
【Semantic Segmentation】Segmentation綜述
部分轉自:https://zhuanlan.zhihu.com/p/37618829
一.語義分割基本介紹
1.1 概念
語義分割(semantic segmentation) : 就是按照“語義”給影象上目標類別中的每一點打一個標籤,使得不同種類的東西在影象上被區分開來。可以理解成畫素級別的分類任務。
輸入: (HW3)就是正常的圖片
輸出: ( HWclass )可以看為圖片上每個點的one-hot表示,每一個channel對應一個class,對每一個pixel位置,都有class數目 個channel,每個channel的值對應那個畫素屬於該class的預測概率。
 figure1
figure1
1.3評價準則
1.畫素精度(pixel accuracy ):每一類畫素正確分類的個數/ 每一類畫素的實際個數。
2.均畫素精度(mean pixel accuracy ):每一類畫素的精度的平均值。
2.平均交併比(Mean Intersection over Union):求出每一類的IOU取平均值。IOU指的是兩塊區域相交的部分/兩個部分的並集,如figure2中 綠色部分/總面積。
4.權頻交併比(Frequency Weight Intersection over Union):每一類出現的頻率作為權重
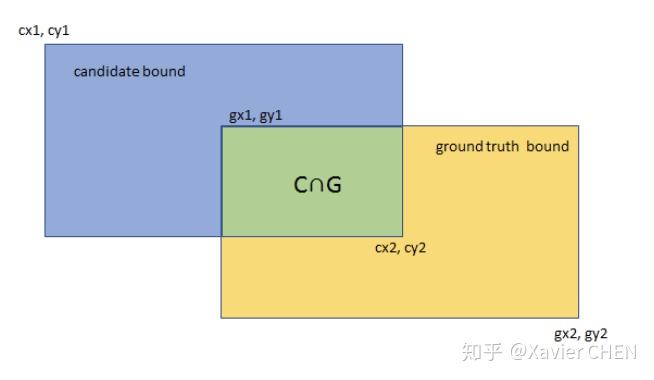 figure2
