
語音差分編碼(DPCM)的實現與改進——Python實現
介紹
這是視聽覺訊號處理的第二個實驗——語音差分編碼(DPCM)。總體來講,思路上還是比較簡單的,很容易理解。如果程式設計能力好的話,相信很快就能完成。奈何我太菜了,寫了幾個晚上才算搞定。做了點擴充套件,添加了自己神奇的想法,在這裡記錄一下。先附上程式碼地址:視聽覺訊號處理實驗二
DPCM 原理
DPCM 的原理很簡單,就是利用訊號取樣點之間的關聯性,即每個取樣點與相鄰的取樣點之間的差別很小,因此,就可以利用該特性進行壓縮。總地來說,就是先儲存第一個取樣點的數值,再儲存每個取樣點與前一個取樣點之間的差值,作為壓縮的資料。這樣的話,就可以利用第一個取樣點,加上差值,求出第二個取樣點,然後再加差值…一直持續下去,就可以求出所有采樣點的數值了,也就完成了語音還原。而且,由於沒個取樣點之間相差很小,因此,差值也不會很大,所以就可以利用較少的位元數來儲存壓縮的資料了,這樣也就實現了壓縮。
量化誤差
由於,這裡的差值可能過大,為便於儲存,一般設定一個量化因子,比如,如果量化因子是100的話,差值 400 就可以對映到 4 ,這樣的話壓縮資料可以用更少的位元儲存,但容易出現量化誤差。如果將所有的差值固定在一定的範圍內(比如這次實驗,儲存位元為4,差值範圍就是 -8 到 7 ,再乘上量化因子)。因此,如果差值過大或者過小,超出範圍了,就只能按照邊界值來定。而這樣的話,就會導致量化誤差。
由於計算出來的差值需要被量化,即對映到 -7 到 8。由於量化過程中,可能會因為差值超出可以正確量化的範圍,導致量化值精度不夠,從而可能導致解壓過程中計算出來的值與被壓縮資料不同。這種量化過程中出現的誤差就是量化誤差。
邊壓縮,邊解壓
如果一個數據出現了量化誤差,那麼後面的資料在還原的過程中就會在錯誤的資料上進行還原,這樣的話,會讓之前出現的誤差一直積累下去,影響後面所有的資料還原。那麼該怎麼解決呢,最簡單的方式就是邊壓縮,邊解壓,利用上一個還原的資料再對當前的資料進行壓縮,這樣的話,即使產生量化誤差,也只是影響一個取樣點,而不會影響後續取樣點的還原。
Python 實現
這裡並沒有真正地進行解壓,只是將壓縮過程中的解壓陣列儲存起來了。可以通過讀取壓縮檔案,並根據解壓公式來進行解壓。在改進版的實現中寫了這一過程。
# -*- coding: utf-8 -*- import wave import os import numpy as np # 壓縮檔案 def compressWaveFile(wave_data) : quantized_num = 100 # 量化因子 diff_value = [] compressed_data = [] decompressed_data = [] diff_value = [wave_data[0]] compressed_data = [wave_data[0]] decompressed_data = [wave_data[0]] for index in range(len(wave_data)) : if index == 0 : continue diff_value.append(wave_data[index] - compressed_data[index - 1]) compressed_data.append(calCompressedData(diff_value[index], quantized_num)) decompressed_data.append(decompressed_data[index - 1] + compressed_data[index] * quantized_num) return compressed_data, decompressed_data # 計算 對映 def calCompressedData(diff_value, quantized_num) : if diff_value > 7 * quantized_num : return 7 elif diff_value < -8 * quantized_num : return -8 for i in range(16) : j = i - 8 if (j - 1) * quantized_num < diff_value and diff_value <= j * quantized_num : return j for i in range(10) : f = wave.open("./語料/" + str(i + 1) + ".wav","rb") # getparams() 一次性返回所有的WAV檔案的格式資訊 params = f.getparams() # nframes 取樣點數目 nchannels, sampwidth, framerate, nframes = params[:4] # readframes() 按照取樣點讀取資料 str_data = f.readframes(nframes) # str_data 是二進位制字串 # 以上可以直接寫成 str_data = f.readframes(f.getnframes()) # 轉成二位元組陣列形式(每個取樣點佔兩個位元組) wave_data = np.fromstring(str_data, dtype = np.short) print( "取樣點數目:" + str(len(wave_data))) #輸出應為取樣點數目 f.close() compressed_data, decompressed_data = compressWaveFile(wave_data) # 寫壓縮檔案 with open("./壓縮檔案/" + str(i + 1) + ".dpc", "wb") as f : for num in compressed_data : f.write(np.int16(num)) # 寫還原檔案 with open("./還原檔案/" + str(i + 1) + ".pcm", "wb") as f : for num in decompressed_data : f.write(np.int16(num))
改進策略
整體演算法是,先對每個取樣點進行取絕對值然後加一的運算,將所有采樣點的值都變換到大於等於1的區間,然後對這個變換後的值取 log, 儲存取完 log 之後的相鄰資料之間的差值。由於這裡的壓縮檔案需要特意儲存一下每個取樣點的符號(使用 1 位元),然後再進行解密。相當於每個取樣點利用了加密檔案的 5 個位元。
加密過程:
-
首先,對每個取樣點進行變換,變換到取絕對值加一。
-
計算差值,根據公式:

將所有差值存到一個數組 d[0:n] 中 -
計算對映,將計算所得到的差值進行量化,即將差值對映到 -8 到 7 這個區間(壓縮成4位元,便於儲存)。將量化資料儲存起來,壓縮到檔案中時,需要使用該資訊。
-
然後,儲存差值,且為了避免誤差進行積累,一邊解密,一邊加密。
