
【論文理解】ArcFace: Additive Angular Margin Loss for Deep Face Recognition(InsightFace)
這篇論文基本介紹了近期較為流行的人臉識別模型,loss變化從softmax一路捋到CosFace,然後提出ArcFace,可以說起到很好的綜述作用。論文評價對比方面也做了非常詳細的對比策略方案分析。資料清洗工作也對後續研究應用有較大意義。資料和程式碼都開源,相當良心。
本文主要工作概述:
在三個影響人臉識別模型精度的主要因素上都做了相關工作
(1) 資料
對MS-Celeb-1M,MegaFace FaceScrub做了清洗。清洗後的資料公開。
(2) 網路
詳細對比了不同的主流網路結構的效能,提出了能夠在較大姿態和時間跨度上表現較好的網路block形式。
(3) Loss
詳細分析了L-softmax,Sphereface,ConsineFace等loss,提出ArcFace,在MegaFace上獲得了state-of-the-art精度。
loss的演變歷程:
2. 從Softmax到ArcFace
2.1 Softmax:
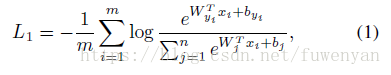
Softmax並沒有明確的將特徵優化成正樣本能夠有更高的相似度,負樣本能夠有更低的相似度,也就是說並沒有擴大決策邊界。
2.2 WeightsNormalisation
權重歸一化之後,loss也就只跟特徵向量和權重之間的角度有關了


在Sphereface論文中表明,權值歸一化至提高了一點點效果。
2.3 MultiplicativeAngular Margin
Sphereface中,角度擴大m倍
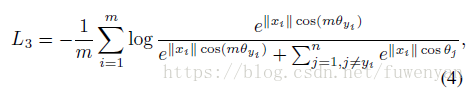
由於cosine不是單調的,所以用了個策略給轉成單調的
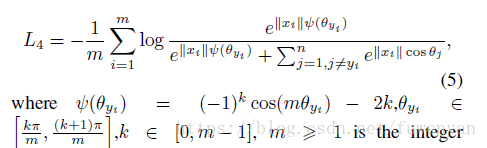
訓練的時候加入了softmax幫助收斂,引入了一個引數lamda實際上
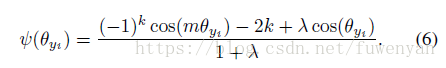
可是這個引數的引入讓訓練變的複雜微妙起來。
2.4 FeatureNormalisation
特徵和權重正則化消除了徑向變化並且讓每個特徵都分佈在超球面上,本文將特徵超球面半徑設為s=64,正則化為64,sphereface的loss變為:
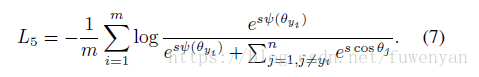
2.5 Additive Cosine Margin
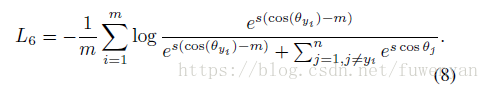
本文把m設為0.35. 與sphereface相比,cosine-face有三個好處:(1)沒有超引數簡單易實現,(2)清晰且不用softmax監督也能收斂,(3)效能明顯提升
2.6 Additive AngularMargin
Cos(theta + m)