figure2
二.從FCN 到Deeplab V3+ :語義分割的原理和常用技巧
2.1 FCN
FCN是語義分割的開山之作,主要特色有兩點:
1.全連線層換成卷積層
2.不同尺度的資訊融合FCN-8S,16s,32s
2.1.1 全連線層換成卷積層
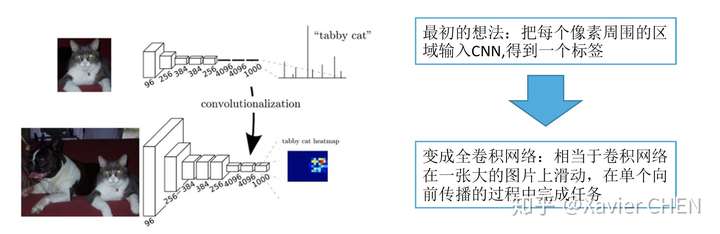 figure3
figure3
以Alexnet的拓撲結構為例
原本的結構:224大小的圖片經過一系列卷積,得到大小為1/32 = 7的feature map,經過三層全連線層,得到基於FC的分散式表示。
我們把三層全連線層全都換成卷積層,卷積核的大小和個數如下圖中間行所示,我們去掉了全連線層,但是得到了另外一種基於不同channel的分散式表示:Heatmap
舉一個例子,我們有一個大小為384的圖片,經過替換了FC的Alexnet,得到的是6*6*1000的Heatmap,相當於原來的Alexnet 以stride = 32在輸入圖片上滑動,經過上取樣之後,就可以得到粗略的分割結果
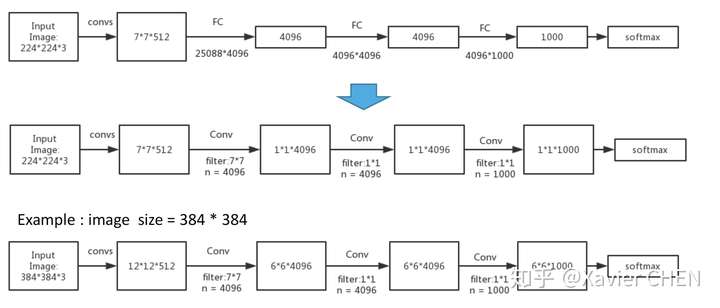 figure4
figure4
2.1.2 不同尺度的資訊融合
就像剛剛舉的Alexnet的例子,對於任何的分類神經網路我們都可以用卷積層替換FC層,只是換了一種資訊的分散式表示。如果我們直接把Heatmap上取樣,就得到FCN-32s。如下圖
