
Scrapy爬取部落格園精華區內容
阿新 • • 發佈:2018-11-30
程式爬取目標
獲取部落格園精華區文章的標題、標題連結、作者、作者部落格主頁連結、摘要、釋出時間、評論數、閱讀數和推薦數,並存儲到MongoDB中。
程式環境
- 已安裝scrapy
- 已安裝MongoDB
建立工程
scrapy startproject cnblogs在命令提示符中執行上述命令後,會建立一個名為cnblogs的資料夾。
建立爬蟲檔案
cd cnblogs
scrapy genspider cn cnblogs.com執行上述命令後,會在cnblogs\spiders\下新建一個名為cn.py的爬蟲檔案,cnblogs.com為允許爬取的域名。
編寫items.py檔案
定義需要爬取的內容。
import scrapy class CnblogsItem(scrapy.Item): # define the fields for your item here like: post_author = scrapy.Field() #釋出作者 author_link = scrapy.Field() #作者部落格主頁連結 post_date = scrapy.Field() #釋出時間 digg_num = scrapy.Field() #推薦數 title = scrapy.Field() #標題 title_link = scrapy.Field() #標題連結 item_summary = scrapy.Field() #摘要 comment_num = scrapy.Field() #評論數 view_num = scrapy.Field() #閱讀數
編寫爬蟲檔案cn.py
import scrapy from cnblogs.items import CnblogsItem class CnSpider(scrapy.Spider): name = 'cn' allowed_domains = ['cnblogs.com'] start_urls = ['https://www.cnblogs.com/pick/'] def parse(self, response): div_list = response.xpath("//div[@id='post_list']/div") for div in div_list: item = CnblogsItem() item["post_author"] = div.xpath(".//div[@class='post_item_foot']/a/text()").extract_first() item["author_link"] = div.xpath(".//div[@class='post_item_foot']/a/@href").extract_first() item["post_date"] = div.xpath(".//div[@class='post_item_foot']/text()").extract() item["comment_num"] = div.xpath(".//span[@class='article_comment']/a/text()").extract_first() item["view_num"] = div.xpath(".//span[@class='article_view']/a/text()").extract_first() item["title"] = div.xpath(".//h3/a/text()").extract_first() item["title_link"] = div.xpath(".