
機器學習 (十四)輕鬆理解模型評價指標
篇首語
相信大家都知道下面的圖片是啥意思,每個無論在啥公司、無論哪個行業都有自己的KPI評價指標,公司會根據公司情況設定公司戰略KPI、部門KPI、以及每個人的指標,對於員工也是比較關心自己的KPI因為關係著你能拿多少年終獎,公司處在不同發展階段相應的評價指標細則也會有所區別。

正如我們的學習模型,在設計階段、部署階段等都有每個階段的衡量指標,下面讓我們來看看究竟有哪些指標。
模型評估指標
模型評估其實在各行各業都有自己的評價標準,相當於對一件事情結果好壞的評價,假如沒有評價標準那麼如何來區分好與壞呢,在學校中評價學生的一個重要指標是學習成績、在醫學中有紅細胞數量、血小板數量等指標來分析一個人的健康狀況、衡量網站響應速度有TPS等,由此看來,機器學習模型也有自己的評價標準,下圖是我畫的常見的評價指標:

不同的書籍中對各個指標翻譯的中文可能稍有區別,乾脆還不如直接寫英文,也顯得高大上點。
指標分析
分類
資料集
這個資料集是訓練資料集,咱們把它分為訓練集和驗證集兩部分。
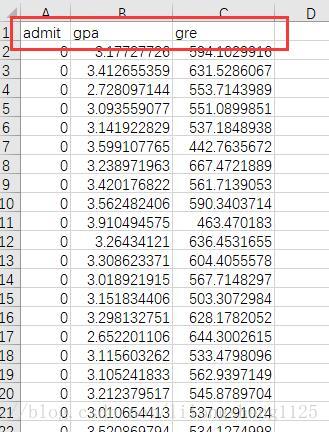
資料集說明 在這個資料集中有三列資料 admit 表示目標列 意思是提交是否通過,gpa(grade point average)平均績點值是表示學生平時學習成績的一種表示方法,中國一般是100分制,60分及格,如果轉化為gpa評分值 ,大概0-60 為0,60-70為1,70-80為2,80-90為3,90-100為4;gre(Graduate Record Examination) 稱為美國研究生入學考試,看資料集中資料這麼大應該是2011年以前的算分方法,在2011年以後改革了分值計算,數學177分、語文166分,改前為800分標準。
其實理解了每個欄位含義也就大概懂了這兩個欄位和目標變數的關係,可見對資料的認識很重要,這讓我想起了 資料和特徵決定了機器學習的上限,而模型和演算法只是逼近這個上限而已。
程式碼
首先引入sklearn庫 並且匯入資料
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
admissions = pd.read 有了訓練資料之後就可以訓練模型了,在實際專案中不會直接有這麼好的資料,中間過程需要對資料格式處理,由於資料是處理好的就都省略了,一般情況下特徵還需要自己去尋找,並不能這麼輕鬆獲得,為簡單計算只把我們資料拆分為訓練集和驗證集,邏輯迴歸模型訓練訓練集樣本。
model = LogisticRegression()
# 訓練模型
model.fit(train_set[["gpa"]], train_set["admit"])
labels = model.predict(test_set[["gpa"]])
print labels
# 新增一列預測結果
test_set['predicted_label'] = labels
print test_set['predicted_label'].value_counts()
# 新增一個目標列
test_set['actual_label'] = test_set['admit']
# 預測正確的樣本情況
matches = test_set['actual_label'] == test_set['predicted_label']
# 預測正確的樣本個數
correct_predictions = test_set[matches]
# 準確率計算
accuracy = len(correct_predictions) / float(len(test_set))
print "提交稽核通過的準確率accuracy = %s" % (accuracy)
提交稽核通過的準確率accuracy = 0.645833333333接下來有預測模型和結果了,我們可以開始計算各個樣本預測情況,通常用一個2*2的混淆矩陣來表示,當然對於多類別預測也是通用的,可以非A即其它類別,A為正,其它為負。
true_positive_filter = (test_set['actual_label']==1) & (test_set['predicted_label'] == 1)