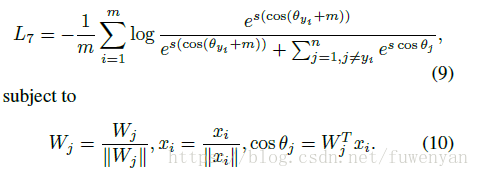
這下margin隨著theta的變化也是動態變化的。
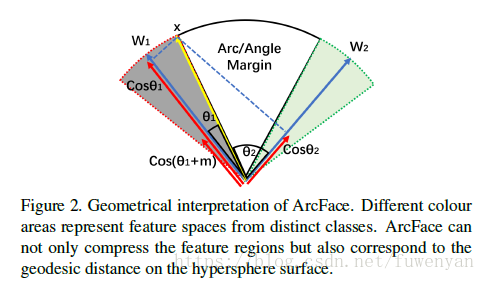
2.7 Comparison underBinary Case

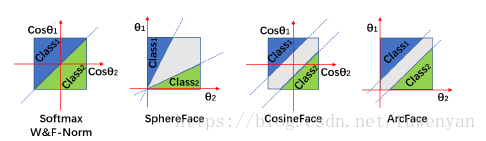
2.8 Target Logit Analysis
這裡對Sphereface,consineFace和arcFace為何能提升效能進行分析。使用LResNet34E-IR模型和MS1M dataset進行分析。
先看a圖
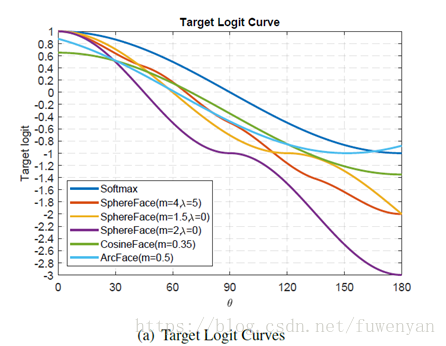
稍微降低softmax的Target Logit夠提升效能同時也提高了訓練難度,不過降低太多會導致訓練發散。也就是為什麼sphereface 在m =2 和lambda =0的情況下訓練發散。
再看c圖
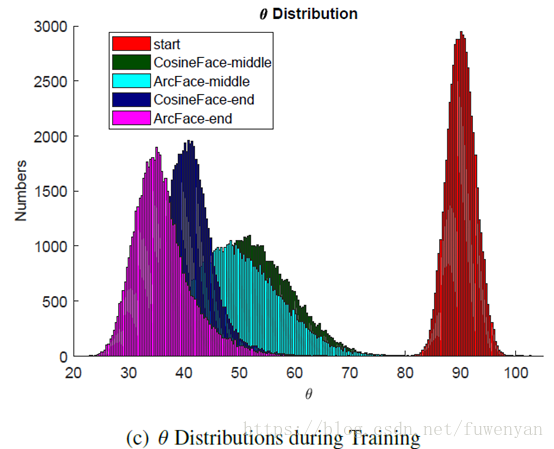
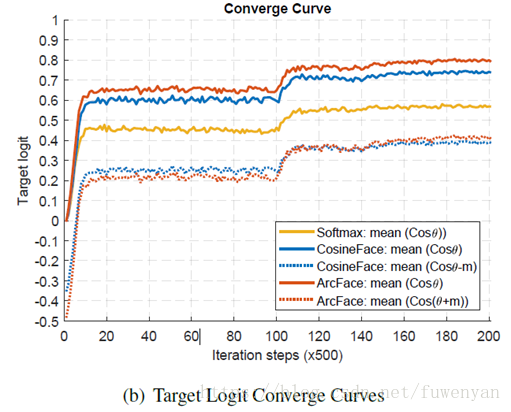
theta的變化時從訓練開始的90度左右最終慢慢變為三四十度。對照圖a,在30~90度之間,ArcFace曲線更低,也就是說在這個區間,ArcFace對margin的懲罰比consineFace更大。所以到最後ArcFace收斂的角度區間位置比ConsineFace更小,也就是說收斂的更好一些(圖c),從b也能看出訓練之初,arcFace懲罰更大,訓練後期ArcFace懲罰又比consineFace更小,也就是說收斂的更好。
在圖c可以看出收斂後,theta基本都小於60度,超出60度的基本都是困難樣本或者噪聲樣本。雖然從a中看在theta<30度時,consineFace懲罰力度更大,但是直到訓練後期這部分也很少,所以也沒什麼用。
所以從曲線上來說,在30~60度區間上,增加懲罰邊界能夠提升精度,因為這部分與最有效的一般困難的樣本有關,多懲罰一下這種的,有助於提升精度,但懲罰太多會導致發散。這也就是為什麼效能從Softmax, SphereFace, CosineFace 到 ArcFace逐步提升。
3. 實驗
3.1.1 訓練資料
VGG2: 訓練集--8631人314 1890張圖片;測試集—500人16 9396張圖片,姿態,年齡,光照,種族,職業跨度大。質量較高的資料集。直接使用。
MS-Celeb-1M: 原始包含10萬人1000萬圖片。
清洗方式:獲取每個人的身份質心,將每個人的圖片按照距離質心的距離進行排序。距離質心過遠的圖片自動移除。然後人工確認在距離閾值邊緣的圖片,最終剩下的資料集包含85000人的380萬圖片。清晰資料結果公開。
3.1.2 驗證資料
LFW:包含5749人的13233張圖片,姿態表情和光照變化較大,6000face pairs上驗證
CFP:500人,每人10張正面和4張側面圖片。測試包含正面-正面和正面-側面驗證,10個資料夾包含350人same personpairs和350different person pairs。本文只使用了較有挑戰性的CFP-FP驗證組。
