
機器學習——線性判別分析
文章目錄
什麼是線性判別分析
引自周志華老師的《機器學習》
線性判別分析是一種經典的線性學習方法,給定訓練樣例集,設法將樣例投影到一條直線上,使得同類樣例的投影點儘可能的近,異類樣例的投影點儘可能原,在對新樣本進行分類時,將其投影到同樣的這條直線上,在根據投影點的位置來確定新樣本的類別
一個直觀的例子: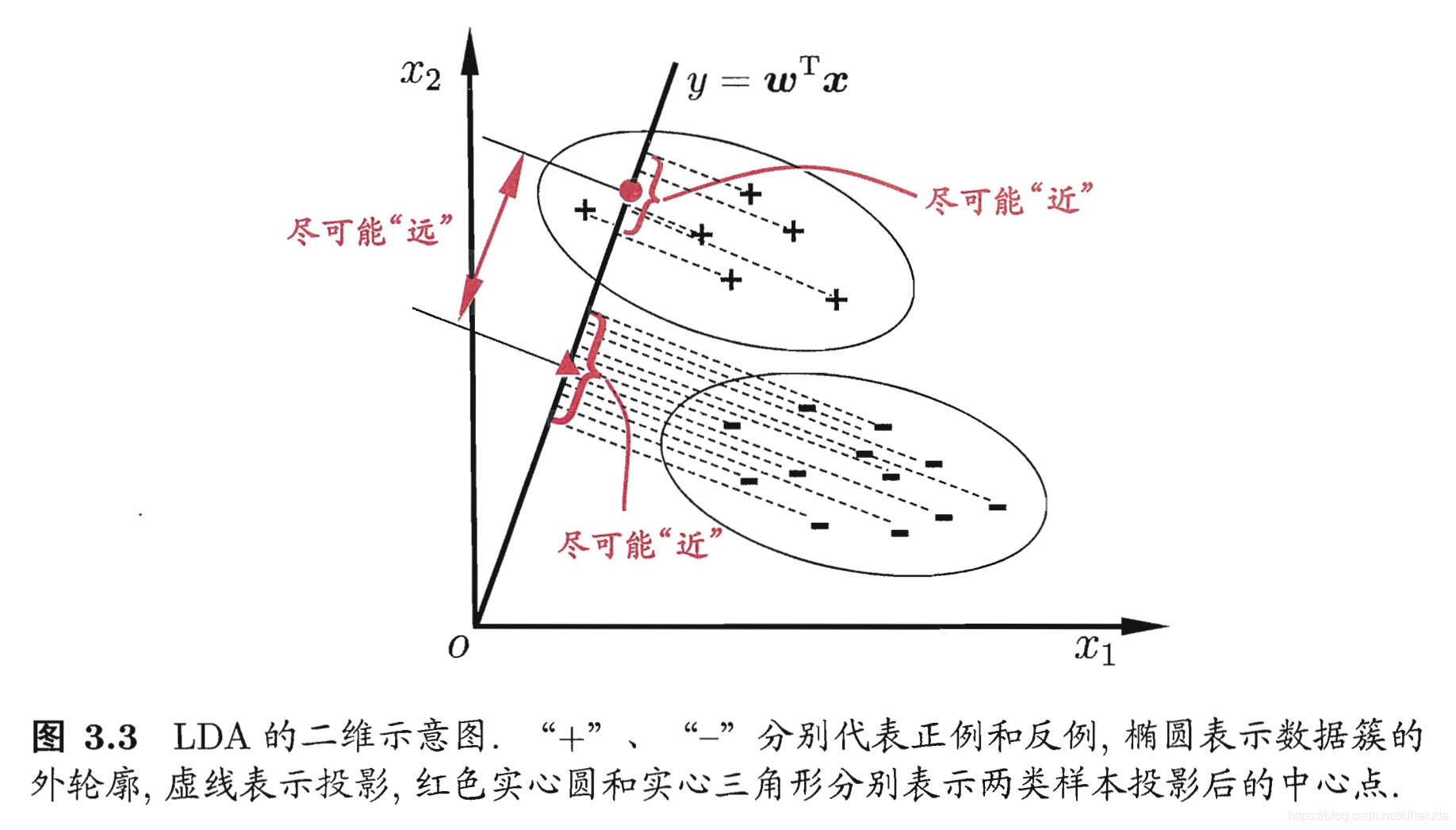
線性判別分析的作用
1、分類
2、降維,其將高維空間的點對映到一條直線上,用一個實數來表示高維空間的點
基本思想
線性判別分析具有兩個關鍵點
- 1、投影后,不同類別的點儘可能遠離
- 2、投影后,相同類別的點儘可能靠近
對於關鍵點1,我們可以使用投影后,不同類別的中心點之間的距離來衡量,中心點距離越遠,類別之間的區分度越高
對於關鍵點2,我們可以使用方差來衡量投影后同類別點之間的散亂程度(方差的統計意義便是衡量點與點之間的散亂程度),方差越小,投影后同類別的資料之間越靠近
如何將點投影到直線上
周志華老師的《機器學習》一書並沒有明顯說明如何將點投影到直線上,那麼我們如何用式子去刻畫點投影到直線這個動作呢?即如何尋找到一個式子,使其幾何意義表示將點投影到某個直線上
我們來看看維基百科對於線性迴歸的定義 我是連結:
線性判別分析 (LDA)是對費舍爾的線性鑑別方法的歸納,這種方法使用統計學,模式識別和機器學習方法,試圖找到兩類物體或事件的特徵的一個線性組合,以能夠特徵化或區分它們
關鍵點在於LDA試圖通過特徵的線性組合來特徵化或區分它們,若特徵為( , ,…, ),那麼LDA的輸出應該是
y= + +…+ (式1.0)
問題是,這個式子的幾何意義是什麼?
令
=(
,
,…,
),x=(
,
,…,
),則式1.0可重寫為
y= (式1.1)
式1.1可看成是向量
與向量
的點乘,我們知道向量點乘可以寫成:
=|
||
|cos
,其幾何意義為向量
在向量
方向的投影長度的|
|倍,那麼投影的直線便確定了,即向量
所在方向的直線,但是線性判別分析是將訓練集樣例投影到直線上,但是式1.1是投影后在乘以|
|倍,是不是與線性判別分析的思想有出入呢?其實沒有,因為對於所有的樣例,式1.1都對其在
方向的投影放大了|
|倍,不會改變投影后樣例之間的相對位置,而線性判別的關鍵點只關心投影后點與點之間的相對位置關係,式1.1並不會破壞這個關係
二分類線性判別分析
接下來的任務就是如何使用式1.1去刻畫上述兩個關鍵點,即利用式1.1推出一個式子,其幾何意義為這兩個關鍵點,假設我們現有一個問題——判斷一個工廠生產的零件是不是好零件,一個零件只有好和壞之分,因此這是一個二分類問題,設一個零件具有d個特徵,我們用這d個特徵去描述這些零件,現假設我們有一批樣本資料,其中,好零件的樣本為( , ,…, ),( , ,…, ),…,( , ,…, ),壞零件的樣本為( , ,…, ),( , ,…, ),…,( , ,…, )
如何刻畫類別的中心點之間的距離
即如何刻畫投影后的中心點(均值),我們先求出投影前的均值向量
好零件的均值向量
為
( , ,…,