解析怎麼用爬蟲軟體去採集瓜子二手車的車輛資料
說起大資料,估計大家都覺得只聽過概念,但是具體是什麼東西,怎麼定義,估計很多人都沒有一個明確的概念,在《大資料時代》提到了大資料的4個特徵,一個是數量大,一個是價值大,一個是速度快,一個是多樣性。
一個是數量比較大,大致有多大,就是大到PB級別,甚至ZB級別,1PB等於1024TB,1TB等於1024G,那麼1PB等於100多G,當然了具體的計算方法可以相關資料資料進行查詢,總之,和傳統的單個網站資料庫儲存的資料相比,已經是它的上百倍還多,而只有資料體量達到了PB級別以上,才能被稱為大資料。
第二個是價值大,價值是大體量資料的更深一步的演變,就是說,你如果有1PB以上的全國所有20-35年輕人的上網資料的時候,那麼它自然就有了商業價值,比如通過分析這些資料,我們就知道這些人的愛好,進而指導產品的發展方向等等。如果有了全國幾百萬病人的資料,根據這些資料進行分析就能預測疾病的發生。這些都是大資料的價值。
第三個就是多樣性,如果只有單一的資料,那麼這些資料就沒有了價值,比如只有單一的個人資料,或者單一的使用者提交資料,這些資料還不能稱為大資料,所以說大資料還需要是多樣性的,比如當前的上網使用者中,年齡,學歷,愛好,性格等等每個人的特徵都不一樣,這個也就是大資料的多樣性,當然瞭如果擴充套件到全國,那麼資料的多樣性會更強,每個地區,每個時間段,都會存在各種各樣的資料多樣性。