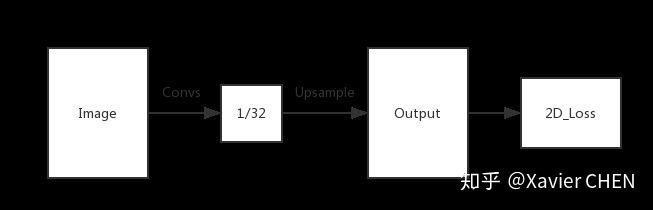 figure5
figure5
但是我們知道,隨著一次次的池化,雖然感受野不斷增大,語義資訊不斷增強。但是池化造成了畫素位置資訊的丟失:直觀舉例,1/32大小的Heatmap上取樣到原圖之後,在Heatmap上如果偏移一個畫素,在原圖就偏移32個畫素,這是不能容忍的。
見figure6,前面的層雖然語義資訊較少,但是位置資訊較多,作者就把1/8 1/16 1/32的三個層的輸出融合起來了。先把1/32的輸出上取樣到1/16,和Pool4的輸出做elementwose addition , 結果再上取樣到1/8,和Pool3的輸出各個元素相加。得到1/8的結果,上取樣8倍,求Loss。
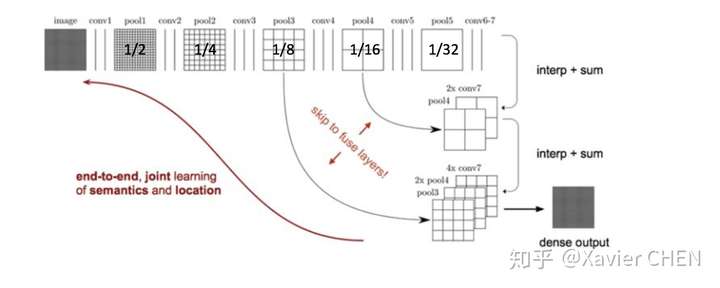 figure6
figure6
2.2 U-net
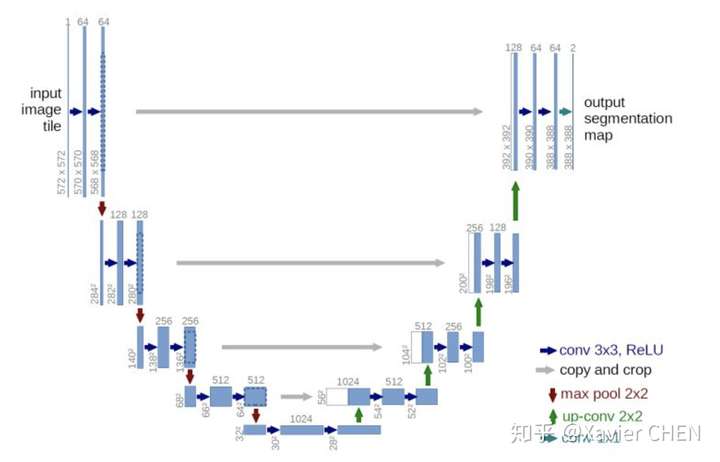 figure7
figure7
U-net用於解決小樣本的簡單問題分割,比如醫療影片的分割。它遵循的基本原理與FCN一樣:
1.Encoder-Decoder結構:前半部分為多層卷積池化,不斷擴大感受野,用於提取特徵。後半部分上取樣回覆圖片尺寸。
2.更豐富的資訊融合:如灰色剪頭,更多的前後層之間的資訊融合。這裡是把前面層的輸出和後面層concat(串聯)到一起,區別於FCN的逐元素加和。不同Feature map串聯到一起後,後面接卷積層,可以讓卷積核在channel上自己做出選擇。注意的是,在串聯之前,需要把前層的feature map crop到和後層一樣的大小。
