
差分隱私(I)
差分隱私綜述_李效光
面向資料釋出和分析的差分隱私保護 張嘯劍
差分隱私保護及其應用 熊平
提出
隱私保護整體分成9個部分,包括隱私資訊產生、隱私感知、隱私保護、隱私釋出、私資訊儲存, 隱私交換, 隱私分析, 隱私銷燬, 隱私接收者。主要研究方向在在隱私保護, 隱私釋出/儲存/交換, 隱私分析這 3 個部分。
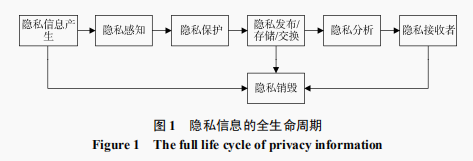
隱私保護的方式分成以下三種包括,資料失真,加密,以及訪問控制。目前的很多隱私保護技術往往結合了其中的多種技術。我們熟知的就是k-匿名演算法、l-匿名演算法、t-匿名演算法等等。
但這些匿名演算法有兩個重要的缺陷,其一是這些模型並不能提供足夠的安全保障,它們總是因新型攻擊的出現而需要不斷完善。例如為了抵制“一致性”攻擊,l-匿名演算法,t-匿名被相繼提出,m-confidentiality模型被用以抵制“最小性”攻擊,如今更多種型別的攻擊方法對基於分組的隱私包補模型形成挑戰,原因在於基於分組的隱私保護模型的安全性與攻擊者所掌握的背景知識相關,而所有可能的背景知識很難被充分定義。所以,一個與背景知識無關的隱私保護模型才可能抵抗任何新型的攻擊。其二,這些早期的隱私保護模型無法提供一種有效且嚴格的方法來證明其隱私保護水平,因此當模型引數改變時,無法對隱私保護水平進行定量分析。因此研究人員試圖找到一種能夠足夠好的隱私保護模型,並能夠衡量隱私標準的資料保護方法。
進而提出了差分隱私。首先,差分隱私保護模型假設攻擊者能夠獲得除目標記錄外所有其它記錄的資訊,這些資訊的總和可以理解為攻擊者所能掌握的最大背景知識。在這一最大背景知識假設下,差分隱私保護無需考慮攻擊者所擁有的任何可能的背景知識,因為這些背景知識不可能提供比最大背景知識更豐富的資訊。其次,它建立在堅實的數學基礎之上,對隱私保護進行了嚴格的定義並提供了量化評估方法,使得不同引數處理下的資料集所提供的隱私保護水平具有可比較性。
基本思想與期望效果
使用者項資料提供者提交查詢請求是,差分隱私系統從資料庫中提煉出一箇中間件,利用一個特別設計的隨機演算法對中介軟體注入適量的噪聲,再通過帶噪的中介軟體推匯出帶噪的查詢結果。返回給使用者的就是這個帶有噪聲的查詢結果。攻擊者能從帶噪的結果推回到帶噪的中介軟體,但不能準確的推斷出無噪中介軟體,也不能對資料庫進行推理,從而達到隱私的目的。
基本定義
:隱私保護預算,使用者衡量隱私保護程度。當引數 越小時, 作用在一對相鄰資料集上的差分隱私演算法返回的查詢結果的概率分佈越相似, 攻擊者就越難以區分這一對相鄰資料集, 保護程度就越高。當 時, 攻擊者無法區分這一對相鄰資料集保護程度最高。
敏感度:指刪除資料集中任一記錄對查詢結果照成的改變,是決定加入噪聲量大小的關鍵。分成全域性敏感度和區域性敏感度。
定義1 對於一個隨機演算法 , 為演算法 可以輸出的所有組織的集合,如果對於任意一對相鄰的資料集 和 , 的任意自己 演算法滿足 則稱演算法 滿足 -差分隱私。
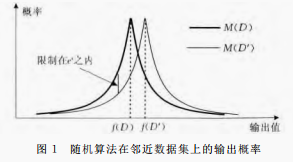
圖1給出演算法 M 通過對輸出結果的隨機化來提供隱私保護,同時通過引數
來保證在 資料集中刪除任一記錄時,演算法輸出同一結果的概率不發生顯著變化.
定義2 全域性敏感度:對於一個查詢函式
,其中
為一個數據集,
為d維實數向量,是查詢函式的返回結果。在任意一對相鄰資料集
和
上他的全域性敏感度定義為
其中,
是
與
之間的曼哈頓距離。
全域性敏感度反應了一個查詢函式在一對相鄰資料集上查詢時變化的最大範圍。他與資料集無關。只有查詢函式本身決定。一些函式的全域性敏感度較小,那隻需要加入較小量的噪聲,以掩蓋因一個記錄刪除對查詢結果所產生的影響,實現差分隱私保護。若函式具有較大的全域性敏感度(如平均值),必須在函式輸出時新增足夠大的噪聲才能保證隱私安全。
定義3 區域性敏感度:對於一個查詢函式 ,其中 為一個數據集, 為d維實數向量,是查詢函式的返回結果。對於給定的資料集 和他的任意鄰近資料集 ,有 在 上的區域性敏感函式為
區域性敏感度由函式 集合給定的資料集 中的具體資料共同決定,通常比全域性敏感度小很多,全域性敏感度和區域性敏感度的關係為 但區域性敏感度在一定程度上會體現資料集的資料分佈特徵.
定義4 平滑上界:給定資料集 和其任意臨近資料集 ,函式 的區域性敏感度為 。對於 ,若函式 滿足 且 ,則稱