AgeDB:這是自然環境下具有較大姿態,表情,光照和年齡變化的資料集。440人12240張圖片,年齡範圍3到101歲,標註有身份性別和年齡。本文使用的是AgeDB-30.包含300正樣本對和300負樣本對。
3.1.3 測試資料
MegaFace: 開源的最大測試基準,百萬級別的測試分佈。
Gallery set:69萬人超過100萬張圖片,有噪聲
Probe set:FaceScrub和FGNet
FaceScrub包含530人的10萬張圖片,其中55742張男性圖片,52076張女性圖片。有噪聲
FGNet是年齡資料及,有82人的1002張圖片。每人都有跨越年齡的多張人臉。
清洗FaceScrub:
獲取每個人的身份質心,將每個人的圖片按照距離質心的距離進行排序。然後人工排查,共找出605張噪聲圖片。測試階段,將噪聲圖片進行了替換,識別精度提升了1%。
清洗MegaFace
人工清洗,找到707張噪聲圖片片,測試階段,增加了一個額外的特徵維度來區分這些噪聲臉,識別精度提高15%。
清洗結果公開
3.2 網路設定
使用MxNet架構。
首先使用VGG2作為訓練資料softmax作為損失函式驗證了各種不同的網路設定。
Batch size 512
4or8塊NVIDIA tesla P40(24G)GPU
學習率起始0.1,在100k, 140k和160k時分別縮小10倍
總iters 200K
Momentum0.9
Weight decay 5e-4
3.2.1 輸入設定
採用5個關鍵點校準人臉並resize到112*112 RGB,歸一化到-1~1
因為很多卷積網路都是為ImageNet分類任務設定的,那個輸入是224*224,而本文的輸入是112*112,所以為了保證特徵圖的解析度,本文將conv7*7stride2替換為conv3*3 stride1.
這樣最後卷積的輸出是7*7
3.2.2 輸出設定
在最後的幾層,使用不同的策略來調查特徵嵌入設定如何影響模型的表現。
Option-A:使用Global pooling(GP)
Option-B:在GP後使用一個全連線
Option-C:在GP後使用FC+batch normalization
Option-D:使用在GP後使用FC-BN-PRELU
Option-E: 最後一個卷積層後+BN-Dropout-FC-BN
除A外,其餘特徵維度都是512,A的維度由卷積層輸出size決定。
3.2.3 Block setting
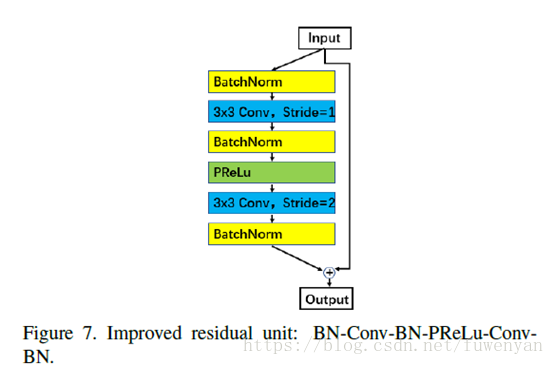
使用了改進的殘差網路結構。
3.2.4 Backbones
網路主幹使用了當前較為流行的一些模型
MobileNet
Inception-Resnet-V2
DenseNet
SEnet
DPN
比較了這些網路在精度速度和模型size上的區別。
3.2.5 網路設定總結
Input selects L.
