
利用層次聚類演算法進行基於基站定位資料的商圈分析
1.背景與挖掘目標
1.1 背景
隨著個人手機和網路的普及,手機已經基本成為所有人必須持有的工具。
根據手機訊號再地理空間的覆蓋情況結合時間序列的手機定位資料可以完整的還原人群的現實活動軌跡從而得到人口空間分佈於活動聯絡的特徵資訊。
商圈是現代市場中的重要企業活動空間,商圈劃分的目的之一是為了研究潛在的顧客分佈,以制定適宜的商業對策。
本次資料,是由通訊運營商提供的,特定介面解析得到的使用者定位資料。
1.2 挖掘目標
對使用者的歷史定位資料,採用資料探勘技術,對基站進行分群。
對不同的商圈分群進行特徵分析,比較不同商圈類別的價值,選擇合適區域進行鍼對性的營銷活動。
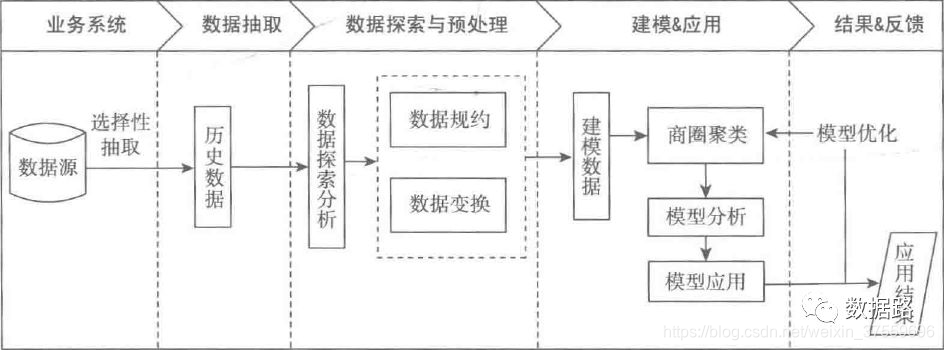
2. 分析方法與過程
2.1 分析方法與步驟
通過資料是由通訊運營商提供,可以推測手機使用者在使用簡訊業務、通話業務和上網業務等資訊時產生的定位資料。
由於資料中是由不同基站作為位置的辨別,可以將每個基站當做一個”商圈“,再通過歸納基站範圍的人口特徵,運用聚類演算法,識別不同類別的基站範圍,即可等同識別不同類別的商圈。
衡量區域人口特徵,可以從人流量和人均停留時間的角度進行分析。
步驟設計:
從行動通訊運營商提供的特定介面進行解析、處理和過濾後得到使用者定位資料
以單個使用者為例子,進行資料探索分析,研究人口特徵,以便於後續資料規約和資料變化的處理方向。
利用步驟2形成的已完成資料預處理的建模資料,基於基站覆蓋範圍區域的人流特徵進行商圈聚類
對分類結果中的各個商圈,進行特徵分析,並且選擇合適的商業計劃。
分析流程:
2.2 資料抽取