第四個是速度快,就是通過演算法對資料的邏輯處理速度非常快,1秒定律,可從各種型別的資料中快速獲得高價值的資訊,這一點也是和傳統的資料探勘技術有著本質的不同。
而大資料蘊含著極大的價值,對我們的工作和生活具有重大的影響,如何快速有效的獲取到這些資料為我們服務,是一個大難題。出現了問題,自然就有解決問題的人,為了解決這一問題,后羿工程師團隊經過不斷的探索和研發,終於開發出一款基於人工智慧技術的網路爬蟲軟體,只需要輸入網址就能夠自動識別網頁資料,無需配置即可完成資料採集,是業內首家支援三種作業系統(包括Windows、Mac和Linux)的採集軟體。同時這是一款真正免費的資料採集軟體,對採集結果匯出沒有任何限制,沒有程式設計基礎的小白使用者也可輕鬆實現資料採集要求。
那麼這款軟體如何使用呢,我們就以瓜子二手車上的二手車資料為例,為大家演示如何高效且免費的快速採集資料。
首先複製需要採集的網址,注意需要複製的是結果頁的網址,而不是搜尋頁的網址,然後在軟體中輸入網址新建智慧採集任務。
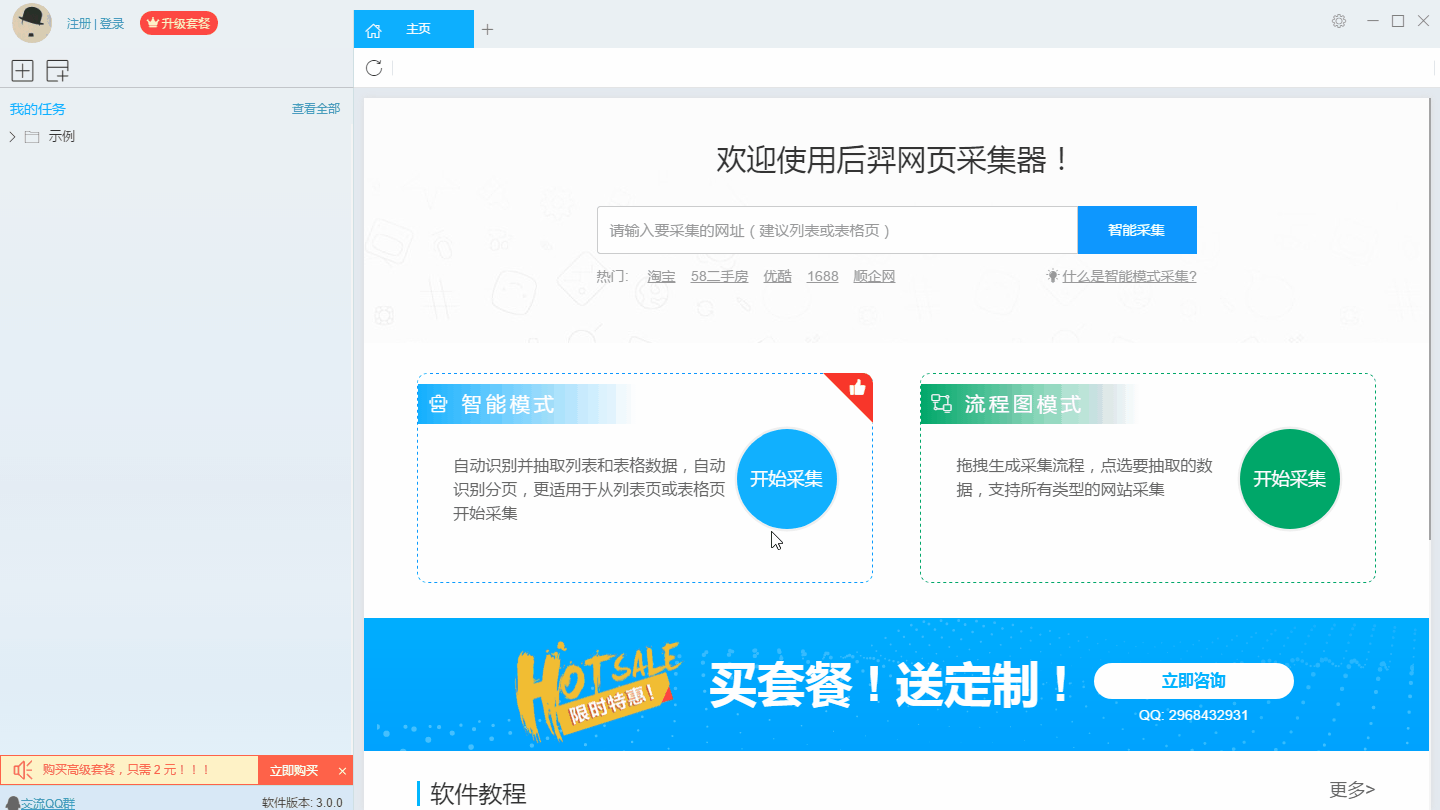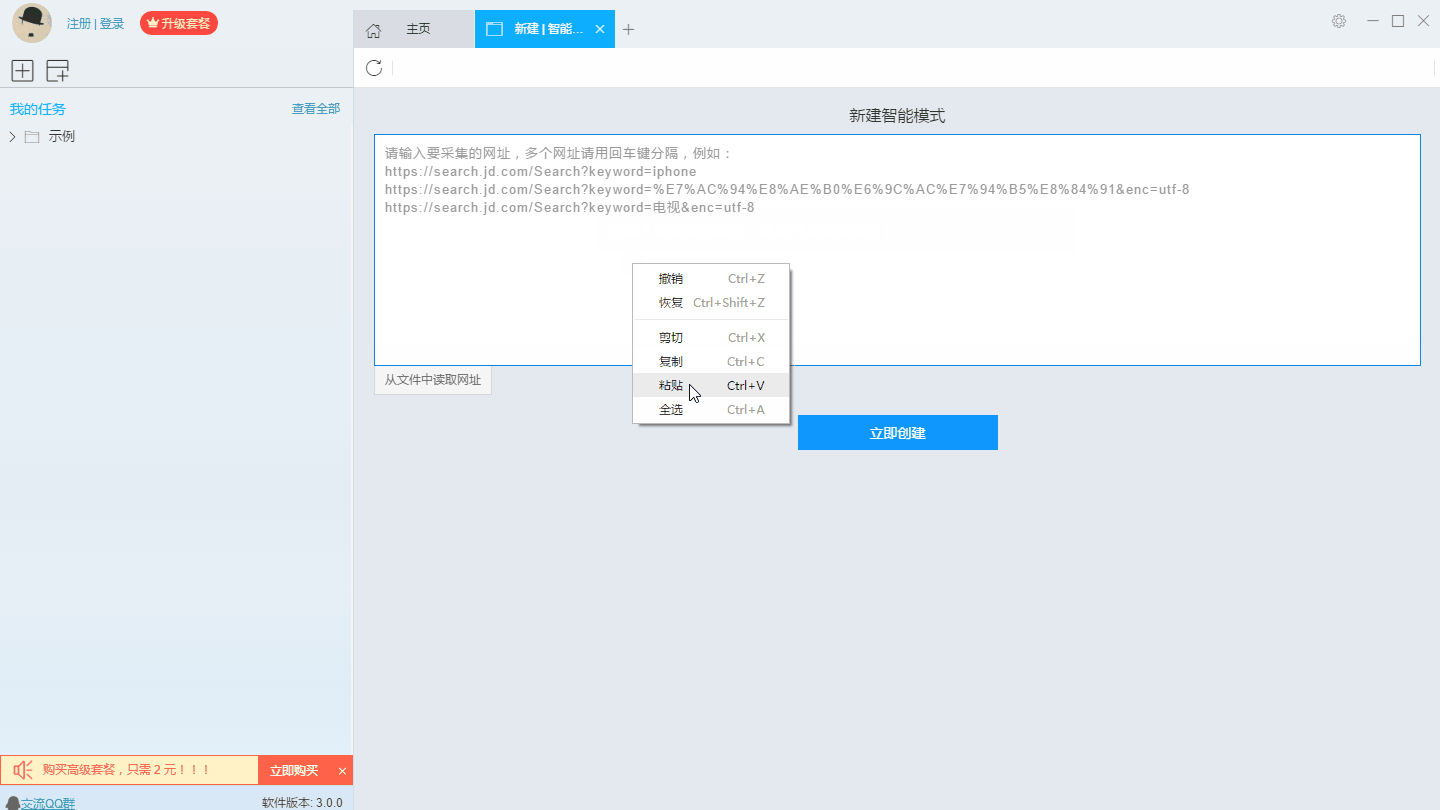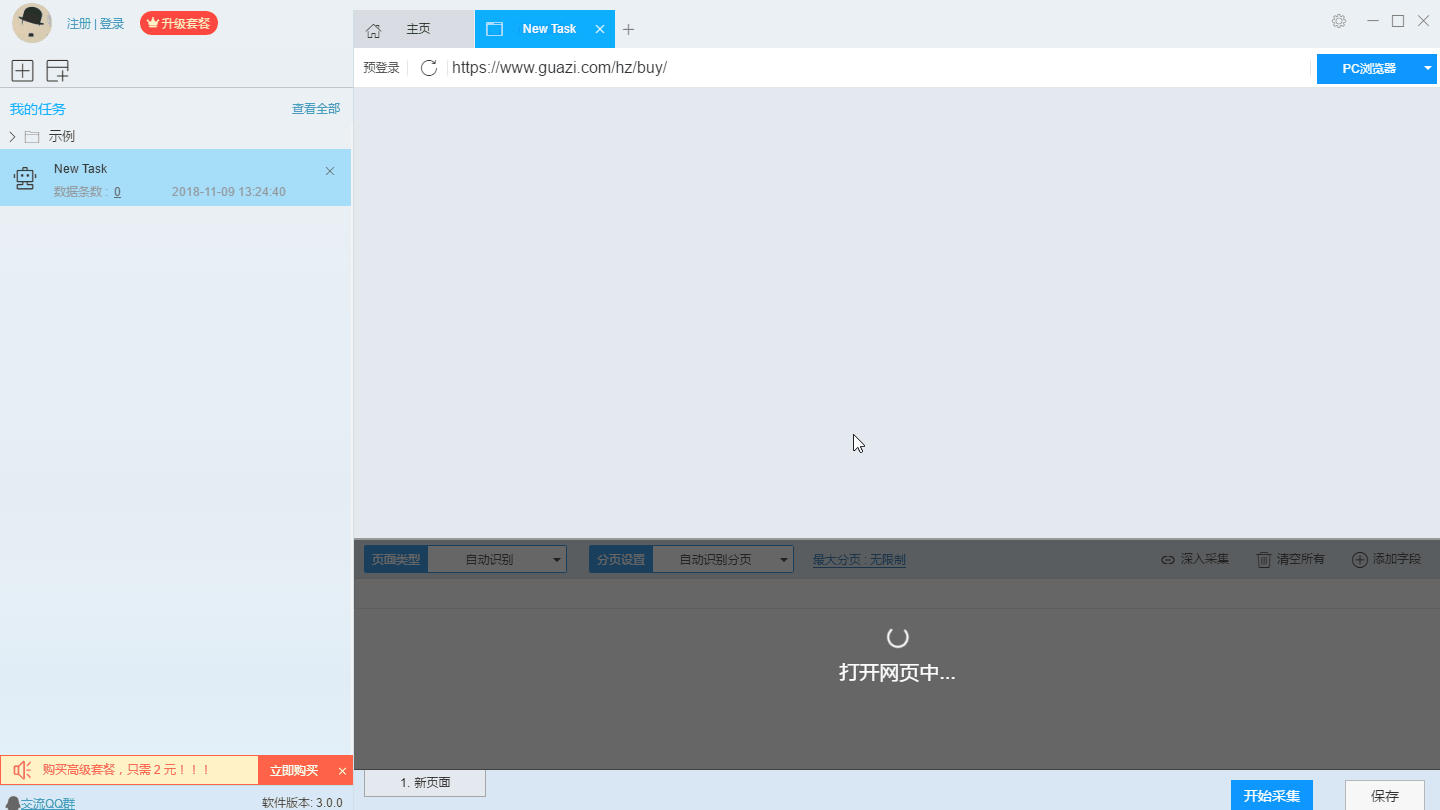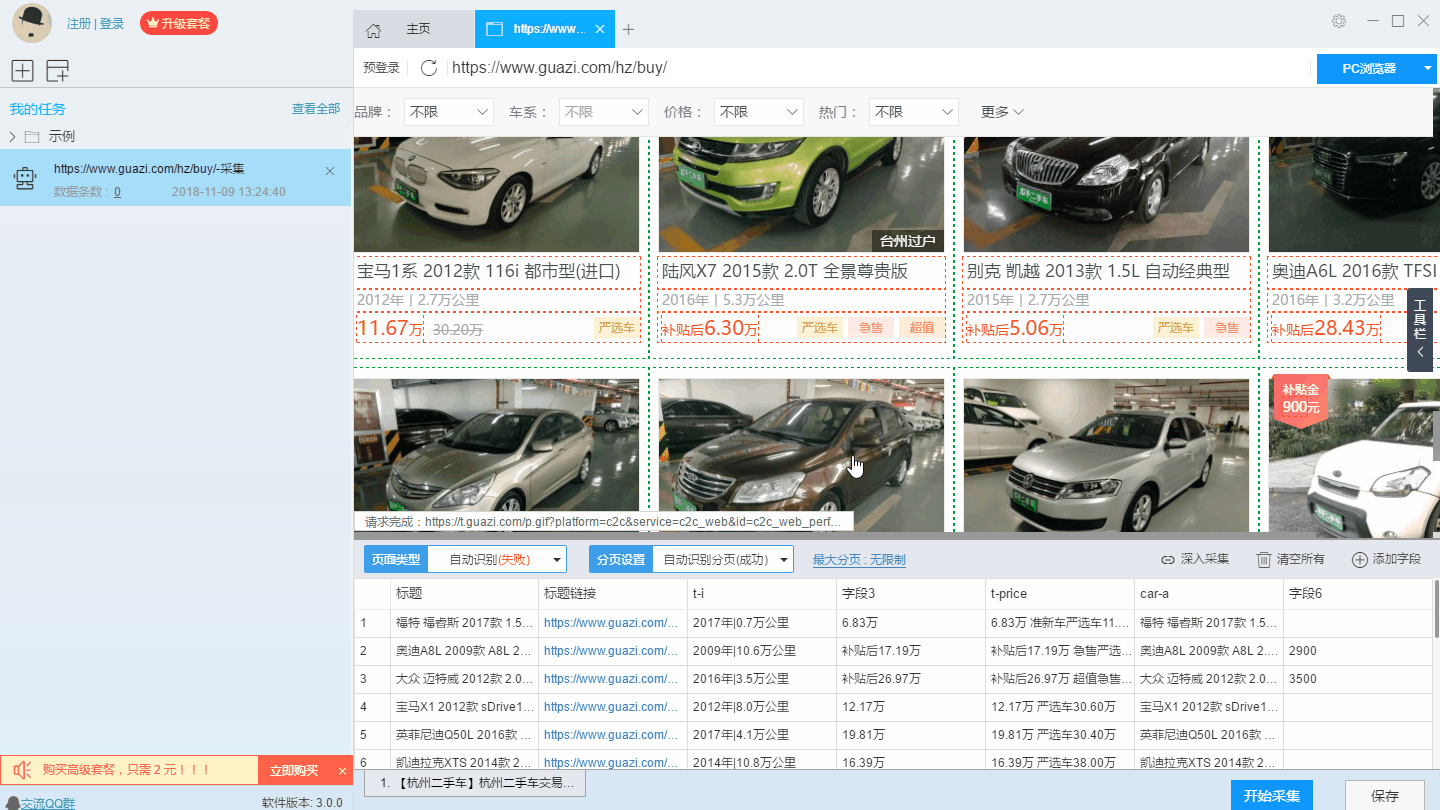
在新建的智慧模式下,軟體即可自動識別出頁面上的資料並生成採集結果,每一類資料對應一個採集欄位,我們可以右擊欄位進行相關設定,包括修改欄位名稱、增減欄位、處理資料等。