-
最後,需要計算整體取樣點的符號,然後利用 1 位元進行儲存,每 16 個符號為一組,組成一個 16 位元的無符號整數。(注:這一步可以跟上面的演算法並行完成。)
最後計算得到的加密檔案格式如下:

解密過程:
-
讀取壓縮檔案,將符號數和差值數區分開,分別儲存到不同的陣列中。
-
然後,對差值部分進行解壓,利用公式:
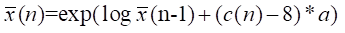
解壓所得到的是原來取樣點的絕對值加一,因此,先進行減一操作,然後根據對應的符號數再的符號位來判斷該取樣點的符號。 -
最後,得到一個所有采樣點的陣列。寫入 .pcm 檔案中。
改進後的Python 程式碼
# -*- coding: utf-8 -*-
import wave
import os
import numpy as np
import math
quantized_num = 0.12 # 量化因子
# 壓縮檔案
def compressWaveFile(wave_data) :
diff_value = [] # 儲存差值
compressed_data = [] # 儲存壓縮資料
decompressed_data = [] # 儲存解壓資料
# 初始化 將第一個取樣點存起來 第一個取樣點不進行加密
diff_value = [wave_data[0]]
compressed_data = [wave_data[0]]
decompressed_data = [wave_data[0]]
# 壓縮每個資料
for index in range(len(wave_data)) :
if index == 0 :
continue
# 做差的時候要取對數,對數的 自變數 x >= 0, 由於樣本點有正有負,因此這裡先取絕對值加一
waveData_abs = abs(wave_data[index]) + 1
decompressedData_abs = abs(decompressed_data[index - 1]) + 1
# 相當於對變換後的值,即取絕對值加一後的值進行加密
diff_value.append(math.log(waveData_abs) - math.log(decompressedData_abs))
compressed_data.append(calCompressedData(diff_value[index], quantized_num))
# 這裡進行解密,並直接將解密出來的數值進行減一操作
de_num = math.exp(math.log(abs(decompressed_data[index - 1]) + 1) + compressed_data[index] * quantized_num) - 1
# 判斷加密之前的樣本點符號是正還是負, 如果是負數,那麼解密出來的也應該是負數,需要乘-1
if wave_data[index] < 0 :
decompressed_data.append((-1) * de_num)
continue
decompressed_data.append(de_num)
return compressed_data, decompressed_data
# 將所有樣本點的符號儲存在
def calSig(wave_data) :
sig_array = []
sig_num = np.uint16(0)
# 除去第一個取樣點 每 64 個數據一組,將每組的符號位儲存在一個 16 位無符號整數中
for index in range(len(wave_data)) :
if index == 0 :
continue
if index % 16 == 1 :
if index != 1 :
sig_array.append(sig_num)
if wave_data[index] < 0 :
sig_num = np.uint16(1)
else :
sig_num = np.uint16(0)
if wave_data[index] < 0 :
sig_num = np.uint16((sig_num << 1) + 1) # 負數 左移 1 位,加 1
else :
sig_num = np.uint16(sig_num << 1) # 正數 左移 1 位
# 最後幾位也要存起來
if index == len(wave_data) - 1 :
sig_array.append(sig_num)
sig_array.insert(0, len(sig_array))
# print("符號陣列大小:" + str(len(sig_array)))
return sig_array
# 計算 對映 將差值對映到 -8 到 7 之間
def calCompressedData(diff_value, quantized_num) :
if diff_value > 7 * quantized_num :
return 7
elif diff_value < -8 * quantized_num :
return -8
for i in range(16) :
j = i - 8
if (j - 1) * quantized_num < diff_value and diff_value <= j * quantized_num :
return j
# 計算信噪比
def calSignalToNoiseRatio(wave_data, decompressed_data) :
sum_son = np.int64(0)
sum_mum = np.int64(0)
for i in range(len(decompressed_data)) :
sum_son = sum_son + int(decompressed_data[i]) * int(decompressed_data[i])
sub = decompressed_data[i] - wave_data[i]
sum_mum = sum_mum + sub * sub
return 10 * math.log10(float(sum_son) / float(sum_mum))
# 讀取壓縮檔案
def readCompressedFile(compressed_str) :
compressed_data = [] #用來儲存壓縮資料的陣列
# 取出前兩個壓縮資料,即第一個樣本點 和 符號數的個數
data_first = np.fromstring(compressed_str[0:2], dtype = np.uint16)
compressed_data.append(data_first[0])
data_next = np.fromstring(compressed_str[2:(data_first[0] + 1) * 2], dtype = np.uint16)