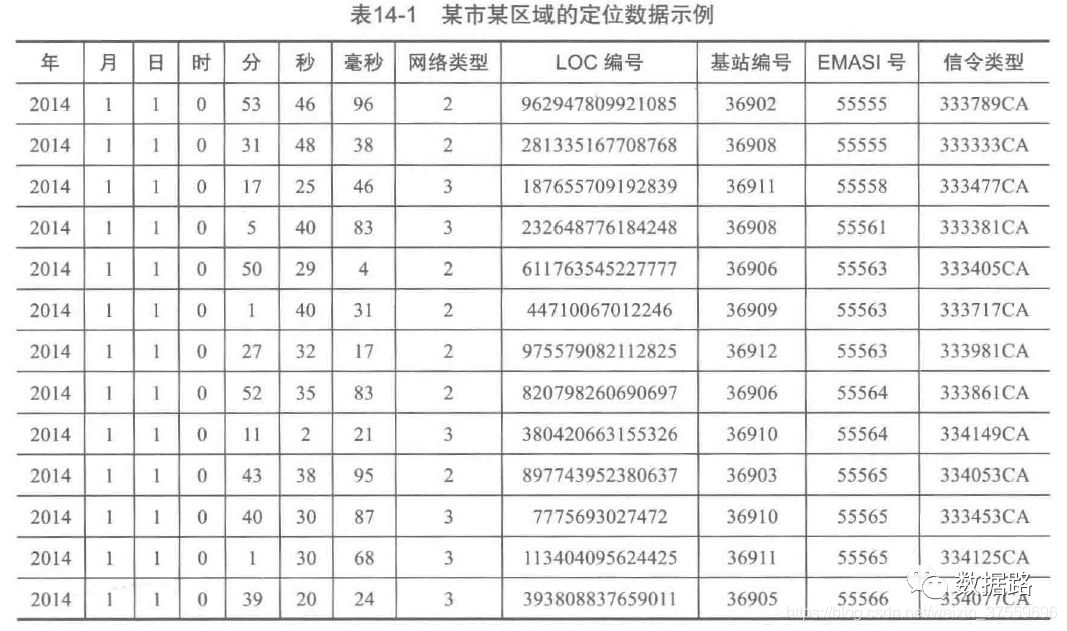
從行動通訊運營商提供的特定介面上解析、處理和過濾後,獲得位置資料。時間設定為,2014-1-1為開始時間,2014-6-30為結束時間作為分析的觀測視窗,抽取視窗內某市某區域的定位資料形成建模資料。
2.3 資料探索分析
為了便於觀察資料,先提取使用者的ID即EMASI號為”55555“的使用者再2014年1月1號的定位資料。
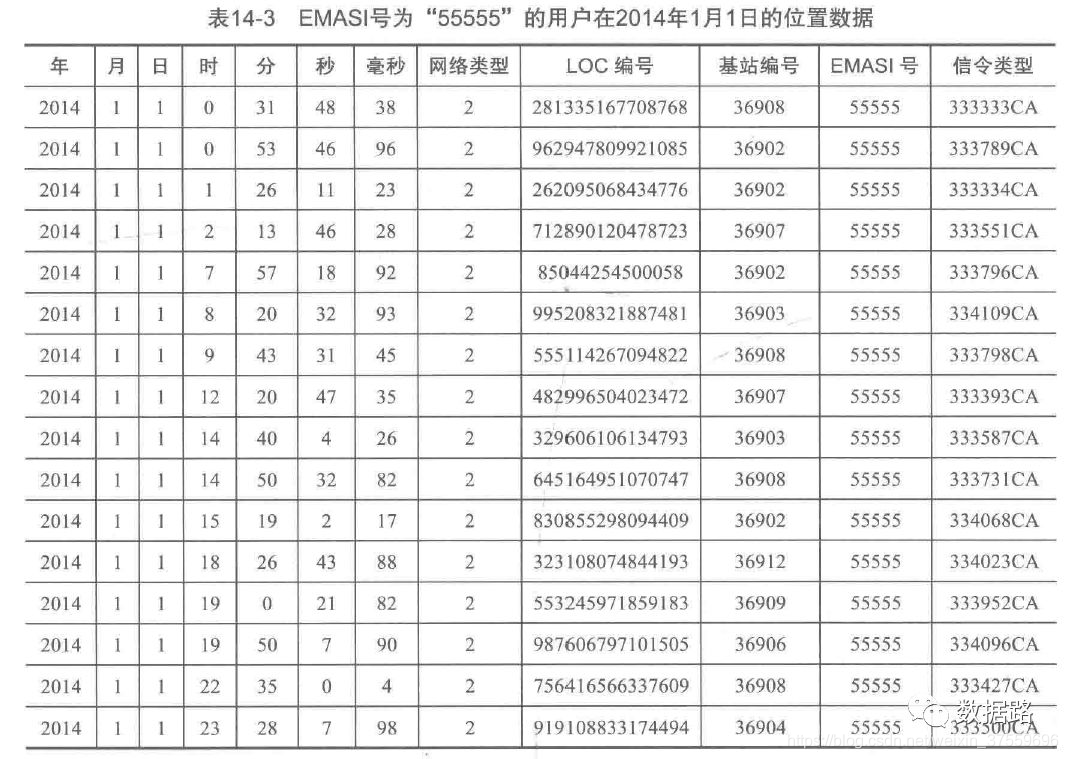
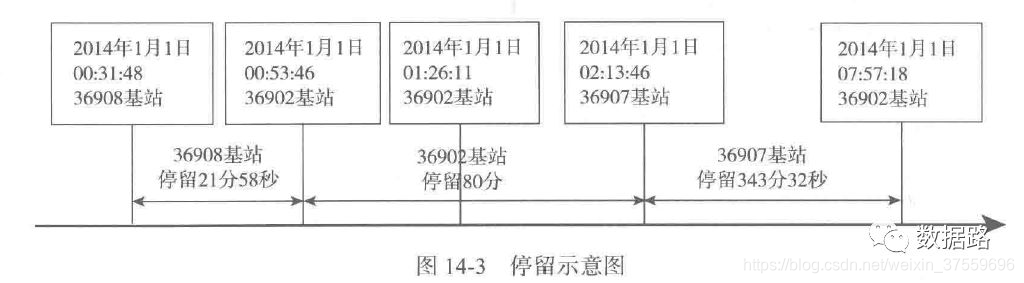
觀察資料,可以發現,兩條資料可能是同一基站的不同時間。
2.4.1 資料規約
原始資料的屬性較多,由我們的挖掘目標,網路型別、LOC編號和信令型別這三個屬性沒有作用,剔除。衡量使用者停留時間,沒有必要精確到毫秒,故一同刪除。
在計算使用者的停留時間,只計算兩條記錄的時間差,為了減少資料維度,把年月日合併為日期,時分秒合併為時間,得到資料。
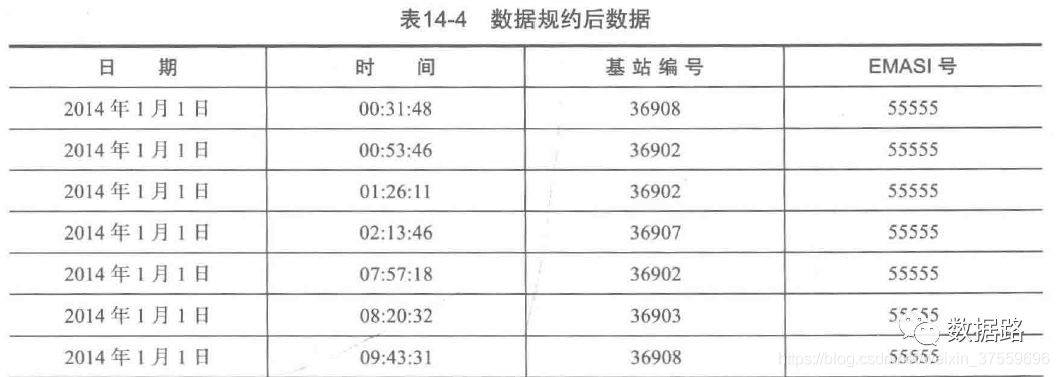
2.4.2 資料變換
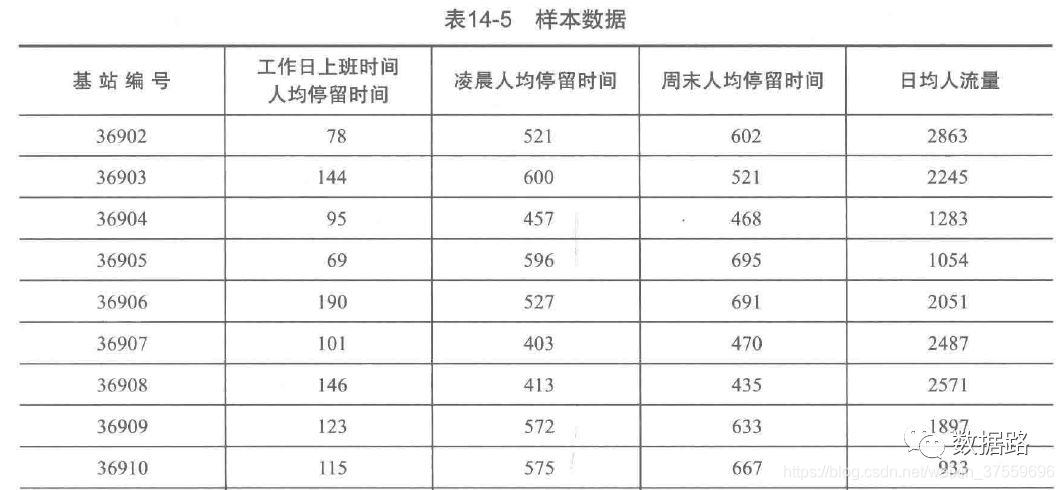
挖掘的目標是尋找高價值的商圈,需要根據使用者的定位資料,提取出基站範圍內區域的人流特徵,如人均停留時間和人流等。
高價值商圈,在人流特徵上有,人流量大和人均停留時間長的特點。
寫字樓的上班族在白天所處基站範圍固定,時間也較長,人流量也大。居住區,也有基站範圍固定,時間長,人流量大的特點。所以,單純的停留時間無法判斷商圈類別。