2.3 SegNet
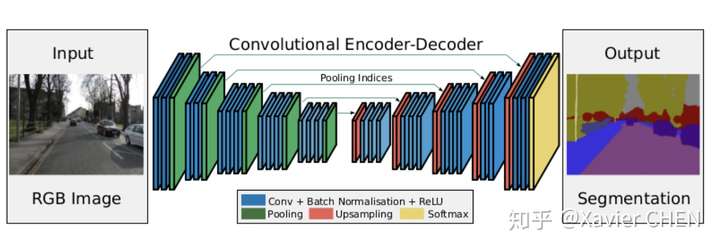 figure 8
figure 8
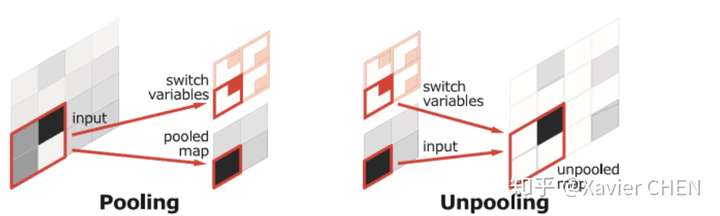
在結構上看,SegNet和U-net其實大同小異,都是編碼-解碼結果。區別在意,SegNet沒有直接融合不同尺度的層的資訊,為了解決為止資訊丟失的問題,SegNet使用了帶有座標(index)的池化。如下圖所示,在Max pooling時,選擇最大畫素的同時,記錄下該畫素在Feature map的位置(左圖)。在反池化的時候,根據記錄的座標,把最大值復原到原來對應的位置,其他的位置補零(右圖)。後面的卷積可以把0的元素給填上。這樣一來,就解決了由於多次池化造成的位置資訊的丟失。
同時採用了大量的啟用層,實驗得出啟用層越多效果越好
2.4 Deeplab V1
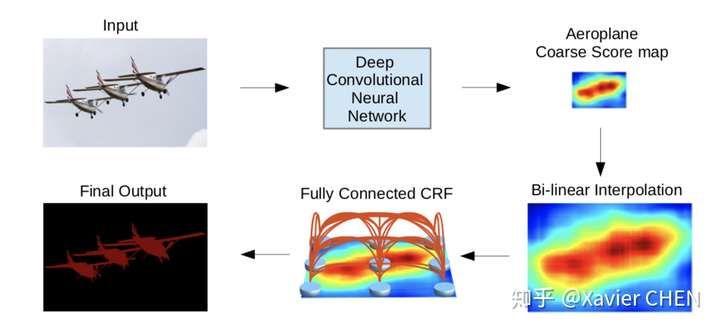 figure10
figure10
這篇論文不同於之前的思路,他的特色有兩點:
1.由於Pooling-Upsample會丟失位置資訊而且多層上下采樣開銷較大,把控制感受野大小的方法化成:帶孔卷積(Atrous conv)
