
ml課程:概率圖模型—貝葉斯網路、隱馬爾可夫模型相關(含程式碼實現)
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教。
本文主要介紹機器學習中的一個分支——概率圖模型、相關基礎概念以及樸素貝葉斯、隱馬爾可夫演算法,最後還有相關程式碼案例。
說到機器學習的起源,可以分為以下幾個派別:
- 連線主義:又稱為仿生學派(bionicsism)或生理學派(physiologism),其主要原理為神經網路及神經網路間的連線機制與學習演算法。比如今天很火的:tensorflow、pytorch、theano、caffe等等。
- 符號主義:又稱為邏輯主義(logicism)、心理學派(psychologism)或計算機學派(computerism),其原理主要為物理符號系統(即符號作業系統)假設和有限合理性原理。
- 統計學派:利用經典的統計學習理論為代表,具體有SVM等統計學習理論。
- 概率圖模型:相比於其他學習演算法的優勢在於可以利用圖結構來將已知資訊帶入到知識網路中。主要代表有樸素貝葉斯、隱馬爾可夫等等。
基本概念:
貝葉斯公式:下面這是最簡單的貝葉斯公式:

複雜的形式可以寫成:
貝葉斯網路:
是一種模擬人類推理過程中因果關係的不確定定處理模型,其網路結構是一個有向無環圖(directed acyclic graph)。
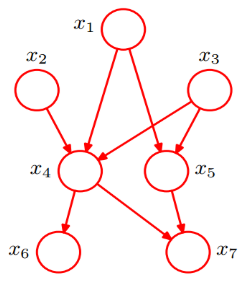
全概率公式:
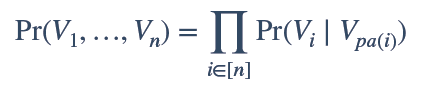
我們利用上圖可以將原本聯合概率公式P(x1,x2,x3,x4,x5,x6,x7),由原來的複雜形式,轉換為簡單的條件概率公式相乘,從而將原來的複雜度降到n次複雜,大大簡化計算量:
例:

![]()
同時我們可以根據給定聯合概率時,求得單個條件概率的值。
馬爾科夫鏈:因安德烈·馬爾可夫(A.A.Markov,1856-1922)得名,是指數學中具有馬爾可夫性質的離散事件隨機過程。在給定當前知識或資訊的情況下,過去(即當前以前的歷史狀態)對於預測將來(即當前以後的未來狀態)是無關的。其中每個狀態的轉移只依賴於之前的n個狀態,這個過程被稱為1個n階的模型,其中n是影響轉移狀態的數目。
最簡單的馬爾科夫過程就是一階過程,每一個狀態的轉移只依賴於其之前的那一個狀態,用數學表示式表示如下:
![]()
隱馬爾可夫模型(Hidden Markov Model) :包含一個隱藏的馬爾科夫過程和一個與這個隱藏馬爾科夫過程概率相關的並且可以觀察到的狀態集合。它是一種統計模型,用來描述一個含有隱含未知引數的馬爾可夫過程。該模型克服了前後馬爾科夫鏈前後關係缺失帶來的困擾,因此可以觀察的引數中確定該過程的隱含引數,然後利用這些引數來作進一步的分析。
條件獨立(conditional independence):我們都知道獨立分佈的概率可以表示為:

那麼條件獨立公式就是:

我們也可以根據圖的形式來表示:圖中表示獨立條件,
表示不獨立。



應用演算法:
隱馬爾科夫鏈(HMM):

隱馬爾科夫鏈主要有以下四種解法:
- 遍歷演算法;
- Forward Algorithm,向前演算法,或者Backward Algo,向後演算法;
- Viterbi Algo,維特比演算法;
- Baum-Welch Algo,鮑姆-韋爾奇演算法。
遍歷演算法:該演算法時間複雜度為2T。


前項、後項演算法:該演算法時間複雜度為。


Vierbi演算法:

演算法實踐:歡迎關注我的github,HMM_viterbi詞性標註
(Baum-Welch Algo)鮑姆-韋爾奇演算法:這個演算法也屬於EM演算法的一種。



樸素貝葉斯(naive bayes)演算法:

核心程式碼:
#定義先驗概率
def prior(vd,normal):
for i in range(len(normal)):
for j in range(vd):
normal_count_dict[j]=normal_count_dict.get(j,0)+normal.content[i][j]
#計算vd各特徵向量出現的次數,即,求content各特徵向量count按列累加的結果
for j in range(vd):
normal_count_prob[j]=(normal_count_dict.get(j,0)+1)/(len(normal)+2)
#計算vd各特徵向量出現的概率(拉普拉斯平滑)
#定義後驗概率
def posterior():
for i in range(X_test_array.shape[0]):
for j in range(X_test_array.shape[1]):
if X_test_array[i][j]!=0:
Px_spam[i]=Px_spam.get(i,1)*spam_count_prob.get(j)
#計算vd條件下,各測試樣本的後驗概率
Px_normal[i]=Px_normal.get(i,1)*normal_count_prob.get(j)
#計算normal條件下,各測試樣本的後驗概率
test_classify[i]=Py0*Px_normal.get(i,0),Py1*Px_spam.get(i,0)
#後驗概率P(Y|X)=P(Y)*P(X|Y)/P(X)
簡單介紹了隱馬爾可夫即樸素貝葉斯相關概念及相關程式碼實現,後續會繼續更新,To be continue......