第一層convLayer 卷積核為3*3stride1時,網路輸出7*7;卷積核為7*7stride2時,網路輸出3*3
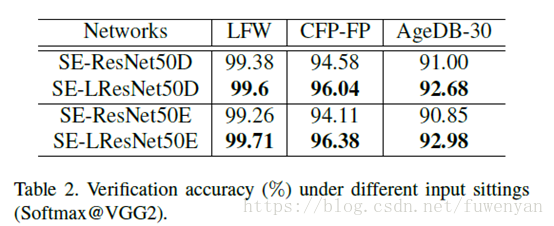
通過比較發現,輸出特徵圖維度大的效能更好一些,所以還是選擇卷積核為3*3stride1。
Output selects E.
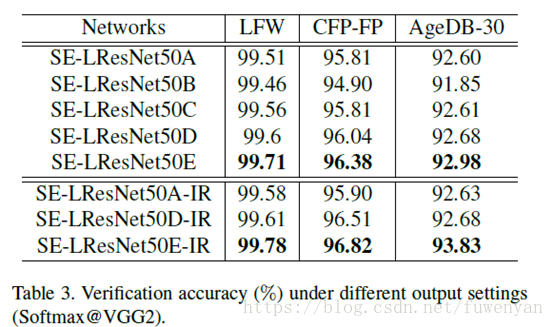
通過對比發現Option-E的輸出方案能夠獲得最好的效果。Dropout引數設定為0.4,有效避免過擬合併且獲得較好的泛化能力。
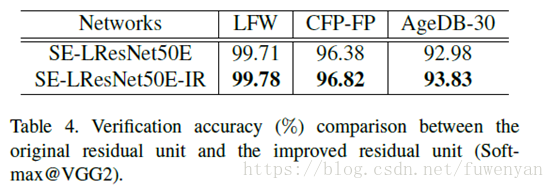
Block selects IR.
BN-Conv(stride=1)-BN-PReLu-Conv(stride=2)-BN這個結構能夠獲得更高的精度。
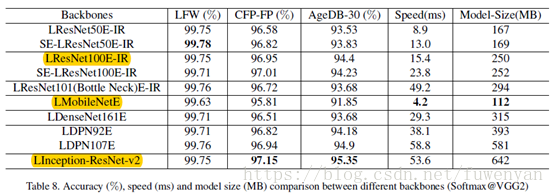
Backbones Comparisons
速度在P40 GPU上測的,
Inception-Resnet-V2 network obtains the best performance with long runningtime (53:6ms) and largest model size (642MB).
MobileNet can finish face feature embedding within 4:2ms with a model of 112MB, and the performance only dropsslightly.
綜合考慮速度和精度,LResNet100E-IR較為理想。本文就是用這個在MegaFace上測試的。
3.3 LOSS setting
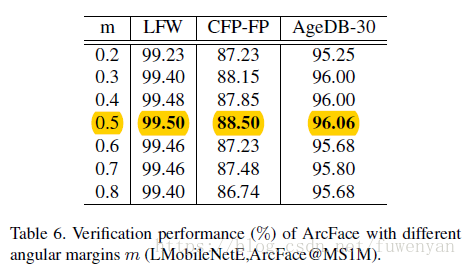
由於引數m對決策邊界有重要影響,因此先分析找出最佳m
使用LMobileNetE+arcFace loss在refined MS1M資料集上訓練,m從0.2到0.8變化。0.5最優,選擇0.5.