現代社會工作,以一週為一個工作小週期,分為工作日和週末。一天中,分為上班時間和下班時間。
綜上所述,設計人流特徵的四個指標,工作日上班時間人均停留時間、凌晨人均停留時間、週末人均停留時間和日均人流量。
工作日上班時間人均停留時間,意思是所有使用者在上班時間9:00~18:00處在該基站範圍內的平均時間
凌晨人均停留時間,意思是所有使用者在凌晨時間00:00~07:00處在該基站範圍的平均時間
週末人均停留時間,如上類推。日均人流量,指的是平均每天曾經在該基站範圍內的人數。
這四個指標的計算,直接從原始資料計算比較複雜,需要先處理成中間資料,再從中計算得出四個指標。對於基站1,有以下公式,再帶入所有基站,得出結果。
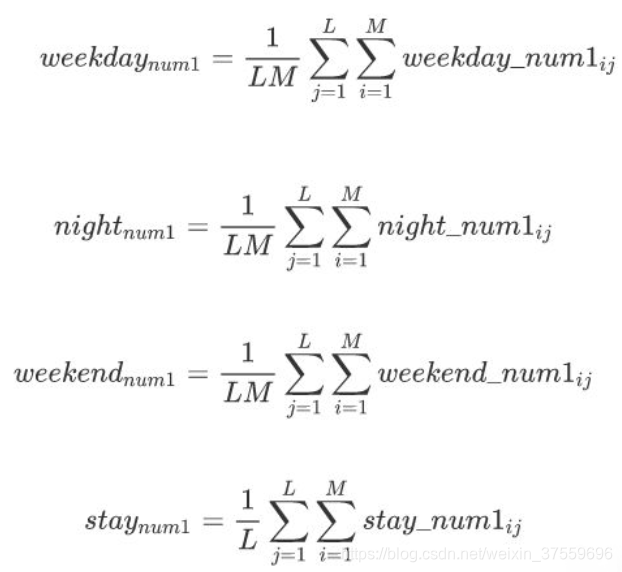
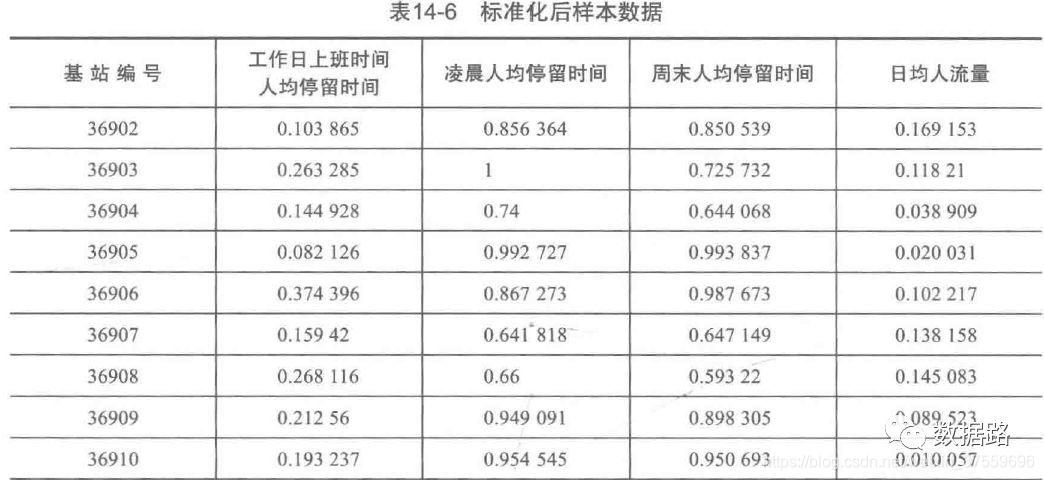
由於各個屬性之間的差異較大。為了消除數量級資料帶來的影響,在聚類之前,需要進行離差標準化處理,離差標準化處理的程式碼如下,得到建模的樣本資料。
#-*- coding: utf-8 -*-
#資料標準化到[0,1]
import pandas as pd
#引數初始化
filename = '../data/business_circle.xls' #原始資料檔案
standardizedfile = '../tmp/standardized.xls' #標準化後資料儲存路徑
data = pd.read_excel(filename, index_col = u'基站編號') #讀取資料
data = (data - data.min())/(data.max() - data.min()) #離差標準化
