
Mark Compact GC (Part one: Lisp2)
阿新 • • 發佈:2018-11-26
目錄
什麼是GC 標記-壓縮演算法
需要對標記清除和GC複製演算法有一定了解
GC標記-壓縮演算法是由標記階段和壓縮階段構成。
標記階段和標記清除的標記階段完全一樣。之後我們要通過搜尋數次堆來進行壓縮。
Lisp2 演算法的物件
Donald E.Knuth
物件結構如圖示:
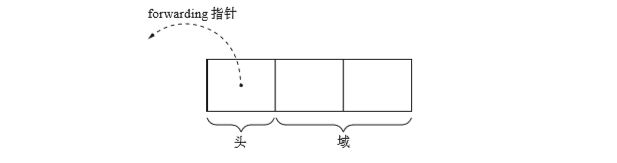
Lisp2 演算法在物件頭中為forwarding指標留出空間,forwarding指標表示物件的目標地點
概要
假設我們在下圖所示的狀態下執行GC
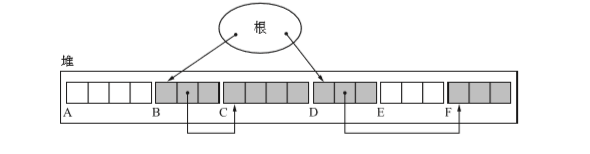
標記完後狀態如下(過程與標記清除演算法相同)
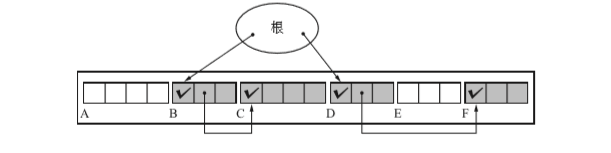
壓縮完後的狀態如下(可以看到,他們現在的位置是挨著的。)
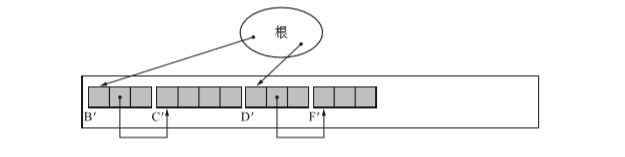
這種演算法並不會對物件的順序產生影響,知識縮小了他們之間的空隙,讓他們聚集在堆的一端。
步驟
壓縮階段程式碼
compaction_phase(){
set_forwarding_ptr() // 設定forwarding指標
adjust_ptr() // 更新指標
move_obj() // 移動物件
}步驟一:設定forwarding指標
首先程式會搜尋整個堆,給活動的物件設定forwarding指標。初始狀態下forwarding是NULL。
set_fowarding_ptr(){
scan = new_address = $heap_start
while(scan < $heap_end)
if(scan.mark = TRUE)
scan.forwarding = new_address
new_address += scan.size
scan += scan.size
}- scan 用來搜尋堆中的指標,new_address指向目標地點的指標。
- 一旦scan找到活動物件,forwarding指標就要被更新。按著new_address物件的長度移動。
- 如下圖示:
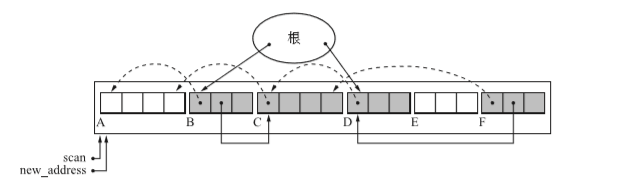
步驟二:更新指標
adjust_ptr(){
for(r :$roots) // 更新根物件的指標
*r = (*r).forwarding
scan = $heap_start
while(scan < $heap_end)
if(scan.mark == TRUE)
for(child :children(scan)) // 通過scan 更新其他物件指標
*child = (*child).forwarding
scan += scan.size
}- 首先更新根的指標
- 然後重寫所有活動物件的指標(對堆進行第二次的搜尋)
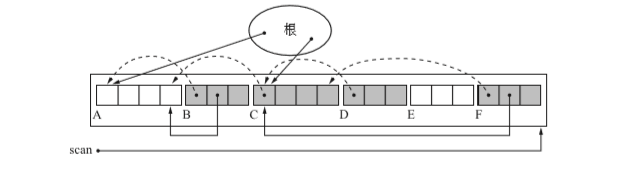
步驟三:移動物件
搜尋整個堆(第三次搜尋),再將物件移動到forwarding指標的引用處。
move_obj(){
scan = $free = $heap_start
while(scan < $heap_end)
if(scan.mark == TRUE) // 判斷是否是活動物件
new_address = scan.forwarding // 獲取物件要移動的地點
copy_data(new_address, scan, scan.size) // 複製物件(移動物件)
new_address.forwarding = NULL // 將forwarding改為NULL
new_address.mark = FALSE // mark改為FALSE
$free += new_address.size // 指標後移
scan += scan.size // 指標後移
}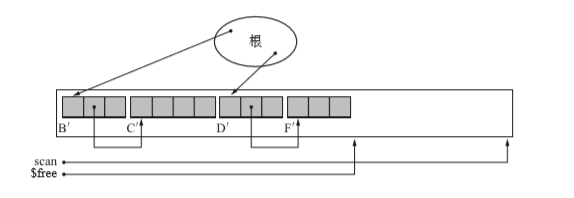
- 演算法不會對物件本身的順序進行改變,只會把物件集中在堆的一端。
- 演算法沒有去刪除物件,知識吧物件的mark設定為FALSE
- 之後把forwarding改為NULL,標誌位改為FALSE,將$free移動obj.size個長度。
優缺點
優點:可有效利用堆
使用整個堆在進行垃圾回收,沒啥說的。任何的演算法都是有得有失,用時間換空間。或者用空間換時間。重要的是它在這裡
適不適用。
缺點:壓縮花費計算成本
Lisp2 演算法中,對堆進行了3次搜尋。在搜尋時間與堆大小成正相關的狀態下,三次搜尋花費的時間是很恐怖。也就是說,它的吞吐量要低於其他演算法。時間成本至少是標記清除的三倍(當然不包含mutator)