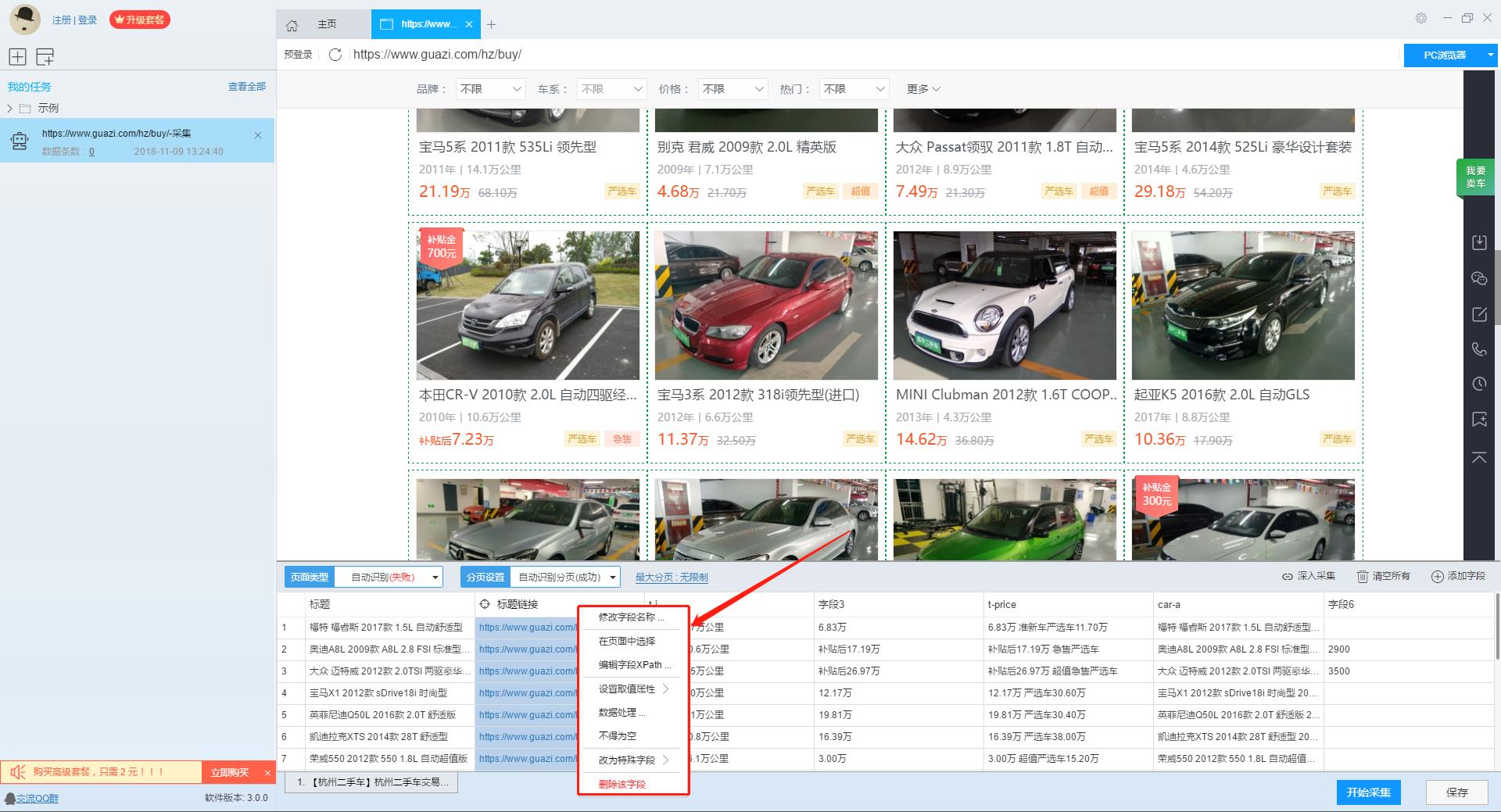
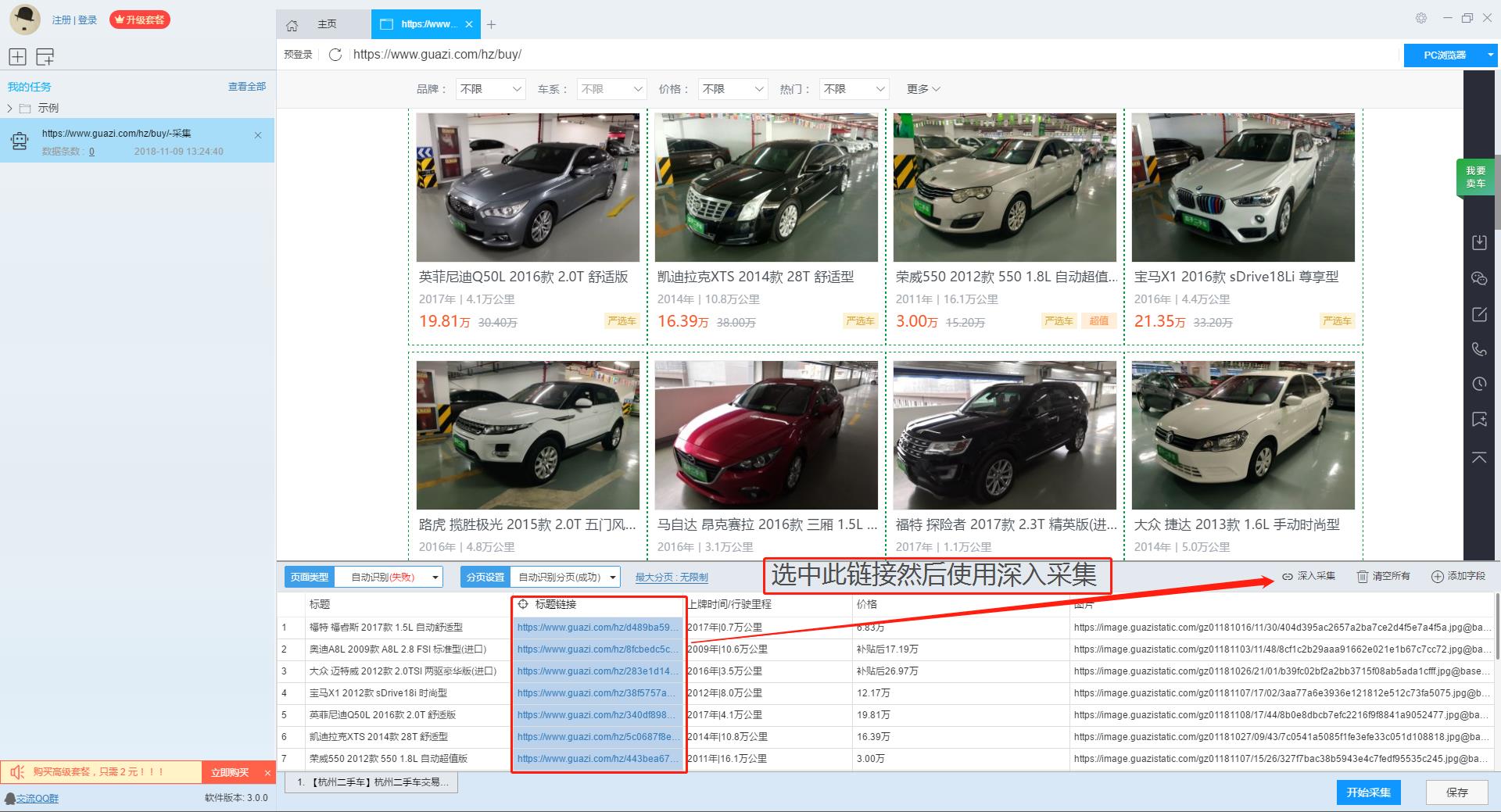
由於在列表頁上只展示了部分資訊,如果需要採集看車地址及諮詢電話,我們需要右擊連結使用“深入採集”功能,跳轉到詳情頁進行採集。
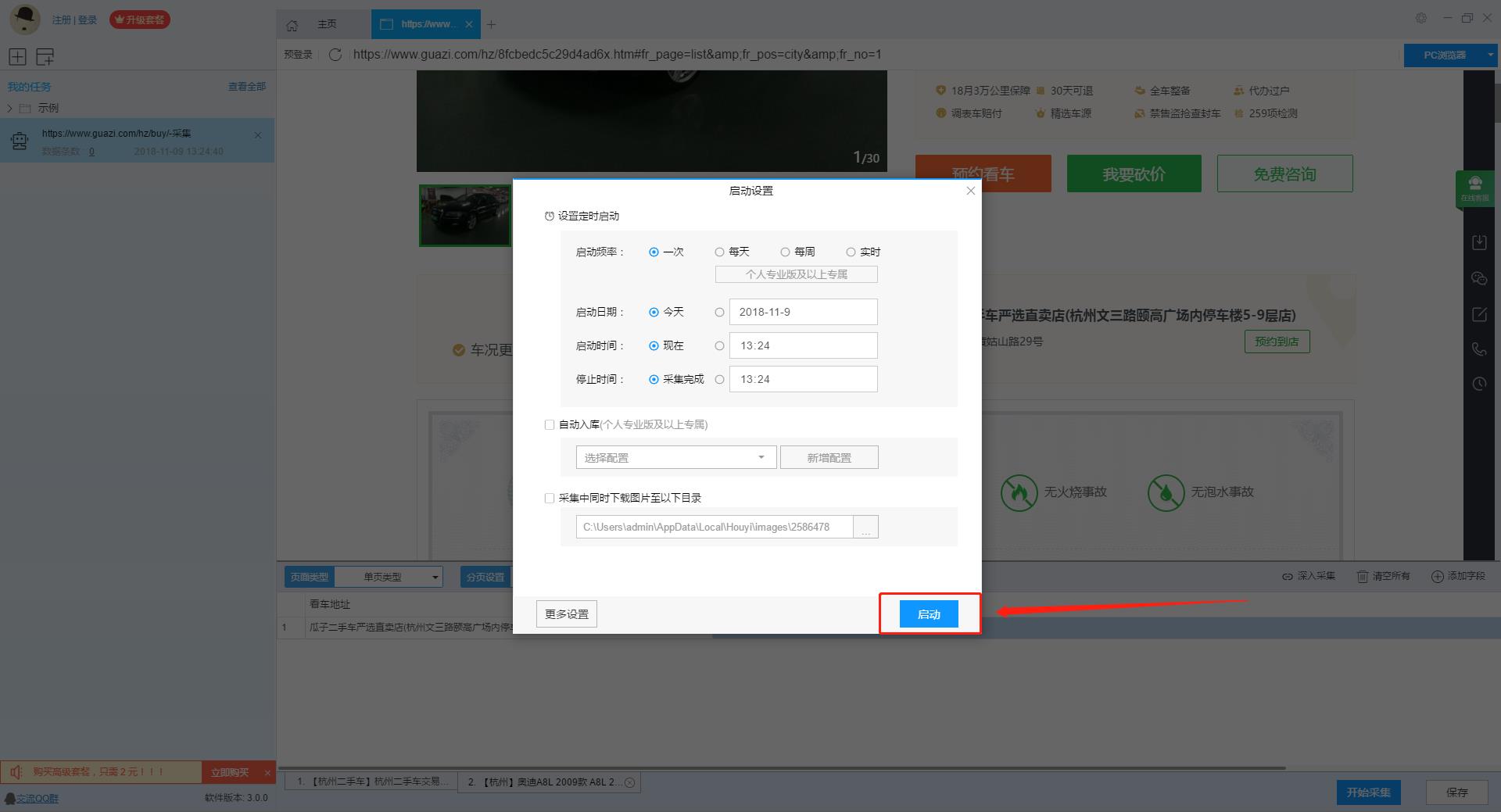