2.加入CRF(條件隨機場),利用畫素之間的關連資訊:相鄰的畫素,或者顏色相近的畫素有更大的可能屬於同一個class。
2.4.1 Atrous Conv
如右下圖片所示,一個擴張率為2的帶孔卷積接在一個擴張率為1的正常卷積後面,可以達到大小為7的感受野,但是輸出的大小並沒有減小,引數量也沒有增大。
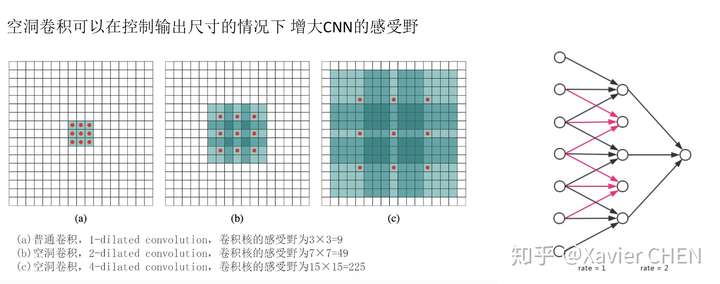 figure 11
figure 11
2.4.2 條件隨機場CRF

2.5 PSPnet
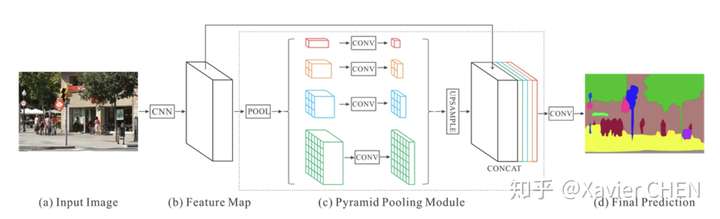 figure12
figure12
原理都大同小異,前面的不同level的資訊融合都是融合淺層和後層的Feature Map,因為後層的感受野大,語義特徵強,淺層的感受野小,區域性特徵明顯且位置資訊豐富。
PSPnet則使用了空間金字塔池化,得到一組感受野大小不同的feature map,將這些感受野不同的map concat到一起,完成多層次的語義特徵融合。
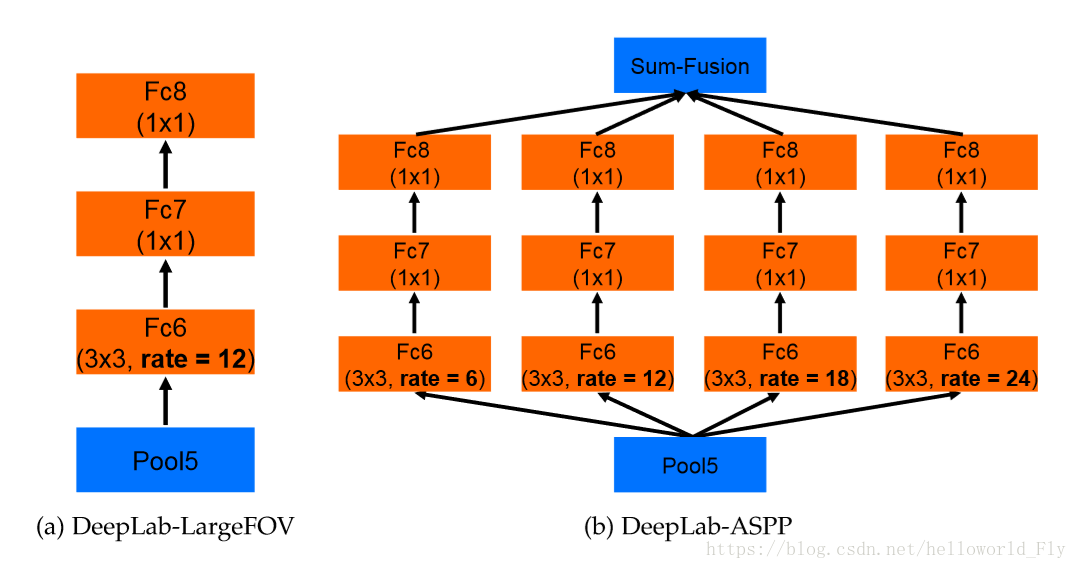
2.6 Deeplab V2
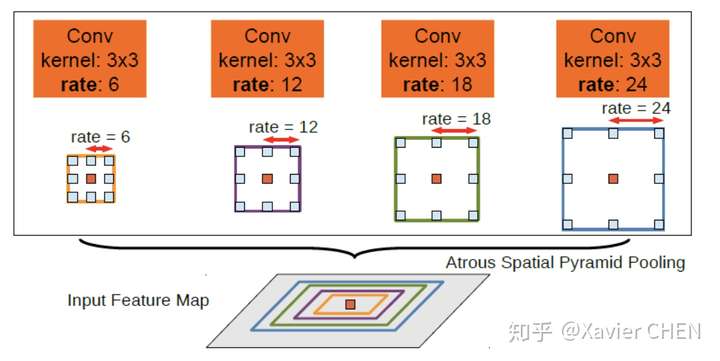 figure 13
figure 13
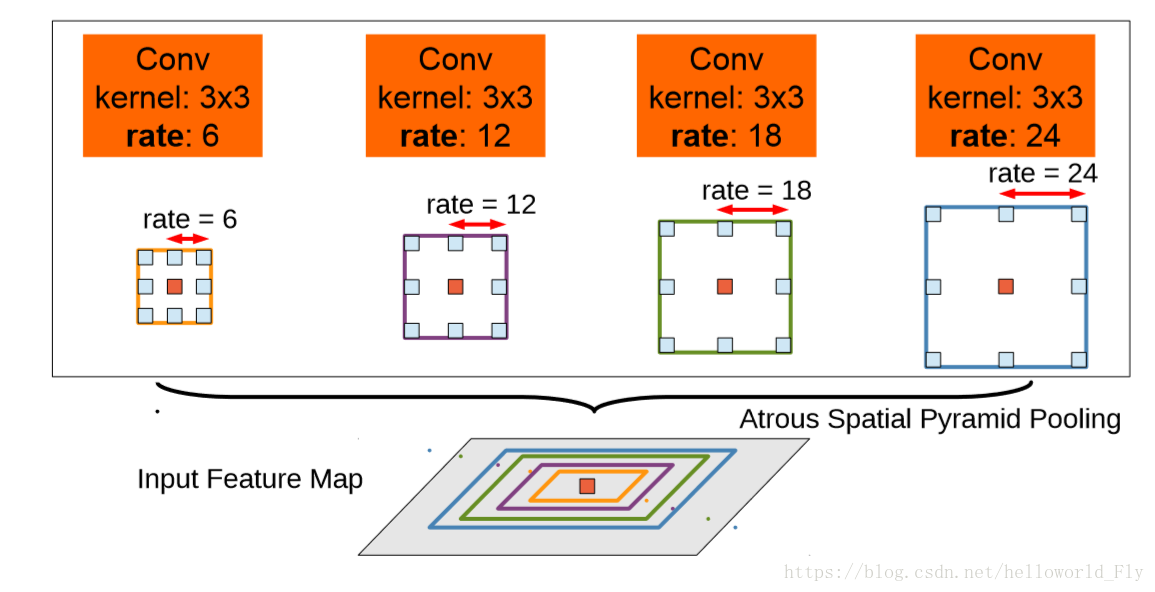
