
搜尋中詞權重計算及實踐
隨著網路和資訊科技的飛速發展,網路中的資訊量也呈現爆炸式的增長,那麼快速並且正確從這些海量的資料中獲取正確的資訊成為了現在搜尋引擎技術的核心問題。使用者的輸入通常呈現很大的差異性,這是因為不同的人接受不同的教育、不同的文化,導致在表述同一個問題上面差異很大,那麼對使用者輸入的搜尋詞進行詞條權重的打分是非常有必要的,這對於從使用者輸入的搜尋詞中提取核心詞,或是對搜尋詞返回的文件排序等都是一個非常重要的課題。詞權重特徵是衡量查詢中詞的重要度程度,主要應用於相關性排序。
一、TF-IDF
詞頻-逆文件頻率(term frequency-inverse document frequency,TF-IDF) 的概念被公認為資訊檢索中最重要的發明。在搜尋、文獻分類和其他相關領域有廣泛的應用。TF-IDF是一種統計方法,用以評估一字詞對於一個檔案集或一個語料庫中的其中一份檔案的重要程度。字詞的重要性隨著它在檔案中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降。TF-IDF加權的各種形式常被搜尋引擎應用,作為檔案與使用者查詢之間相關程度的度量或評級。TF-IDF的主要思想是:如果某個詞或短語在一篇文章中出現的頻率TF高,並且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分能力,適合用來分類。TFIDF實際上是:TF * IDF,TF詞頻(Term Frequency),IDF逆向檔案頻率(Inverse Document Frequency)。TF表示詞條在文件d中出現的頻率。IDF的主要思想是:如果包含詞條t的文件越少,也就是n越小,IDF越大,則說明詞條t具有很好的類別區分能力。
詞頻 (term frequency, TF) 指的是某一個給定的詞語在該檔案中出現的次數。這個數字通常會被歸一化(一般是詞頻除以文章總詞數), 以防止它偏向長的檔案。公式:

以上式子中 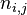 是該詞
是該詞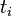 在檔案
在檔案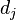 中的出現次數,而分母則是在檔案中所有字詞的出現次數之和。
中的出現次數,而分母則是在檔案中所有字詞的出現次數之和。
逆向檔案頻率 (inverse document frequency, IDF) IDF的主要思想是:如果包含詞條t的文件越少, IDF越大,則說明詞條具有很好的類別區分能力。某一特定詞語的IDF,可以由總檔案數目除以包含該詞語之檔案的數目,再將得到的商取對數得到。

