
編寫windows服務 定時爬取部落格園文章 郵件提醒以及入庫
這段時間工作比較忙,每天也沒那麼多的時間逛部落格園看文章,於是就想寫一個工具 每天早上9點爬取文章給自己發郵件
作為每天的技術早餐。
相對而言,爬取部落格園的文章還是比較簡單的,主要思路就是分析部落格園文章列表的分頁,請求方式,頁面渲染方式等,
寫篇隨筆簡單share一下。
這個小工具主要用到的由nlog、HtmlAgilityPack、ef、quartz.net 。
首先就是分析文章列表以及分頁,當對文章列表切換頁碼的時候,
url是這種形式: https://www.cnblogs.com/#p3
p1 p2 p3 ...p(n) 剛開始我也是以為列表分頁是靠這種形式走的,在url中傳頁碼引數,用.net 的httpclient請求了幾十頁,
發現返回內容都是一樣的,這是一個坑,接著分析,F12分析一下,切換頁碼的時候發現是一個post請求,
請求地址為:
https://www.cnblogs.com/mvc/AggSite/PostList.aspx

分析下請求引數,
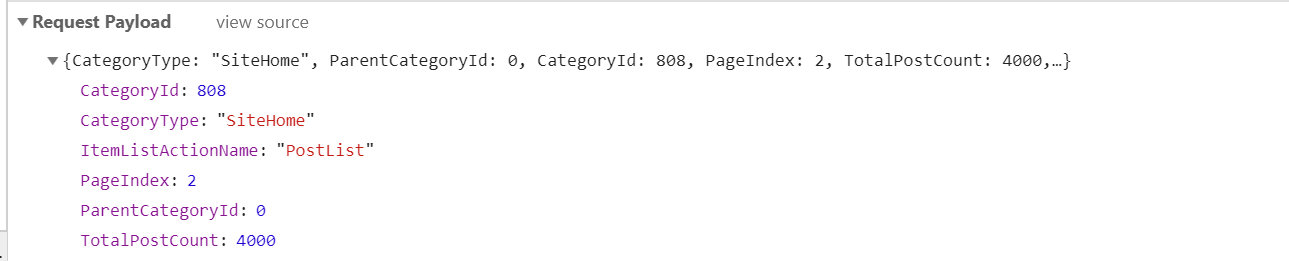
CategoryId、CategoryType、ItemListActionName、PageIndex、ParentCategoryId、TotalPostCount
對每個引數的具體意義不做過多分析,pageindex就是頁碼,因此文章列表在分頁的時候,請求地址為
https://www.cnblogs.com/mvc/AggSite/PostList.aspx
傳遞引數如:{"CategoryType":"SiteHome","ParentCategoryId":0,"CategoryId":808,"PageIndex":4,"TotalPostCount":4000,"ItemListActionName":"PostList"}
按照此地址以及引數請求一下,確定能夠返回期望結果,讓人不舒服的地方又來了,返回結果非json 而是當前頁面的html 。

至此,分頁請求方式已經解決了,下一步就是處理請求結果,獲取請求頁的文章列表內容。
因為返回結果是html 我們首先看下文章列表頁:
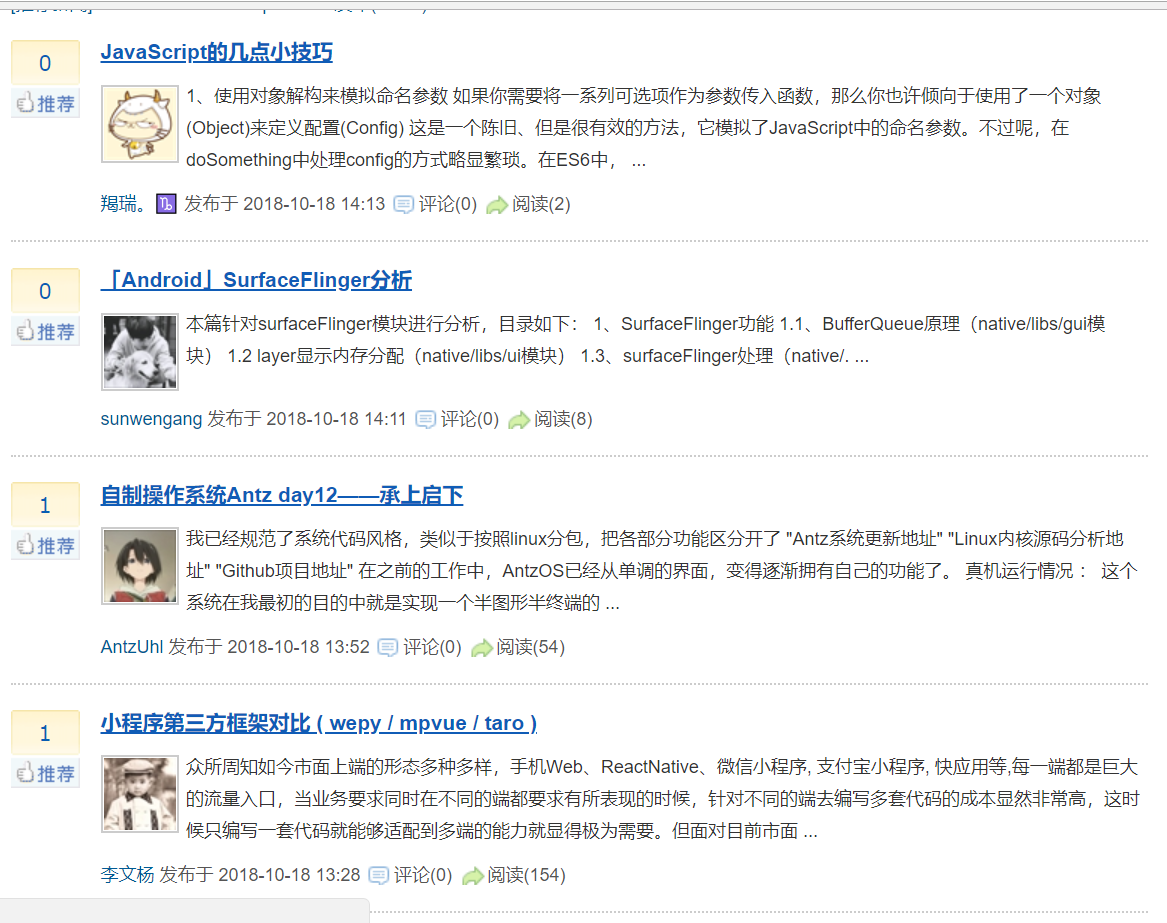
在此列表內,我們能獲取到的資訊 有標題、作者、釋出 時間、摘要,一般爬蟲返回結果為json、html、xml等
部落格園返回結果為html,我們可以通過正則表示式去處理,Regex,也可以通過xpath去處理,因為返回結果就是一個html dom樹,
我們可以通過xpath語法去處理 http://www.w3school.com.cn/xpath/xpath_syntax.asp
同時,我們也可以F12 Elements選項下 選擇對應文章標題 右鍵copy xpath
比如某一標題的xpath為 //*[@id="post_list"]/div[1]/div[2]/h3/a