data = data.reset_index()
data.to_excel(standardizedfile, index = False) #儲存結果
print('OK')
標準化後資料:
2.5 模型構建
2.5.1 構建商圈聚類模型
資料進行預處理以後,已經形成了建模資料。這次聚類,採用層次聚類演算法,對建模資料進行基於基站資料的商圈聚類,畫出譜系聚類圖,程式碼如下。
#-*- coding: utf-8 -*-
#譜系聚類圖
import pandas as pd
#引數初始化
standardizedfile = '../data/standardized.xls' #標準化後的資料檔案
data = pd.read_excel(standardizedfile, index_col = u'基站編號') #讀取資料
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import linkage,dendrogram
#這裡使用scipy的層次聚類函式
Z = linkage(data, method = 'ward', metric = 'euclidean') #譜系聚類圖
P = dendrogram(Z, 0) #畫譜系聚類圖
plt.show()
根據程式碼,得到譜系聚類圖,如圖。
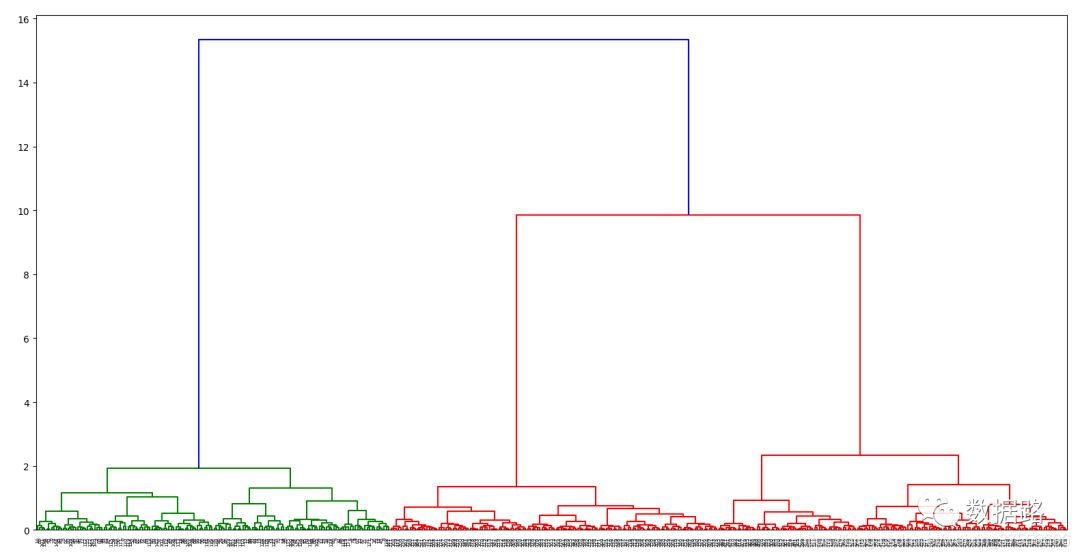
從圖中可以看出,可以把聚類類別數取3類,再使用層次聚類演算法進行訓練模型,程式碼如下。
#-*- coding: utf-8 -*-
#層次聚類演算法
