
資料聚類

1相似度分析
相似性度量準則是聚類分析用來度量資料之間差異化的一個重要標準。聚類分析中數
據之間相似程度較大,需要按照某種聚類準則進行分離資料。在這樣的一個過程中,需要
使用相似性度量來衡量資料之間的相似及不同。在相似性度量中,距離度量是最常使用的
一個準則,用來衡量資料之間的差異性,一般而言,距離越近的資料相似性越高,距離越
遠的資料相似性越低。
(1)絕對值距離

(2)歐氏距離
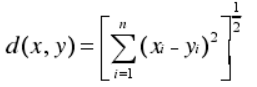
(3)明科夫斯基距離
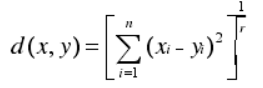
(4)餘弦距離
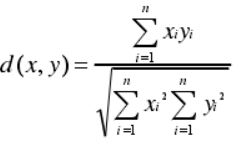
2聚類演算法的分類
不同的問題我們可以嘗試一種或幾種不同的聚類演算法來處理資料集,並觀察資料集的處理結果,可以分析出不用的聚類演算法的優點以及缺陷。主要的聚類演算法可以大致劃分成如下幾類:基於層次聚類、基於劃分聚類、基於密度聚類、基於模糊聚類、基於網格聚類。

(1)劃分聚類的方法
基於劃分聚類的方法,簡單來說,大量的資料在一起,你需要將這裡混合在一起的數
據分離開來,讓其達到聚類效果。首先你需要明確劃分成幾類資料集,然後需要在這些雜
亂的資料中選取初始中心點,依據事先規定好的演算法,將資料按照一定規則,聚集在中心
點附近。一個好的劃分聚類演算法有如下判斷方式:“類內的點都足夠近,類間的點都足夠遠”,
簡單意思就是同類的資料他麼之間的距離儘可能的近,不同類的資料它們之間的距離儘可
能的遠。也可以用闡述成,同類中的資料儘可能的相似,而不同的的資料之間有較大的差
異。
最常用的,K-means演算法流程如下:
基於劃分聚類演算法中,K-means 演算法算是比較經典的演算法,這也是本文在後續實驗部
分所採用的演算法。由於該演算法簡單、收斂速度快、效率高,被廣泛的應用於各個領域中,
並且許多演算法也是圍繞該聚類演算法改進和優化。
對於給定的 n 個物件的資料集,K-means 演算法會以 k 為引數,將其劃分成 k 個簇,聚
類後的結果為k 個聚類中心。相同簇內資料集相似度較高,不同簇之間的資料相似度較低。
該演算法的流程過程如下:
1)給定指定的樣本資料集,從資料集中隨機的選擇k 個初始點作為聚類中心,求解聚
類中心公式如下所示:

上述公式中Ci 為第i 個簇,ni 為Ci 中含的樣本個數,x 為Ci 中的樣本。
2)計算剩餘資料到聚類中心的距離,如若滿足距離公式要求的標準,則將該資料歸於
此聚類簇中。求解距離公式如下:


3)根據劃分後的資料集點重新計算新的聚類中心。
4)判斷新的聚類中心和上一個聚類中心是否有差距,如果有,則繼續操作步驟三,沒
有,輸出聚類劃分結果。
(2)層次聚類的方法
基於層次聚類的方式是對資料集合進行層次上的分解。其原理是對資料點中最為相似
的兩個資料點進行分組,並且反覆這一操作,最終會形成一個層次分明的聚類樹。層次聚
類方法可以分為自下而上合併(凝聚)方法,自下而上分裂方法。凝聚方法原理為將資料
集中的每個物件作為一個簇,然後合併這些簇成為一個新的簇,周而復始,直到達到終止
條件,形成一個自下而上的聚類樹。分裂方法原理是資料集中的所有物件為一個簇,然後
細分化成一個個新的簇,直到滿足終止條件,形成一個自上而下的聚類樹。採用層次聚類
的演算法主要有自下而上聚類AGNES 演算法,自上而下聚類DIANA 演算法。
凝聚層次聚類演算法 :
基於層次聚類的方式是對資料集合進行層次上的分解。其原理是對資料集中最為相似
的兩個資料點進行分組,並且反覆這一操作,最終會形成一個層次分明的聚類樹。層次聚
類方法可以分為自下而上合併方法,自下而上分裂方法。這裡介紹凝聚層次聚類演算法。
該演算法的原理是將將所有資料中的物件作為一個簇,緊接著,合併相似的簇,成為一
個新的簇,直到滿足條件,終止操作。大多數的層次聚類演算法都是屬於凝聚型的,只不過
在定義簇間相似度上有所不同。有如下幾種被廣泛採用度量簇間距離的公式: 
凝聚層次聚類演算法流程如下所示:
1) 將資料集中每個物件看作一類,計算兩兩物件之間的最小距離;
2) 合併距離最小的兩個物件成為一個新的類;
3) 在重新計算合併後新類之間的距離。
4) 直到所有類最後合併成一類或達到終止條件,否則重複(2)、(3)過程,
(3)密度聚類
密度聚類方法的核心思想是某個點附近區域的資料超過一定的閾值,則可以表示該點
是一個核心區域點,位於簇的內部。例如,通過衛星地圖我們可以發現,夜晚的地球是存
在許許多多的燈光源,有的燈光源密度大,燈源亮,有的燈光源密度小,燈源較暗。因此,
我們可以通過燈源的亮暗來區分城市和鄉村,也可以燈源的密度大小來區分城市的大小。
經典的密度聚類演算法則是 DBSCAN 演算法,該演算法可以將高密度的資料集劃分為簇,並且
可以在有噪聲的情況下發現任意形狀的簇類,可以理解為對噪聲不敏感。
(4)網格聚類方法
基於網格聚類方法原理是採用空間驅動,將空間中的資料劃分成一個個小的網格,從
而形成一個網格結構。因為其網格的特性,所有的聚類都在網格上進行,加快了聚類操作
的速度,但由於每個網格的操作可能都不同,所以也會導致準確度的下降。
SOM 聚類演算法
SOM(Self Organizing Maps)是一種基於神經網路的聚類演算法,是一種無監督式的學習算
法。該演算法的特點是隱藏的節點是具有拓撲關係的,而這些拓撲關係需要我們去確定,如
果想到一維模型,需要將這些節點連在一起,成為一條線。如果想要二維的拓撲關係圖,
則需要將這些節點對映稱一個平面[30]。
SOM 聚類演算法包含輸入和輸出層。輸入層用於接受外界的訊息,輸出層則是由二維網
格中的節點構成,而輸入層和輸出層通過權重向量連線。訓練時,採用競爭學習方式,找
出節點之間的最短距離輸出單元。
SOM 聚類演算法流程如下:
1) 初始化網路,對輸入層的節點初始化引數;
2) 從輸入樣本中隨機挑選輸入向量,找到與之相匹配的節點,距離函可採用歐幾里德
距離公式;
3) 定義獲勝單元,跟新臨近節點;
4) 提供新樣本、進行訓練;
5) 更新節點引數、重複,直到滿足終止條件,輸出聚類結果。
(5)模糊聚類方法:
實際上,並不是所有的資料都有一個特定的界限,有些資料之間的關係本就是模糊不
清的。例如對於冷熱的描述,不同的人對冷熱有著不同的看法,資料關係也是一樣。因此,
模糊聚類主要為了解決此種類型的資料。其核心原理是使用模糊數學語言對資料進行一個
模糊量化,讓資料按照這樣的準則進行聚類,使得類之間資料的差異儘可能的大,類中的
資料差異儘可能的小。基於模糊聚類的方法主要是FCM 演算法。
FCM 聚類演算法
FCM聚類演算法屬於模糊集聚類演算法,於1965年美國教授扎德提出模糊集合概念,經過
幾十年的發展,模糊集合受到了廣泛的應用。而FCM聚類演算法也是建立在模糊集合而來,
是一種以隸屬度來確定每個資料點,屬於某個聚類程度的演算法。
FCM聚類演算法流程:
1)隨機初始化資料矩陣A,初始化聚類中心,及距離;
2)計算聚類中心;
3)更新資料矩陣A;
4)檢視是否滿足結果,滿足結束,沒有重複步驟2;
5)根據結果,確定資料所屬聚類中心,顯示聚類結果。
來源: 吳雷明. 基於優化遺傳演算法的聚類分析研究[D].安徽理工大學,2018.