Deeplab v2在v1的基礎上做出了改進,引入了ASPP(Atrous Spatial Pyramid Pooling)的結構,如上圖所示。我們注意到,Deeplab v1使用帶孔卷積擴大感受野之後,沒有融合不同層之間的資訊。
ASPP層就是為了融合不同級別的語義資訊:選擇不同擴張率的帶孔卷積去處理Feature Map,由於感受野不同,得到的資訊的Level也就不同,ASPP層把這些不同層級的feature map concat到一起,進行資訊融合。
方法
i.稠密特徵提取的空洞卷積和感受野的擴充
問題:傳統DCNN但對於連續的最大池化和降取樣導致最後的特徵圖解析度嚴重下降,一般使用FCN,但會帶來增加記憶體和計算時間的問題
解決方法:提出Atrous convolution
Atrous Convolution解釋:
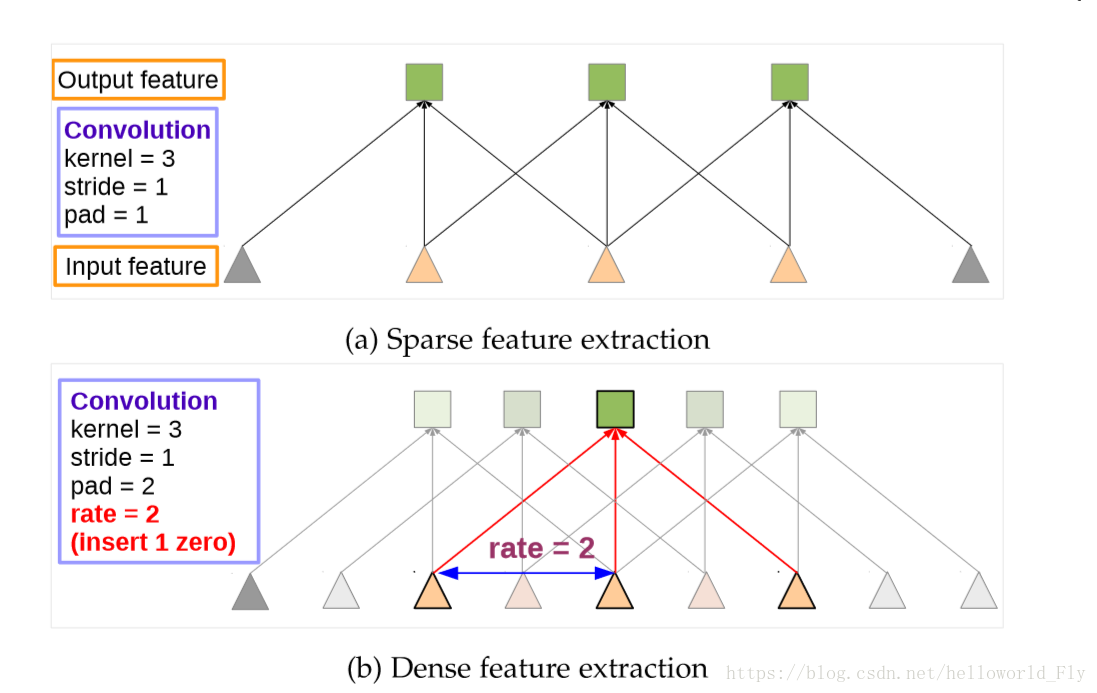
來源於訊號處理,對於輸入訊號,使用長度為K的濾波器加入r取樣率進行取樣:
對於CNN中如果進行降取樣後會出現特徵圖解析度降低,而如果改用Atrous,可有效增加特徵圖解析度。在最後的特徵聚合層,用Atrous代替全連線層。
起初嘗試在所有池化層均加入Atrous,增加效果,但計算量太大;改為factor 4和8,保證計算量和準確度。
方法:a.插入空值,保證計算引數不變;b.提取不同尺度的畫素資訊,插入對應空值,提高感受野的同時能捕捉不同尺度資訊。
問題:(rate如何計算?為何Atrous有效?具體如何實現?)
ii.多尺度空間金字塔池化
ASPP從何而來?為何有效?