# print("第一個資料:" + str(data_first[0]) + "\t 讀取長度 :" + str(len(data_first)) + "\t" + str(len(data_next)))
for num in data_next :
compressed_data.append(num)
# 第一個取樣點
com_first = np.fromstring(compressed_str[(data_first[0] + 1) * 2 : (data_first[0] + 2) * 2], dtype = np.short)
compressed_data.append(com_first[0])
# 去除第一個樣本點,剩餘所有資料都以 4 bit 儲存
compressed_str = compressed_str[(data_first[0] + 2) * 2:len(compressed_str)]
compressed_data_append = np.fromstring(compressed_str, dtype = np.uint8)
# 將讀取出來的資料裝進壓縮陣列中,每一個數據,拆成兩個 4 bit 數
for num in compressed_data_append :
# 儲存的時候,是轉成 4 bit 無符號整數儲存的, 解密時,需要轉換回來
compressed_data.append((num >> 4) - 8)
compressed_data.append(((np.uint8(num << 4)) >> 4) - 8)
return compressed_data
# 解密 還原檔案
def decompressWaveFile(compressed_data) :
# 取出符號陣列
sig_num = compressed_data[0]
sig_array = compressed_data[1: sig_num + 1]
decompressed_data = []
# 將符號陣列從壓縮陣列中去除
compressed_data = compressed_data[sig_num + 1 : len(compressed_data)]
# 將第一個取樣點加入解密陣列中
decompressed_data.append(compressed_data[0])
for i in range(len(compressed_data)) :
if i == 0 :
continue
de_num = math.exp(math.log(abs(decompressed_data[i - 1]) + 1) + compressed_data[i]* quantized_num) - 1
# 去除第一個取樣點的佔位
t = i - 1
if np.uint16(1 << (15 - (t % 16))) & sig_array[int(t / 16)] != 0 :
decompressed_data.append((-1) * de_num)
continue
decompressed_data.append(de_num)
return decompressed_data
for i in range(10) :
f = wave.open("./語料/" + str(i + 1) + ".wav","rb")
# getparams() 一次性返回所有的WAV檔案的格式資訊
params = f.getparams()
# nframes 取樣點數目
nchannels, sampwidth, framerate, nframes = params[:4]
# readframes() 按照取樣點讀取資料
str_data = f.readframes(nframes) # str_data 是二進位制字串
# 以上可以直接寫成 str_data = f.readframes(f.getnframes())
# 轉成二位元組陣列形式(每個取樣點佔兩個位元組)
wave_data = np.fromstring(str_data, dtype = np.short)
print( "取樣點數目:" + str(len(wave_data))) #輸出應為取樣點數目
f.close()
compressed_data, decompressed_data = compressWaveFile(wave_data)
# 計算符號陣列
sig_array = calSig(wave_data)
# 寫壓縮檔案
with open("./壓縮檔案/" + str(i + 1) + ".dpc", "wb") as f :
# 寫入樣本符號
for sig_num in sig_array :
f.write(np.uint16(sig_num))
# 寫入差值
num = 0
f.write(np.int16(compressed_data[0]))
for j in range(len(compressed_data)) :
# 第一個資料已經壓縮
if j == 0 :
continue
# 壓縮資料 如果有最後一個數據沒拼上一個子節,則丟棄該樣本點
elif j % 2 == 1 :
num = np.uint8((compressed_data[j] + 8 )<< 4)
else :
num = np.uint8(num + np.uint8(compressed_data[j] + 8))
f.write(num)
# 讀壓縮檔案 解壓
with open("./壓縮檔案/" + str(i + 1) + ".dpc", "rb") as f :
compressed_data = readCompressedFile(f.read())
decompressed_data = decompressWaveFile(compressed_data)
# # 測試 寫壓縮檔案
# with open("./還原檔案/" + str(i + 1) + ".txt", "w") as f :
# for num in compressed_data :
# f.write(str(num) + "\n")
# 寫還原檔案
with open("./還原檔案/" + str(i + 1) + ".pcm", "wb") as f :
for num in decompressed_data :
f.write(np.int16(num))
print("檔案 " + str(i + 1) + " 的信噪比:" + str(calSignalToNoiseRatio(wave_data, decompressed_data)))
總結
總的來說,這個實驗還是挺自由的。我比較喜歡這個實驗老師的風格,隨意。而且老師強調,做實驗不用太拘束,隨便寫,就跟玩一樣。真的挺喜歡這個觀點的,實驗的主要目的就是讓我們熟悉語音,掌握語音的操作和演算法,總是按照那麼多條條框框來,重心就很容易偏。