其中
- |D|:語料庫中的檔案總數
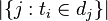 :包含詞語的檔案數目(即
:包含詞語的檔案數目(即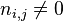 的檔案數目)如果該詞語不在語料庫中,就會導致被除數為零,因此一般情況下使用
的檔案數目)如果該詞語不在語料庫中,就會導致被除數為零,因此一般情況下使用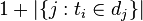
某一特定檔案內的高詞語頻率,以及該詞語在整個檔案集合中的低檔案頻率,可以產生出高權重的TF-IDF。因此,TF-IDF傾向於過濾掉常見的詞語,保留重要的詞語。 因此
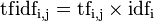
某一特定檔案內的高詞語頻率,以及該詞語在整個檔案集合中的低檔案頻率,可以產生出高權重的TF-IDF。因此,TF-IDF傾向於過濾掉常見的詞語,保留重要的詞語。TF-IDF是一種簡單有效詞權重統計方法。
二、基於多模型融合的詞權重計算
TF-IDF計算詞權重方法簡單可靠,但真正應用到系統中其準確度還是遠遠達不到要求,基於搜尋使用者的點選資料,提出一種離線資料探勘結合機器學習計算詞權重的方法,並在實際的應用中獲得不錯的效果,其實現框圖如下:
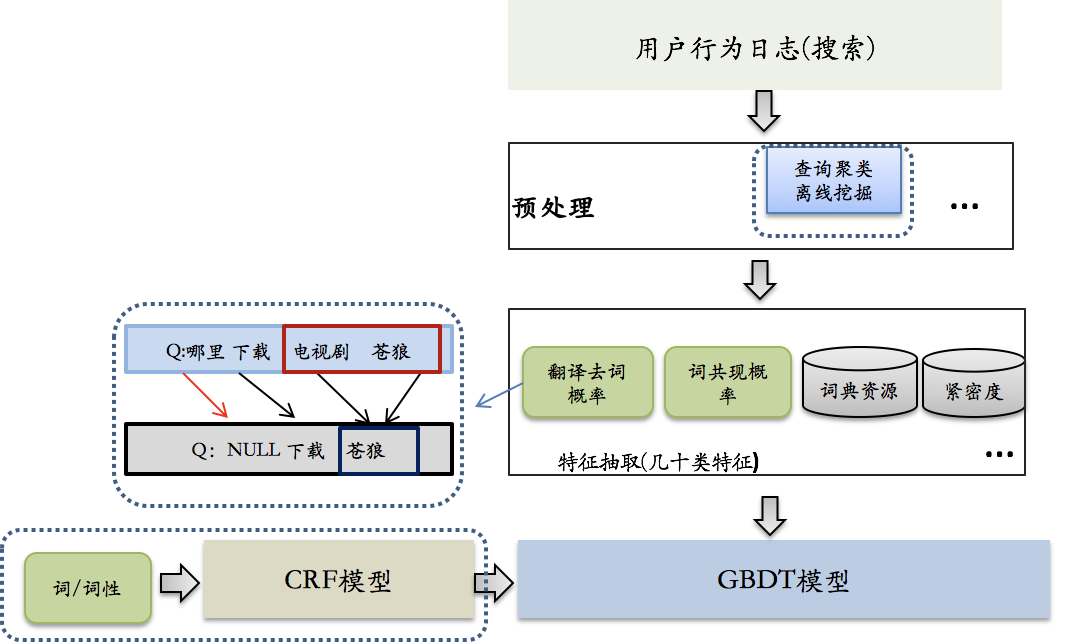
詞權重的計算主要包括兩方面的特徵:1、統計特徵,2、語言特徵。其中統計特徵是利用使用者搜尋日誌和點選日誌,統計詞的基本特徵,包括tf-idf,term在上下文中刪除概率等,利用點選日誌,根據共同點擊doc,構成相似的query集合,在相似的query集合中,基於詞共現某term出現的次數越多,相關的query相似度越高,則該term越重要。語言特徵是詞本身的屬性,主要包括詞性和詞類資訊,這些特徵類別多而且針對詞來說是唯一的,並且跟上下文有很強的關聯性,對特徵進行窮舉會非常稀疏,因此在使用語言特徵之前,利用CRF模型粗估詞權重特徵,對語言特徵進行融合,並把CRF模型結果作為最終詞權重模型的輸入特徵,預測詞權重。
三、利用深度學習模型生成詞權重
近年來,深度學習在自然語言處理中應用越來越廣泛,並且在大多數任務中效果上遠遠要優於傳統方法,特別是以LSTM模型為代表的具有序列記憶功能的深度學習,推動了自然語言處理領域的發展。我們也一直在嘗試利用LSTM解決詞權重計算問題,深度學習不同傳統的模型,需要大規模訓練資料。首先遇到的難題是需要自動構建大規模訓練資料,利用點選日誌,構建相似query集,通過計算詞共現概率來表示查詢中每個term的重要程度,構建詞權重訓練資料,訓練LSTM模型。根據模型輸出和標準答案之間的差異調節LSTM模型引數,訓練結束後lstm模型可以對任意query逐詞生成詞權重,具體如下圖所示:

傳統模型面對統計特徵不充分的查詢,存在資訊損失,而LSTM模型能在大規模訓練資料集中,融合更多、更長的上下文資訊,提升泛化和理解能力,並在生成query詞權重中充分考慮上下文資訊。目前利用深度學習模型在詞權重生成專案上僅嘗試過單層LSTM模型,之後可以考慮在embedding層加入更多的特徵,如詞性、句法分析、實體等詞級別特徵,另外可以考慮優化LSTM,如加入self-attention,雙向LSTM、甚至多層模型。對深度學習來說,最重要的優化還是訓練資料的質量提高,如何自動構建高質量的訓練資料一直是深度學習模型應用的重要課題。