
ml課程:決策樹、隨機森林、GBDT、XGBoost相關(含程式碼實現)
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教。
基礎概念:
熵Entropy:是衡量純度的一個標準,表示式可以寫為:

資訊增益Information Gain:熵變化的一個量,表示式可以寫為:

資訊增益率Gain Ratio:資訊增益的變化率,表示式可以寫為:

基尼係數Gini Index:Gini(D)越小,資料集D的純度越高,具體表達式如下:

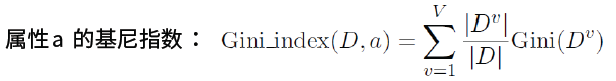
實際上基尼指數、熵、分類誤差率三者之間數學關係是統一的,將f(x)=-lnx在x=1處一階泰勒展開,忽略高階無窮小,可以得到f(x)1-x:


總體流程:
決策樹遵循‘分而治之(divide and conquer)’的思想:
- 自根至葉的遞迴過程
- 在每個中間節點尋找一個‘劃分’屬性
三種停止條件:
- 當前節點包含的樣本全屬於同一類別,無需劃分
- 當前屬性集為空,或是所有樣本在所有屬性上取值相同,無法劃分
- 當前節點包含的樣本集合為空,不能劃分

常見演算法:
ID3演算法:是根據資訊增益來選擇節點屬性。
- 對當前樣本集合,計算所有屬性的資訊增益;
- 選擇資訊增益最大的屬性作為測試屬性,把測試屬性取值相同的樣本劃為同一子樣本集;
- 若子樣本集的類別屬性只含有單個屬性,則分支為子葉結點,判斷其屬性值並標上相應的符號,然後返回呼叫處;否則對子樣本集遞迴呼叫本演算法。
但是ID3演算法有bug,就是容易將日期、排序等數目較多的屬性有所偏好,那麼就容易過擬合,如下圖:

因此我們常常用剪枝Prune的方法來避免過擬合。
核心程式碼:
#先計算各類別出現頻率(作為概率pi),然後呼叫資訊熵公式計算 #H(D)-= (pi*logpi) def calEntropy(dataset): n=len(dataset) labelCounts={} #對資料集各資料的類別計數 for data in dataset: datalabel=data[-1] #取data最後一列,類別列 if datalabel not in labelCounts.keys(): labelCounts[datalabel]=0 labelCounts[datalabel]+=1 entropy=0.0 #計算各類別出現頻率(作為概率pi),呼叫資訊熵公式計算 H(D)-=(pi*logpi) for key in labelCounts.keys(): prob=float(labelCounts[key])/n entropy -= prob*log(prob,2) return entropy
C4.5演算法:使用資訊增益率選擇節點屬性。它是一種啟發式的演算法:先從劃分屬性中找出資訊增益高於平均水平的,在從中選取資訊增益率最高的。因此它可以既可以處理離散的屬性,也可以處理連續值屬性,具體過程和ID3相似。
CART演算法:使用基尼係數選擇節點屬性,通過在候選屬性集合中,選取那個使劃分後基尼係數最小的屬性。它是一種二叉樹;也是一種十分有效的分引數分類和迴歸方法,當終節點是連續變數時,該樹為迴歸樹;當終節點是分類變數時,該樹為分類樹。
以下是三個演算法的統計表格:

關於決策樹的優劣比較:

迴歸樹:基於cart演算法我們推出了樹迴歸演算法。它的構建方法具體如下:
假設一個迴歸問題,預估結果yR,特徵向量為X=[x1,x2,x3...xp]
R,迴歸樹的兩個步驟是:
- 把整個特徵空間X切分成J個沒有重疊的區域R1,R2,R3...Rj
- 其中區域Rj中的每個樣本我們都給一樣的預測結果
,其中n是Rj中的總樣本數。
因此我們就是為了找到如下RSS最小的劃分方式R1,R2,R3...RJ:

但是這個過程計算量太大了,因此我們採用探索式遞迴二分類解決這個問題。
遞迴二分:
- 自頂向下的貪婪是遞迴方案:
- 自頂向下:從所有樣本開始,不斷從當前位置,把樣本切分到2個分支裡
- 貪婪:每一次的劃分,只考慮當前最優,而不回過頭考慮之前的劃分
- 選擇切分的維度(特徵)xj以及切分點s是的劃分後的數RSS結果最小:

迴歸樹剪枝:如果讓迴歸樹充分生長,會有過擬合的風險,因此我們新增正則化進行限制,考慮剪枝後得到的子樹{},其中
是正則化係數,當固定一個
後,最佳的
就是是的下列獅子子值最小的子樹:
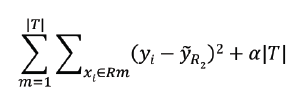
其中:|T|是迴歸樹葉子節點個數,可以通過交叉驗證選擇。
核心程式碼:
#二分資料
def binSplitDataSet(dataset,feat,val):
mat0=dataset[nonzero(dataset[:,feat]>val)[0],:] #陣列過濾選擇特徵大於指定值的資料
mat1=dataset[nonzero(dataset[:,feat]<=val)[0],:] #陣列過濾選擇特徵小於指定值的資料
return mat0,mat1
#定義迴歸樹的葉子(該葉子上各樣本標籤的均值)
def regLeaf(dataset):
return mean(dataset[:,-1])
#定義連續資料的混亂度(總方差,即連續資料的混亂度=(該組各資料-該組資料均值)**2,即方差*樣本數))
def regErr(dataset):
return var(dataset[:-1])*shape(dataset)[0]
#最佳特徵以及最佳特徵值選擇函式
def chooseBestSplit(dataset,leafType=regLeaf,errType=regErr,ops=(1,4)):
tolS=ops[0];tolN=ops[1];m,n=shape(dataset)
S=errType(dataset);bestS=inf;beatIndex=0;bestVal=0
if len(set(dataset[:,-1].T.tolist()[0]))==1: #若只有一個類別
return None,leafType(dataset)
for featIndex in range(n-1):
for splitVal in set(dataset[:,featIndex].T.tolist()[0]):
mat0,mat1=binSplitDataSet(dataset,featIndex,splitVal)
#若切分後兩塊資料的最少樣本數少於設定值,不切分
if (shape(mat0)[0]<tolN) or (shape(mat1)[0]<tolN):
continue
newS=errType(mat0)+errType(mat1)
if newS<bestS:
bestIndex=featIndex;bestVal=splitVal;bestS=newS
#若以最佳特徵及特徵值切分後的資料混亂度與原資料混亂度差值小於閾值,不切分
if (S-bestS)<tolS:
return None,leafType(dataset)
mat0,mat1=binSplitDataSet(dataset,bestIndex,bestVal)
#若以最佳特徵及特徵值切分後兩塊資料的最少樣本數少於設定值,不切分
if (shape(mat0)[0]<tolN) or (shape(mat1)[0]<tolN):
return None,leafType(dataset)
return bestIndex,bestVal
"""構建迴歸樹"""
def createTree(dataset,leafType=regLeaf,errType=regErr,ops=(1,4)):
feat,val=chooseBestSplit(dataset,leafType,errType,ops)
if feat==None:
return val
regTree={}
regTree['spFeat']=feat
regTree['spVal']=val
lSet,rSet=binSplitDataSet(dataset,feat,val)
regTree['left']=createTree(lSet,leafType,errType,ops)
regTree['right']=createTree(rSet,leafType,errType,ops)
return regTree
決策樹的整合Ensemble:
首先要說下Booststraping思想:這個名字來自成語‘pull up by your own booststraps’,意思是靠你自己的資源,簡稱自助法,他是一種又放回的抽樣方法,是非引數統計中一種重要的估計統計量方差而進行區間估計量的統計方法。該方法在小樣本時效果很好,通過方差的估計可以構造置信區間。核心步驟如下:
- 採用重複抽樣技術從原始樣本中抽取一定數量(自己給定)的樣本,此過程允許重複抽樣。
- 根據抽出的樣本計算給定的統計量T.
- 重複上述N次(一般大於1000),得到N個統計量T。
- 計算上述N個統計量T的樣本方差,得到統計量的方差。
Bagging演算法:是boostrap aggregating的縮寫,使用了上述的bootstraping思想,可以降低過擬合的風險,提高泛化能力,具體流程如下:

- 輸入樣本集D={(x,y1),(x2,y2),...(xm,ym)}
- 對於t = 1,2,... ,T:
a)對訓練集進行第t次隨機取樣,共採集m次,得到包含m個樣本的取樣集Dm
b)用取樣集Dm訓練第m個基學習器Gm(x)
3.分類場景,則T個學習器投出最多票數的類別為最終類別。迴歸場景,T個學習器得到的迴歸出結果進行算數平均得到的值為最終的模型輸出。
隨機森林RandomForest演算法:與Bagging基本類似,使用了CART決策樹作為基學習器,不同點在於bagging是隨機抽取樣本,而隨機森林是對樣本、屬性都進行隨機抽取。
- 從原始訓練集中,應用boostrap方法有放回的隨機抽取k個新的自助樣本集,並由此構建k棵分類迴歸樹,每次未被抽到的樣本組成了k個袋外資料(out-of-bag)
- 設有n個特徵,則在每一個樹的每個節點處隨機抽取m個特徵,通過計算每個特徵蘊含的資訊量,特徵中選擇一個最具有分類能力的特徵進行節點分裂。
- 每棵樹最大限度的生長,不做任何剪裁。
- 將生成的最多棵樹組成隨機森林,用隨機森林對新的資料進行分類,分類結果按分類器投票多少而定。迴歸場景,T個基模型(迴歸樹)得到的迴歸結果進行算術平均得到的值為最終的模型輸出。
Boosting演算法:與之前兩種演算法不同,具體流程如下:

- 先在原資料集長出一個樹
- 把先前一個樹沒能完美分類的資料重新weight
- 用新的re-weighted 樹在訓練出一個樹
- 最終的分類結果由加權投票決定
公式:
![]()

Adaboost演算法:這個演算法是boosting演算法的實現之一,也是比較常用的演算法,具體流程如下:
- 初始化訓練資料的權值分佈,每一個訓練樣本最開始時都被賦予相同的權值:1/n

- 進行多輪迭代,用m=1,2,...,m表示迭代的第多少輪:
a)使用具有權值分佈Dm的訓練集學習,得到基本分類器(選取讓誤差率最低的閾值來設計基本分類器):
![]()
b)計算Gm在訓練資料集上的分類誤差率(Gm在訓練資料集上的誤差率em就是被Gm誤分類樣本的權值之和),這裡I表示0或者1取值,表示錯誤的次數:

c)計算Gm的係數,表示Gm在最終分類器中的重要程度(得到基本分類器在最終分類器中所佔的權重),
<=
時,
>=0,且
隨著
的減小而增大,意味著分類誤差率越小的分類器在最終分類器中的作用越大:

d)更新訓練資料集的權值分佈(為了得到樣本的新的權值分佈),用於下一輪迭代。

使得被基本分類器Gm誤分類樣本的權值增大,而被正確分類樣本的權值減小。通過這樣的方式,Adaboost能重點關注於那些較難分的樣本上。

其中:Zm表示規範化因子,使得成為一個概率分佈。
3.組合各個弱分類器:

得到最終分類器,如下:
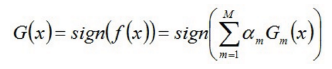
核心程式碼:
#label為樣本標籤,shape=(1,m)
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr=[];m=shape(dataArr)[0]
D=mat(ones((m,1))/m) #初始化樣本權重
aggClassEst=mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst=buildStump(dataArr,classLabels,D)
alpha = float(0.5*log((1.0-error)/max(error,1e-16))) #max(error,1e-16)防止0誤差的計算溢位
bestStump["alpha"]=alpha
weakClassArr.append(bestStump)
#print ("D:",D.T,"\n","predClass:",classEst.T)
#為下一次迭代更新D(很關鍵,矩陣運算容易寫錯!)
expon=multiply(-1*alpha*mat(classLabels).T,classEst) #shape(5,1)*shape(5,1)對應元素相乘,得到各樣本的-alpha*yi*G(xi)
D=multiply(D,exp(expon)) #shape(5,1)*shape(5,1)對應元素相乘,
D=D/D.sum() #得到各樣本更新後的wi
#計算彙集的分類結果aggClassEst(即,將每次最佳決策樹分類結果bestClass*alpha相加)
aggClassEst+=alpha*classEst
#print("aggClassEst:",aggClassEst.T)
aggErrors=multiply(sign(aggClassEst)!=mat(classLabels).T,ones((m,1)))
errorRate=aggErrors.sum()/m
#print("total error:",errorRate)
if errorRate==0.0:
break
return weakClassArr,errorRate,aggClassEst
GBDT演算法(Gradient Boosted Decison Tree):是Adaboost的迴歸版本,是將原來adaboost中0或者1的誤差率的計算,變成err這個計算(err代表多種誤差計算,例如前面說過的平方誤差,log誤差等等),具體公式如下:

計算得到的殘差,作為下一輪迭代的學習目標,最終的結果有加權和值得到,不在是簡單的多數投票:

XGBoost演算法(Extreme GBoosted):從名字可以看出,該演算法是GBDT的高階版,它是將GBDT的速度和效率做到了極致。主要變化如下:
- 使用L1和L2正則化防止過擬合:

- 對代價函式進行一階和二階求導,更快的收斂;
- 對其進行從下之上的剪枝,防止演算法貪婪。
後續我們會繼續學習如何對XGboost及GBDT等整合演算法進行引數調節,To be continue......