相應的c#中 可以使用HtmlAgilityPack 這個工具來進行解析,程式碼如下:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html);
HtmlNodeCollection postItems = i == 1 ? htmlDocument.DocumentNode.SelectNodes("//*[@id='post_list']/*") : htmlDocument.DocumentNode.SelectNodes("./div");
foreach (HtmlNode item in postItems)
{
var titleNode = item.SelectSingleNode("./*/h3");
var footNode = item.SelectSingleNode("./*/div[@class='post_item_foot']");
if (Articles.Any(c => c.Title == titleNode.InnerText)) continue; Articles.Add(new Article { Title = titleNode.InnerText, ItemUrl = titleNode.FirstChild.Attributes["href"].Value, Sumary = item.SelectSingleNode("./*/p").InnerText, Author = footNode.SelectSingleNode("./a").InnerText, PubDate = footNode.SelectSingleNode("./text()[2]").InnerText.Replace("釋出於", "").Trim() }); }
其中的html就是當前列表的html內容,程式碼可自行寫。Article為自定義的實體類
到這一步,文章的簡單資訊獲取到了 url 標題 作者 釋出時間 摘要
下一步就是獲取文章的內容
比如某一文章的url為,https://www.cnblogs.com/senlinmu/p/9805684.html
文章詳情仍然採用HtmlAgilityPack
Articles.ForEach(v =>
{
string html = client.GetStringAsync(v.ItemUrl).Result;
htmlDocument.LoadHtml(html);
HtmlNode htmlNode = htmlDocument.DocumentNode.SelectSingleNode("//*[@id='cnblogs_post_body']");
v.Content = htmlNode?.InnerHtml;
});
html為文章詳情,此xpath為 //*[@id='cnblogs_post_body']
至此,文章的標題、時間、摘要、內容獲取完畢。
然後就可給自己發郵件提醒。
獲取內容大致完成,下一步就是部署成windows服務 ,