import pandas as pd
#引數初始化
standardizedfile = '../data/standardized.xls' #標準化後的資料檔案
k = 3 #聚類數
data = pd.read_excel(standardizedfile, index_col = u'基站編號') #讀取資料
from sklearn.cluster import AgglomerativeClustering #匯入sklearn的層次聚類函式
model = AgglomerativeClustering(n_clusters = k, linkage = 'ward')
model.fit(data) #訓練模型
#詳細輸出原始資料及其類別
r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #詳細輸出每個樣本對應的類別
r.columns = list(data.columns) + [u'聚類類別'] #重命名錶頭
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用來正常顯示中文標籤
plt.rcParams['axes.unicode_minus'] = False #用來正常顯示負號
style = ['ro-', 'go-', 'bo-']
xlabels = [u'工作日人均停留時間', u'凌晨人均停留時間', u'週末人均停留時間', u'日均人流量']
pic_output = '../tmp/type_' #聚類圖檔名字首
for i in range(k): #逐一作圖,作出不同樣式
plt.figure()
tmp = r[r[u'聚類類別'] == i].iloc[:,:4] #提取每一類
for j in range(len(tmp)):
plt.plot(range(1, 5), tmp.iloc[j], style[i])
plt.xticks(range(1, 5), xlabels, rotation = 20) #座標標籤
plt.title(u'商圈類別%s' %(i+1)) #我們計數習慣從1開始
plt.subplots_adjust(bottom=0.15) #調整底部
plt.savefig(u'%s%s.png' %(pic_output, i+1)) #儲存圖片
最後獲得結果:
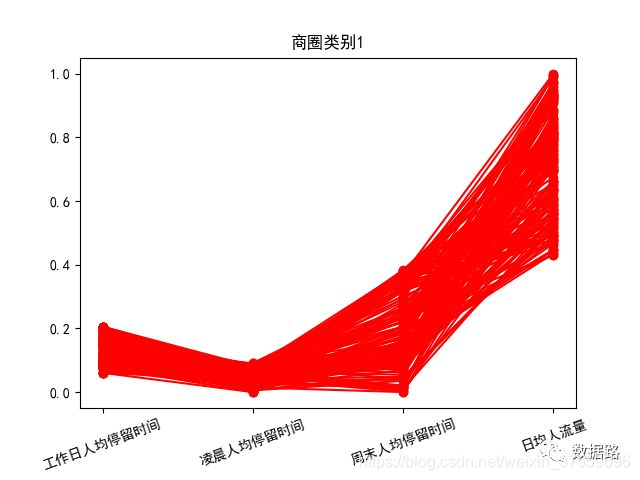
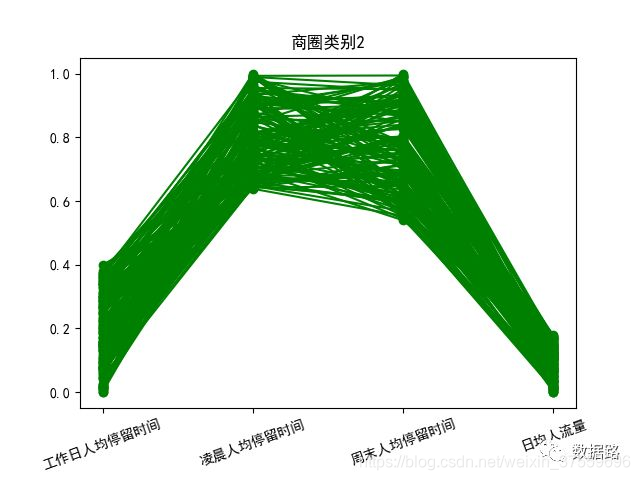
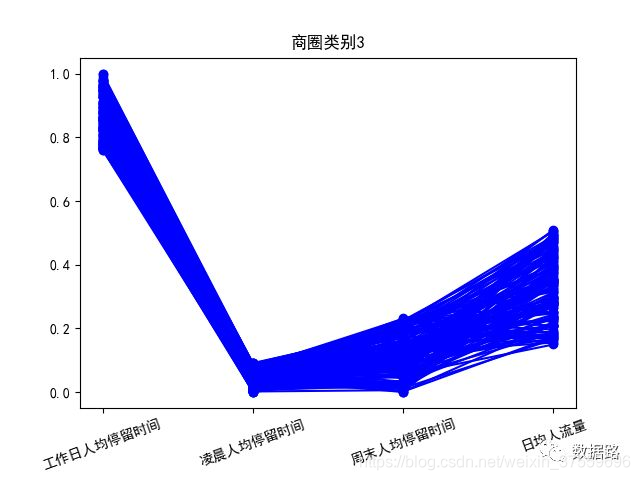
2.5.2 模型分析
針對聚類結果,按不同類別畫出了3個特徵的折線圖,如圖。
商圈類別1,工作日人均停留時間、凌晨人均停留時間都很低,週末人均停留時間中等,日均人流量極高,這符合商業區的特點。
商圈類別2,工作日人均停留時間中等,凌晨和週末人均停留時間很長,日均人流量較低,這和居住區的特徵符合
商圈類別3,這部分工作日人均停留時間很長,凌晨和週末停留較少,日均人流量中等,這和辦公商圈非常符合。
3. 總結
3.1 實驗思考與總結
在得到基礎的建模資料後,通過資料標準化,消除了數量級資料帶來的影響,本案例採用離差標準化。除此之外,還有其他標準化方法嗎?各自的使用範圍與作用由哪些?