接著點選“儲存並啟動”按鈕,可在彈出的頁面中進行一些高階設定,包括定時啟動、自動入庫和下載圖片,本次示例中未使用到這些功能,直接點選“啟動”執行爬蟲工具。
資料採集完畢後我們匯出資料,軟體支援多種匯出方式,大家可以自由選擇。
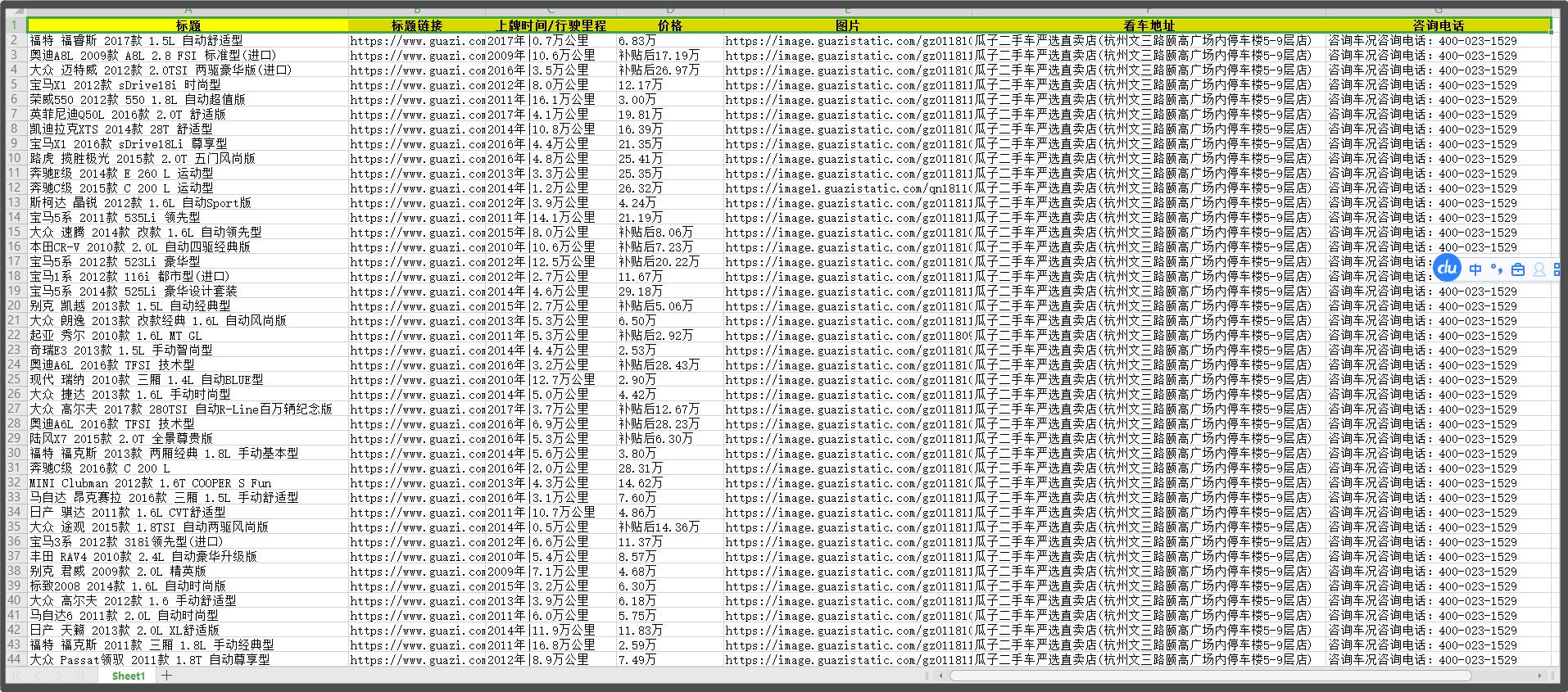
我們匯出一個Excel2007的表格,採集效果如下所示,我們可以看到資料都採集出來了,大家可以直接使用這些資料,也可以在這個基礎上對資料進行加工處理。