借鑑SPP網路,多尺度重取樣可有效增強特徵圖效果。
2.7 Deeplab v3
Deeplab v3在原有基礎上的改動是:
1.改進了ASPP模組
2.引入Resnet Block
3.丟棄CRF
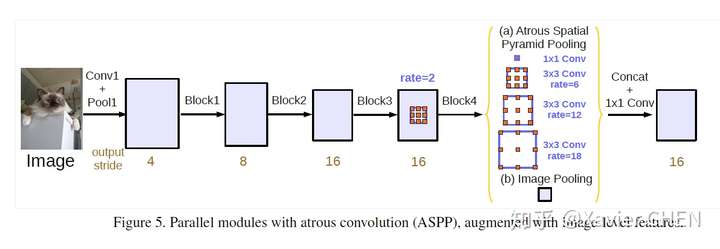 figure14
figure14
- 本文重新討論了空洞卷積的使用,這讓我們在級聯模組和空間金字塔池化的框架下,能夠獲取更大的感受野從而獲取多尺度資訊。
- 改進了ASPP模組:由不同取樣率的空洞卷積和BN層組成,我們嘗試以級聯或並行的方式佈局模組。
- 討論了一個重要問題:使用大采樣率的的空洞卷積,因為影象邊界響應無法捕捉遠距離資訊,會退化為1×1的卷積, 我們建議將影象級特徵融合到ASPP模組中。
- 闡述了訓練細節並分享了訓練經驗,論文提出的”DeepLabv3”改進了以前的工作,獲得了很好的結果
新的ASPP模組:
1.加入了Batch Norm
2.加入特徵的全域性平均池化(在擴張率很大的情況下,有效權重會變小)。如圖14中的(b)Image Pooling就是全域性平均池化,它的加入是對全域性特徵的強調、加強。
在舊的ASPP模組中:我們以為在擴張率足夠大的時候,感受野足夠大,所以獲得的特徵傾向於全域性特徵。但實際上,擴張率過大的情況下,Atrous conv出現了“權值退化”的問題,感受野過大,都已近擴充套件到了影象外面,大多數的權重都和影象外圍的zero padding進行了點乘,這樣並沒有獲取影象中的資訊。有效的權值個數很少,往往就是1。於是我們加了全域性平均池化,強行利用全域性資訊。
2.8 Deeplab v3+
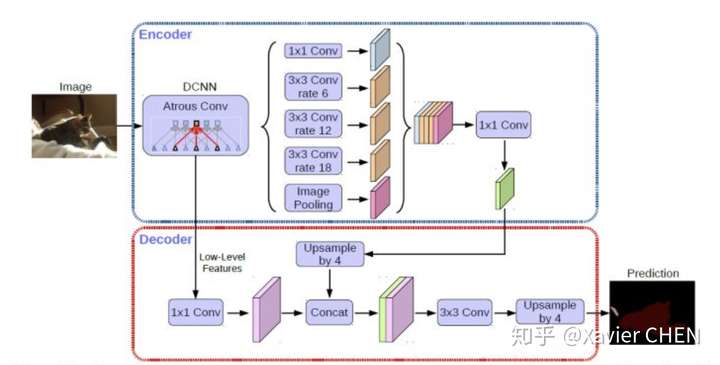
可以看成是把Deeplab v3作為編碼器(上半部分)。後面再進行解碼,並且在解碼的過程中在此運用了不同層級特徵的融合。
此外,在encoder部分加入了Xception的結構減少了引數量,提高執行速遞。關於Xception如何減少引數量,提高速度。建議閱讀論文 : Mobilenet
https://arxiv.org/pdf/1704.04861.pdfarxiv.org
2.9 套路總結
看完這麼多論文,會發現他們的方法都差不多,總結為一下幾點。在自己設計語義分割模型的時候,遵循一下規則,都是可以漲點的。但是要結合自己的專案要求,選擇合適的方法。
1.全卷積網路,滑窗的形式
2.感受野的控制: Pooling+Upsample => Atrous convolution
3.不同Level的特徵融合: 統一尺寸之後Add / Concat+Conv, SPP, ASPP…
4.考慮相鄰畫素之間的關係:CRF
6.在條件允許的情況下,影象越大越好。
5.分割某一個特定的類別,可以考慮使用先驗知識+ 對結果進行影象形態學處理
6.此外還有一些其他的研究思路:實時語義分割,視訊語義分割