本文通過聚類進行了分類,如何通過聚類結果反推得到實際現實中商圈地理位置呢?
兩個演算法模型中,採用的是scipy.cluster和sklearn.cluster這兩個庫。針對構建層次聚類模型,
form sklearn import AgglomerativeClustering 引用這個方法時,由method和metric兩個引數,引數的選擇由哪些?還能進行怎樣的改變呢?對模型的影響又有哪些?
聚類演算法得出模型後,怎樣能檢測模型的效果呢?如何再進一步優化聚類結果?
希望各位看客們,在對待如上疑問有答案或者思路的話,歡迎多多討論,希望能更加完善!
3.2 文章總結
本案例是《Python資料分析與挖掘實戰》中的一個有關商圈商業案例的一個,貼合我們實際的生活,所以更加有興趣解決它。
得到商圈類別以後,反推得到商圈地理位置後,就能根據商業的特點,進行相應的商業活動,比如辦公區附近可以開辦快餐店等,但是,與此同時又牽扯處另外一個問題,通過該商圈特徵能得到使用者的需要,那目前該商圈的供給情況是如何也非常重要!這需要尋找資料,建模,得到相應的情況。最後,在結合商圈服務供給和服務需求後,找到需求比供給多最多的那一個類別,在這個類別上進行商業活動開展會取得好效果。再進一步,商業活動,也能分為不同價格水平的服務供給,可以再通過該商圈的收入水平分佈,而找到能使得總利潤最大化的商業服務。
同時,在遇到公式的書寫時,發現了Latex語法,查詢以後發現還是論文的通用形式,練習了一下Latex的簡單書寫,以後的公式都儘量用這個辦法呈現。
更多案例請關注“思享會Club”公眾號或者關注思享會部落格:http://gkhelp.cn/