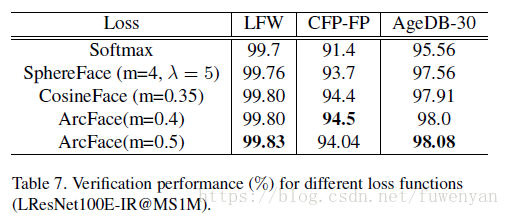
基於LResNet100E-IR和refined MS1M資料集,比較了不同的loss函式對精度的影響。
結論(1)與Softmax和Sphereface相比,cosine face和ArcFace在較大的姿態和年齡變化時,精度明顯提升。(2)CosineFace和ArcFace比SphereFace更易實現,不需要softmax的輔助就能很容易的收斂,而對於sphereface,softmax的輔助是必不可少的。(3) ArcFace比consineFace略微好一丁點,不過ArcFace更為直觀並且在超球面維度上有更清晰的解釋。
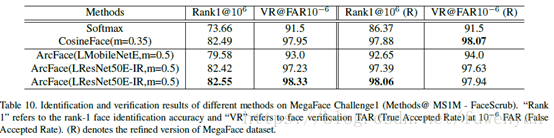
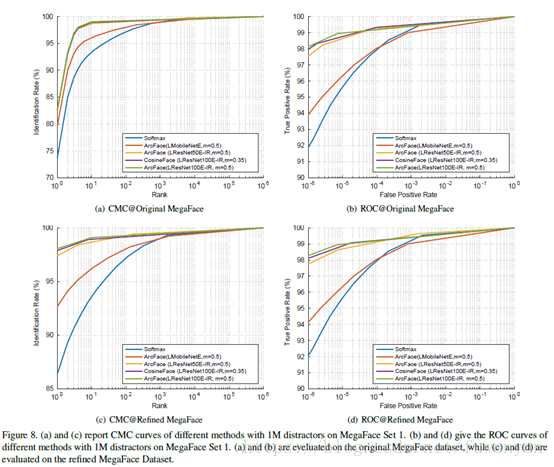
3.4. MegaFace Challenge1 on FaceScrub
LResNet100E-IR network and the refined MS1M dataset
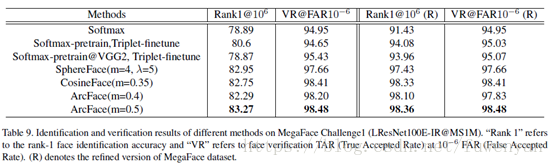
MS1M和FaceScrub重複的人剔除,分別計算兩個庫中每個人的特徵質心,578箇中心距離小於0.45的人,然後將這578人再MS1M中移除。重新比對結果
3.5 Further Improvement by Triplet Loss
受限於GPU記憶體,基於softmax的方法訓練困難。一個較為實用的解決方案是使用度量學習的方法,較為常用的是triplet loss,不過triplet loss的收斂速度比較慢,所以本文使用triplet loss微調現有的人臉識別模型。
Finetuning時,本文使用LResNet100EIR模型,lr設為0.005, momentum為0, weight decay 5e-4.
用AgeDB-30驗證,發現(1)用較少人數訓練的Softmax然後用較多人數的資料集通過triple loss finetuning後精度明顯提升,同時也說明了2步訓練機制的有效性,訓練速度比直接訓練tripletloss快很多;(2)通過在同樣的資料集上triplet finetuning也能提升精度,說明區域性的提升有助於全域性模型的提升;(3)區域性度量學習的方法可以補充全域性超球面度量學習的方法。
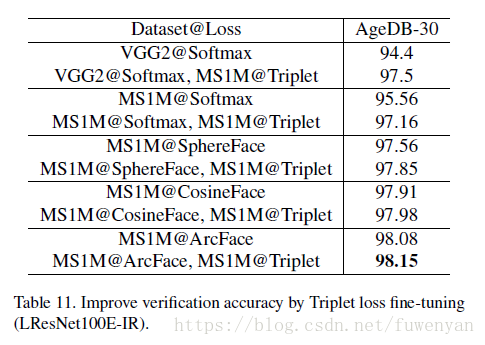
由於tripletloss 的margin是歐氏距離,之後作者會繼續研究基於角度margin的triplet loss。