true_positives = len(test_set[true_positive_filter])
print "TP = %s" % true_positives
true_nagative_filter = (test_set['actual_label']==0) & (test_set['predicted_label'] == 0)
true_nagatives = len(test_set[true_nagative_filter])
print "TN = %s" % true_nagatives
false_nagatives_filter = (test_set['actual_label']==1) & (test_set['predicted_label'] == 0)
false_nagatives = len(test_set[false_nagatives_filter])
print "FN = %s" % false_nagatives
false_positive_filter = (test_set['actual_label']==0) & (test_set['predicted_label'] == 1)
false_positives = len(test_set[false_positive_filter])
print "FP = %s" % false_positives
TP = 10
TN = 83
FN = 42
FP = 9指標計算
邏輯迴歸預測結果,2*2混淆矩陣 如下
| 真實\預測 | 預測(正) | 預測(負) |
|---|---|---|
| 真實(正) | TP(10) | FN(42) |
| 真實(負) | FP(9) | TN(83) |
- accuracy (準確率)= ( TP+TN ) / ( TP+FN+FP+TN ) = (10+83) / (10+83+9+42) = 0.57
- precision (精確率、查詢率) = TP/(TP+FP) = 10 /(10+9)= 0.53
- recall (召回率、查全率) = TP / (TP+FN) = 10 / (10+42) = 0.19
從結果來看 準確率不到60%模型整體效果較差,而召回率還要小說明我們真正想要預測的正類別預測錯了很多,精確率高於召回率說明負類樣本預測對了很多,精確率和召回率唯一不同點即樣本中是否都是真正的正樣本,召回率都是真正的樣本,而精確率含有把負樣本預測為正樣本的情況,他們兩個的大小比較可以說明是把正樣本預測錯了的多還是把負樣本預測錯了的多,這兩個值都是越大越好,越大說明各自預測錯了的越少。
我們來繼續畫ROC 接受者特徵曲線,學習者即我們的學習模型,sklearn有提供好了函式思路是通過預測出來每個樣本屬於哪個類別的概率值,然後不斷調整概率閾值來得到不同的點座標 Ai(TPR, FPR) 的值 , i一般等於樣本個數,將i個座標連線起來即得到ROC曲線,如下程式碼所示:
TPR = TP / (TP+FN) = TP / C(真實)正
FPR = FP / (FP+TN) = FP / C(真實)負
從公式上可以看出來 TPR是把真實正樣本預測對了的概率,即真陽
FPR是把真實負樣本預測錯了的概率即假陽
ROC曲線即以真陽為縱座標,以假陽為橫座標,畫出來一條曲線
from sklearn import metrics
# 樣本屬於0-1分類的概率值 兩列屬於兩類各自的概率
probabilities = model.predict_proba(test_set[["gpa"]])
# 真正例、假正例、概率閾值
fpr, tpr, thresholds = metrics.roc_curve(test_set["actual_label"], probabilities[:,1])
plt.plot(fpr, tpr)
plt.show()ROC曲線
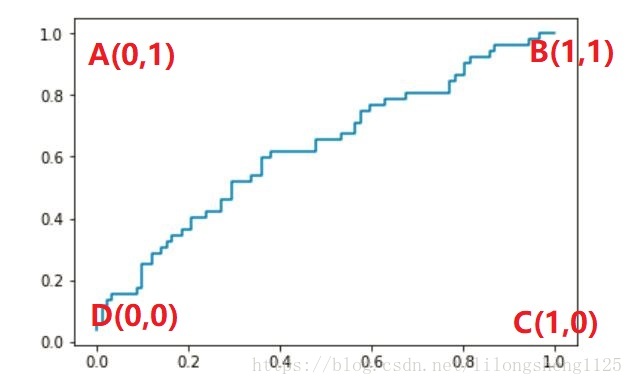
上圖即我們畫出來的曲線,可以看見這條曲線效果並不好,有點接近一條直線了,研究一下圖上幾個特殊點的含義,就會讀懂整個圖,ABCD四點含義留給大家自己思考?
