
Python爬蟲爬取部落格園作業
阿新 • • 發佈:2018-11-23
要求
第一部分:
請分析作業頁面,爬取已提交作業資訊,並生成已提交作業名單,儲存為英文逗號分隔的csv檔案。檔名為:hwlist.csv 。 檔案內容範例如下形式: 學號,姓名,作業標題,作業提交時間,作業URL 20194010101,張三,羊車門作業,2018-11-13 23:47:36.8, http://www.cnblogs.com/sninius/p/12345678.html第二部分:
在生成的 hwlist.csv 檔案的同文件夾下,建立一個名為 hwFolder 資料夾,為每一個已提交作業的同學,新建一個以該生學號命名的資料夾,將其作業網頁爬去下來,並將該網頁檔案存以學生學號為名,“.html”為副檔名放在該生學號資料夾中。正題
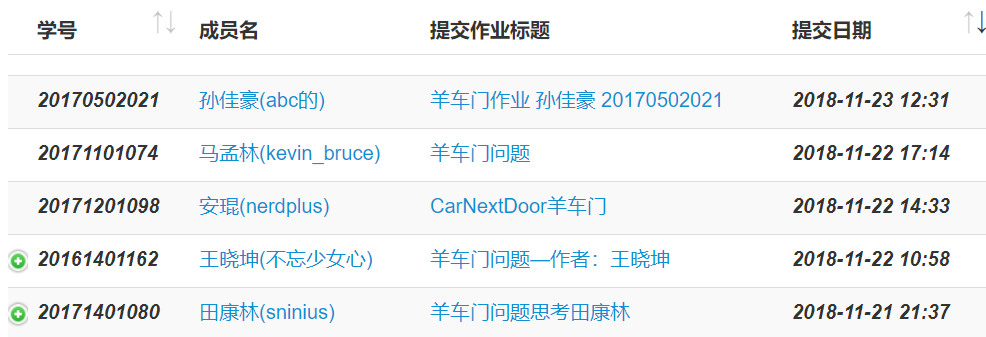
分析一下他們的程式碼,我在瀏覽器中對應位置右鍵,然後點選檢查元素,可以找到對應部分的程式碼。但是,直接檢視當前網頁的原始碼發現,裡面並沒有對應的程式碼。我猜測這裡是根據伺服器上的資料動態生成的這部分程式碼,所以我們需要找到資料檔案,以便向伺服器申請,得到這部分資源。

在剛才檢視元素的地方接著找資料檔案,在Network裡面的檔案中很順利的就找到了,並在報文中拿到了URL和請求方法。
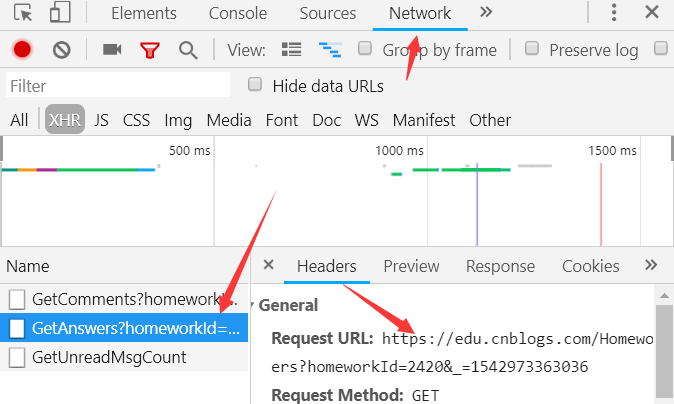
檢視一下這個檔案發現是JSON檔案,那樣的話難度就又降低了,因為Python中有json庫,解析json的能力很強。可以直接將json轉換為字典和列表型別。

這時候我們爬取需要的資訊的準備工作可以說是結束了,我們拿到了資料的URL,並且知道了資料型別。於是,我們只需要用requests庫爬一下這個頁面,然後用json解析一下,並且篩選有用的資訊就好了。
(沒用到BeautifulSoup和re庫有點小失落)
接下來就是建立檔案,就沒有什麼難度了。只是在每個學生建立檔案的時候注意一下,建立好以後及時的回到上層目錄,否則,可能會讓檔案一層層的巢狀下去。
程式碼
# -*- coding:utf-8 -*- import requests import json import os #抓取頁面 url = 'https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1542959851766' try: r = requests.get(url,timeout=20) r.raise_for_status() r.encoding = r.apparent_encoding except: print('網路異常,請重試') #利用json拿到資料列表,每個列表元素都是字典 datas = json.loads(r.text)['data'] result = "" #資料處理 for data in datas: result += data['StudentNo']+','+data['RealName']+','+data['DateAdded']+','+data['Title']+','+data['Url']+'\n' #寫入檔案 with open('hwlist.csv','w') as f: f.write(result) #建立資料夾hwFolder os.mkdir('hwFolder') os.chdir('hwFolder') #建立每個學生的作業檔案 for data in datas: #建立目錄 os.mkdir(data['StudentNo']) os.chdir(data['StudentNo']) #抓取頁面 try: webmsg = requests.get(data['Url'],timeout=20) webmsg.raise_for_status() webmsg.encoding = webmsg.apparent_encoding except: print('網路異常,請重試') #儲存抓到的頁面 with open(data['StudentNo']+'.html','wb') as f: f.write(webmsg.content) os.chdir(os.path.pardir)
結果展示

上圖是hwlist.csv檔案的部分結果(Excel下開啟)

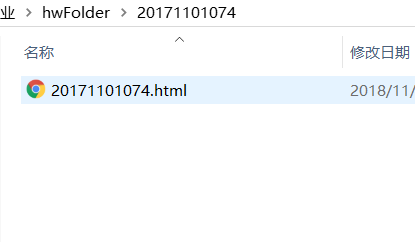
以上是為每個學生建立的檔案和資料夾的結果,讓我開啟一個HTML檔案進行檢視,看看爬取的成果:

爬到的內容是沒有問題的,只是一些圖片和排版不太正確。這是因為我只爬取了HTML頁面,沒有爬取圖片等資源的結果,後續如果有機會我會一併爬取整個頁面的所有資源。