//h3/a/@href").extract_first() item["item_summary"] = div.xpath(".//p[@class='post_item_summary']/text()").extract() item["digg_num"] = div.xpath(".//span[@class='diggnum']/text()").extract_first() yield item next_url = response.xpath(".//a[text()='Next >']/@href").extract_first() if next_url is not None: next_url = "https://www.cnblogs.com" + next_url yield scrapy.Request( next_url, callback=self.parse )
編寫pipelines.py檔案
對抓取到的資料進行簡單處理,去除無效的字串,並儲存到MongoDB中。
from pymongo import MongoClient
import re
client = MongoClient()
collection = client["test"]["cnblogs"]
class CnblogsPipeline(object):
def process_item(self, item, spider):
item["post_date"] = self.process_string_list(item["post_date"])
item["comment_num"] = self.process_string(item["comment_num"])
item["item_summary"] = self.process_string_list(item["item_summary"])
print(item)
collection.insert(dict(item))
return item
def process_string(self,content_string):
if content_string is not None:
content_string = re.sub(" |\s","",content_string)
return content_string
def process_string_list(self,string_list):
if string_list is not None:
string_list = [re.sub(" |\s","",i) for i in string_list]
string_list = [i for i in string_list if len(i) > 0][0]
return string_list修改settings.py檔案
新增USER_AGENT
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'啟用pipelines
ITEM_PIPELINES = {
'cnblogs.pipelines.CnblogsPipeline': 300,
}執行程式
執行下面的命令,開始執行程式。
scrapy crawl cn程式執行結果
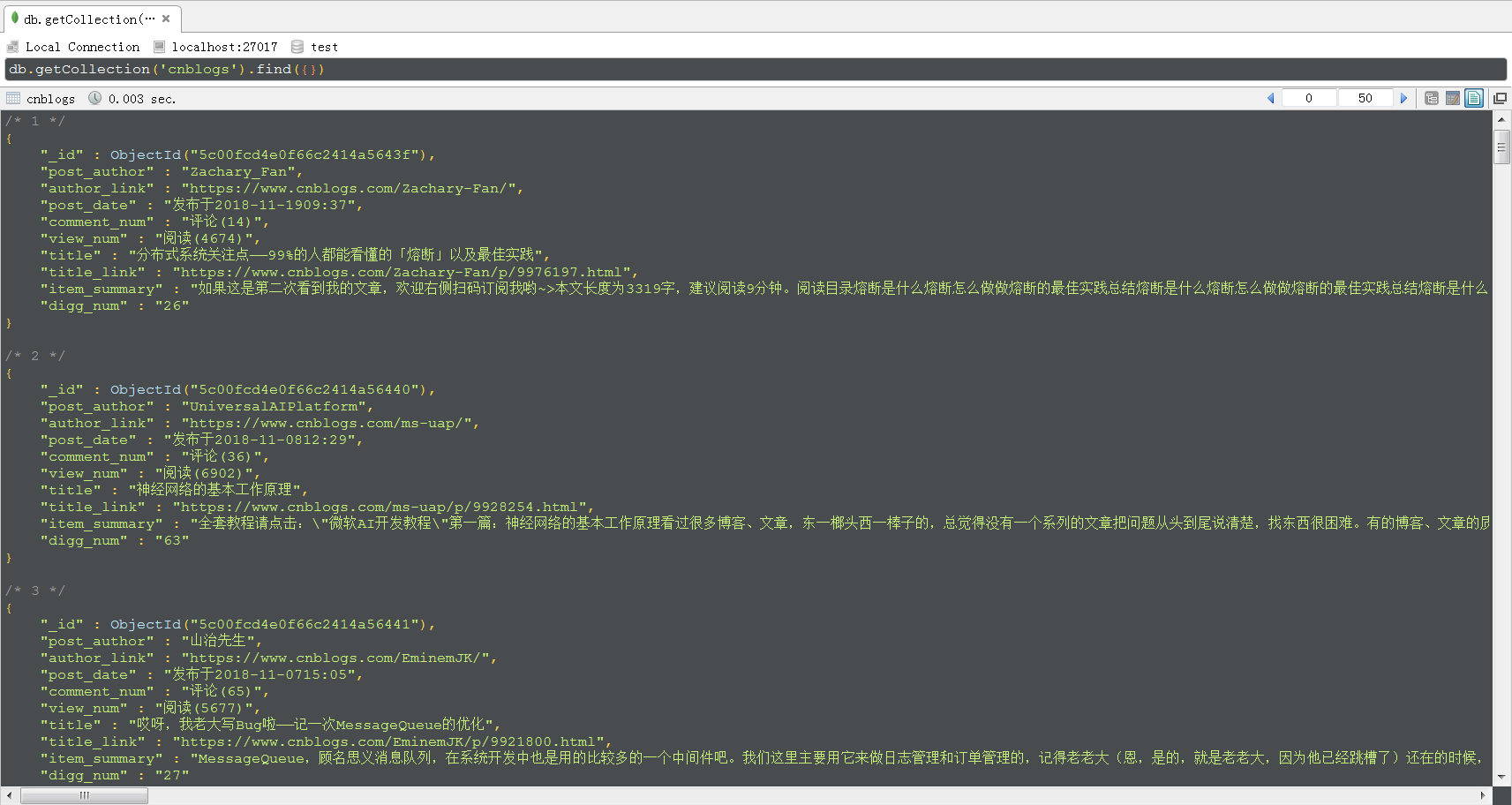
程式執行結束後,MongoDB中的資料如下圖所示,採用的視覺化工具是Robo 3T。
感謝大家的閱讀,如果文中有不正確的地方,希望大家指出,我會積極地學習、改正。
再次感謝您耐心的讀完本篇文章。