結果是曲線距離A點越近模型效果越好。
AUC 面積
from sklearn.metrics import roc_auc_score
probabilities = model.predict_proba(test_set[["gpa"]])
auc_score = roc_auc_score(test_set["actual_label"], probabilities[:,1])
print(auc_score)
0.627299331104求出來AUC面積為0.627和我們猜想的差不多,還需要繼續優化模型才行。
細節
- np.random.permutation() 與 np.random.shuffle()
# 不改變原有陣列順序permutation
permutation_a = np.arange(12)
print "原始 permutation_a= %s" % permutation_a
permutation_b = np.random.permutation(permutation_a)
print "經permutation處理後permutation_a = %s" % permutation_a
print "經permutation處理後permutation_b = %s" % permutation_b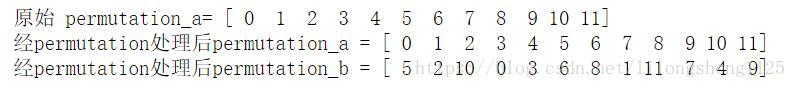
# shuffle 改變原有資料順序
shuffle_a = np.arange(12)
print "shuffle處理前shuffle_a = %s" % shuffle_a
np.random.shuffle(shuffle_a)
print "shuffle處理後shuffle_a = %s" % shuffle_a 列印結果:
shuffle處理前shuffle_a = [ 0 1 2 3 4 5 6 7 8 9 10 11]
shuffle處理後shuffle_a = [ 2 10 0 4 6 5 11 3 9 1 7 8]
- iloc 與 loc
loc在於對pd物件根據索引號是否相等來取出行記錄,而iloc在於從索引為0開始取 每次自增+1 方式 - model.predict_proba 與 model.predict 區別
predict_proba 方法返回每個樣本屬於哪個類別的概率,有時會需要比如畫ROC曲線,predic直接返回樣本屬於哪個類別的結果,具體要根據我們結果來分析。
總結
當然除了分類任務還有迴歸、聚類、推薦等其它很多指標,不再一一闡述,畢竟指標太多學習應用時還需要抓住關鍵點,總結是一個抽象和找共同點的過程,找到共同點編結知識網才不會讓我們忘記,知識不應該是越學習越多,應該將已有的知識變成我們的動力,學的越多動力越足,這樣才能學的快理解深刻。
有時還有些問題沒想太明白,比如L0 L1 L2 正則化函式 同閔可夫斯基距離啥的一樣,他們為什麼能拿過來作為正則化懲罰項,知識之間的關聯關係還需要多多思考。
指標分析完可能發現模型存在的這樣活那樣的問題,一般是過擬合或欠擬合,出現這些問題後要有響應的解決方法,不斷去嘗試終會找到優化模型的方法。和開頭提到的KPI一樣,會以公司的結果不斷調整KPI規則,模型訓練、調優都是一個不斷學習反覆的過程。
題外思考
德國大學與劍橋大學?
在評價一個大學厲害不厲害時經常看大學裡面出來了多少厲害人物,在歷史上德國還是出了很多傑出人物的,像偉大的任務如馬克思、恩格斯都是出自德國,目前大家認為德國最好的大學是慕尼黑大學,不過排名在我們的清華、北大之後,談論起德國大家都會想到德國汽車如賓士、寶馬、大眾等汽車,質量和安全係數都是不錯的,德國的這類次高新行業還是比較發達的,GDP相比其周邊國家也是領先地位,但是其大學沒有周邊國家出名,比如英國劍橋、牛津,究其原因主要有如下幾點:
1.公平性與精英教育的側重
2.大學資金關注少
3.大學制度對於優秀人才的吸引力小