
Copying GC (Part two :Multi Space Copying GC)
目錄
近似深度優先搜尋方法
Paul R.Wilson、Michael S.Lam、Thomas G.Moher,1991
這個方法只是近似深度優先搜尋,但可以做到深度優先執行GC複製演算法。
Cheney的GC複製演算法
假設所有物件都是2個字,下圖所示是物件間的引用關係。

下圖所示是執行該演算法時候,各個物件所在的頁面
右上角數字是頁面編號,假如說頁面容量是6個字(只能放3個物件)。

從上圖不難看出,A,B,C是相鄰的,這就是比較理想的狀態。對於其他物件來說,降低了連續讀取的可能性,降低了快取命中率。
在下面1-4頁中,同一個頁面的物件甚至都沒有引用關係(頁面1中D和頁面2中HI,有引用關係,但是不命中,需要讀記憶體資料到catch),這樣就不得不從記憶體上再去讀。一直這樣下去可想而知,有很多的物件會是這樣的分佈狀態。
前提
在這個方法中有下面四個變數。
- $page: 將堆分割成一個個頁面的陣列。$page[i]指向第i個頁面的開頭。
- $local_scan:將每個頁面中搜索用的指標作為元素的陣列。$local_scan[i]指向第i個頁面中下一個應該搜尋的位置。
- $major_scan:指向搜尋尚未完成的頁面開頭的指標。
- $free:指向分塊開頭的指標。
先複製A到To空間,然後複製他們的孩子B,C,都被放置到了0頁。如下圖示:
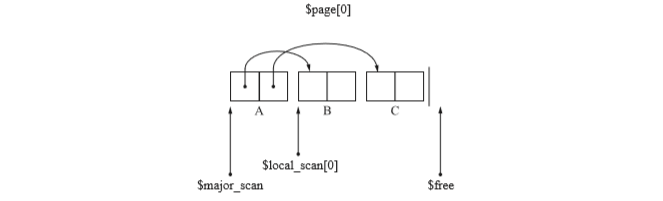
- 因為A已經搜尋完畢,所以$local_scan[0]指向B。
- $free指向第一頁的開頭,也就是說下一次複製物件會被安排在新的頁面。在這種情況下,程式會從$major_scan引用的頁面和$local_scan開始搜尋。
- 當物件被複制到新頁面時,程式會根據這個頁面的$local_scan進行搜尋,直到新頁面物件被完全佔滿為止。
- 此時因為$major_scan還指向第0頁,所以還是從$local_scan[0]開始搜尋,也就是說要搜尋B。

- 複製了D(B引用的物件),放到了$page[1]開頭。像這樣的頁面放在開頭時候,程式會使用該頁面的$local_scan進行搜尋。此時$local_scan[0]暫停,$local_scan[1]開始。之後複製了H,I。
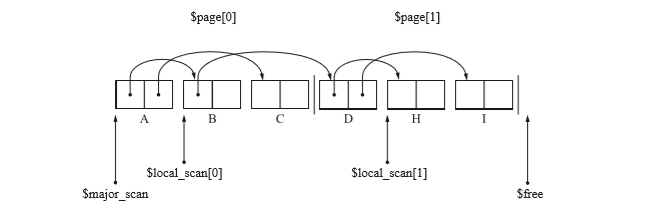
- 這裡第一頁滿了,所以$free指向第二頁開頭。因此$local_scan[1]暫停搜尋,程式$local_scan[0]開始搜尋。(即對B物件再次進行搜尋,看有沒有其他孩子。)
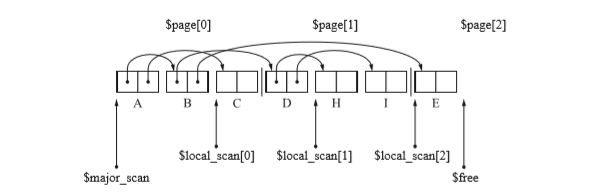
- 可以看到B的孩子E被複制到了$page[2],同樣,對$local_scan[0]再次進行暫停,對E用local_scan[2]進行搜尋。
- 因此複製了J,K。

- 通過對J,K的搜尋頁面2滿了,$free指向了頁面3。再次回到$local_scan[0]進行搜尋。
- 搜尋完物件C,複製完A到O的所有物件之後狀態如下圖所示。
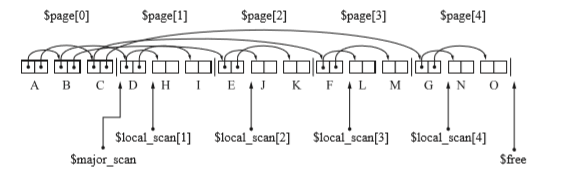
這樣就搜尋完了第0頁($major_scan),雖然還沒有搜尋完子物件,但是孩子沒有孩子,所以現在這個狀態,和搜尋完後是一樣的。
執行結果
該方法是如何安排物件的呢?如下圖示:

很明顯能看出與Cheney的複製演算法不同,不管下一個頁面在哪裡,物件之間都存在引用關係。
該方法,採用了不完整的廣度優先,它實際上是用到了暫停的。從一開始我們就根據關係,然後進行暫停,將有關係的物件安排到了一個頁面中。
多空間複製演算法
GC複製演算法最大的缺點就是隻能利用半個堆。
但是如果我們把空間分成十份,To空間只佔一份那麼這個負擔就站到了整體的1/10。剩下的8份是空的,在這裡執行GC標記清除演算法。
多空間複製演算法,實際上就是把空間分成N份,對其中兩份進行GC複製演算法,對其中(N-2)份進行GC標記-清除。
multi_space_copying()函式
muti_space_copying(){
$free = $heap[$to_space_index]
for(r :$roots)
*r = mark_or_copy(*r)
for(index :0..(N-1))
if(is_copying_index(index) == FALSE)
sweep_block(index)
$to_space_index = $from_space_index
$from_space_index = ($from_space_index +1) % N
}將堆分為N等份,分別是$heap[0],$heap[1]...$heap[N-1]。這裡的$heap[$to_space_index]表示To空間,每次執行GC時,To空間都會像$heap[0],$heap[1]...$heap[N-1],$heap[0],這樣進行替換。Form空間在To空間的右邊,也就是$heap[1]...$heap[N-1]。
- 其中第一個for迴圈,為活動物件打上標記。能看出來是標記清除演算法中的一個階段。
- 其中第一個for迴圈,當物件在From空間時,mark_or_copy()函式會將其複製到To空間,返回複製完畢的物件。如果obj在除Form空間以外的其他地方mark_or_copy()會給其打上標記,遞迴標記或複製它的子物件。
- 其中第二個for迴圈,是清除階段。對除From和To空間外的其他空間,把沒有標記的物件連線到空閒連結串列。
- 最後將To和From空間向右以一個位置,GC就結束了。
mark_or_copy()
mark_or_copy(obj){
if(is_pointer_to_from_space(obj) == True)
return copy(obj)
else
if(obj.mark == FALSE)
obj.mark == TRUE
for(child :children(obj))
*child = mark_or_copy(*child)
return obj
}調查引數obj是否在From空間裡。如果在From空間裡,那麼它就是GC複製演算法的物件。這時就通過copy()函式複製obj,返回新空間的地址。
如果obj不在From空間裡,它就是GC標記-清除演算法的物件。這時要設定標誌位,對其子物件遞迴呼叫mark_or_copy()函式。最後不要忘了返回obj。
copy()
copy(obj){
if(obj.tag != COPIED)
copy_data($free, obj, obj.size)
obj.tag = COPIED
obj.forwarding = $free
$free += obj.size
for(child :children(obj.forwarding))
*child = mark_or_copy(*child)
return obj.forwarding
}遞迴呼叫不是copy()函式,而是呼叫mark_ or_copy()函式。如果物件*child是複製物件,則通過mark_or_copy() 函式再次呼叫這個copy()函式。
執行過程
將記憶體分為4等份。如下圖示:

To空間$heap[0]空著,其他三個都被佔用。這個狀態下,GC就會變為如下如示:
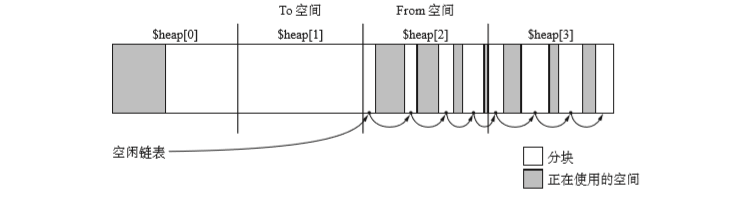
我們將$heap[0]作為To空間,將$heap[1]作為From空間執行GC複製演算法。此外$heap[2]和$heap[3]中執行GC標記-清除演算法,將分塊連線到空閒連結串列。
當mutator申請分塊時候,程式會從空閒連結串列或者$heap[0]中分割出塊給mutator。
接下來,To空間和From空間都向後移動一個位置。mutator重新開始。
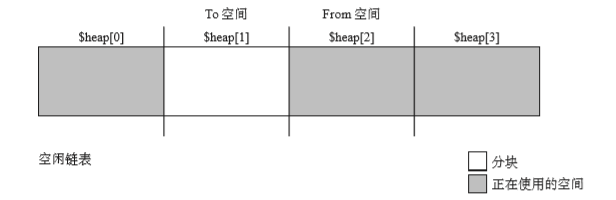
這次$heap[1]是To空間,$heap[2]From空。這種狀態下執行就會變為下圖所示:
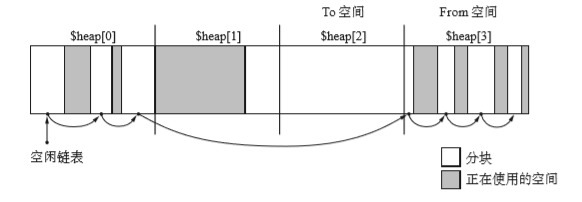
$heap[2]的活動物件都被複制到了$heap[1]中,在$heap[0]和$heap[3]中執行GC標記清除。然後From和To後移一次。
優缺點
優點
提高記憶體利用率:沒有將記憶體空間二等分,而是分割了更多空間。
缺點
GC標記清除,分配耗時,分塊碎片化。當GC標記清除演算法的空間越小的時候,該問題表現的越不突出。例如將記憶體分為3份的情況下。