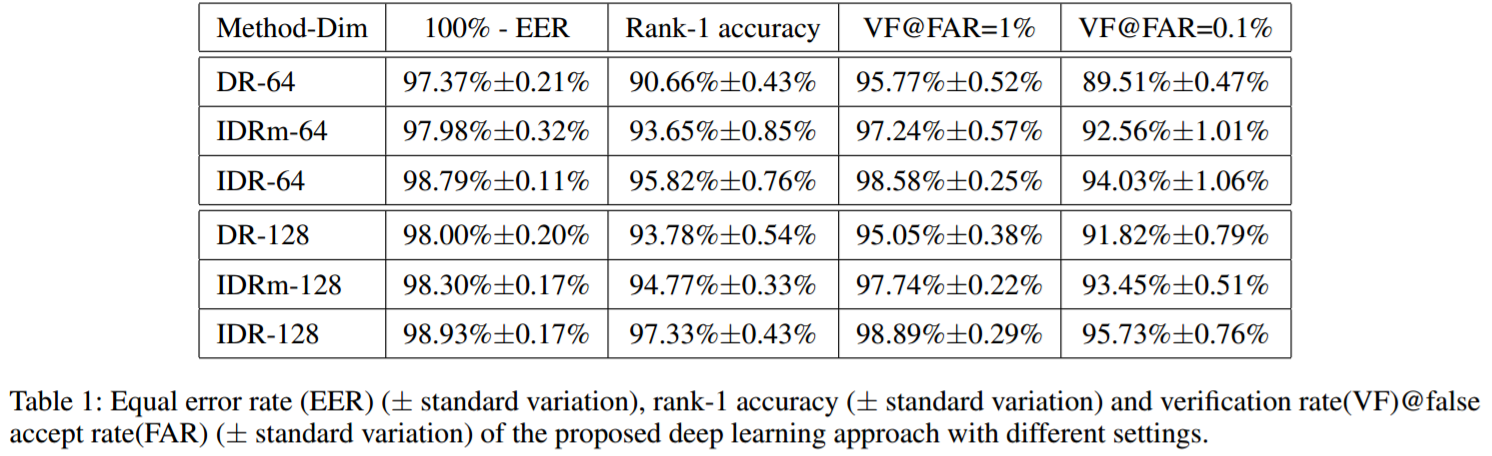
上圖表明IDR是最好的結果。對比IDR和IDRm,注意到maxout operator在最後一個卷積層可進一步降低equal error rate,並提高表現。
最後再附兩張碾壓效能圖: