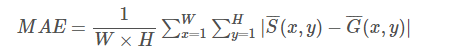深度學習:乳腺 BI-RADS classification ,co-registration ,DoG
paper:BI-RADS Classification of breast cancer:A New pre-processing pineline for deep model training
- BI-RADS:7個分類 0-6
- dataset:InBreast
- pre-trained:Alexnet
- data augmentation :base on co-registraion is suggested,multi-scale enhancement based on difference of Gaussians outperformsusing by mirroing the image
input:original image or pyramid of scales or DoG
augmentation :no data augmentation or proposed method
imbalance:original proportion原始部分 or undersampling下采樣
1、流程:

2、影象擴增 n->n*(n-1)

3、DoG 一通道變成三通道

4、mean basolute error 平均絕對誤差

5、實驗結果
balance :yes or no :original proportion原始部分 or undersampling下采樣

名詞解釋
一、圖片金字塔 pyramid of scales image
影象resize
其實非常好理解,如上圖所示,我們將一層層的影象比喻為金字塔,層級越高,則影象尺寸越小,解析度越低。
兩種型別的金字塔:
- 高斯金字塔:用於下采樣,主要的影象金字塔;
- 拉普拉斯金字塔:用於重建影象,也就是預測殘差(我的理解是,因為小影象放大,必須插入一些畫素值,那這些畫素值是什麼才合適呢,那就得進行根據周圍畫素進行預測),對影象進行最大程度的還原。比如一幅小影象重建為一幅大影象,
影象金字塔有兩個高頻出現的名詞:上取樣和下采樣。現在說說他們倆。
- 上取樣:就是圖片放大(所謂上嘛,就是變大),使用PryUp函式
- 下采樣:就是圖片縮小(所謂下嘛,就是變小),使用PryDown函式
下采樣將步驟:
- 對影象進行高斯核心卷積
- 將所有偶數行和列去除
下采樣就是影象壓縮,會丟失影象資訊。
上取樣步驟:
- 將影象在每個方向放大為原來的兩倍,新增的行和列用0填充;
- 使用先前同樣的核心(乘以4)與放大後的影象卷積,獲得新增畫素的近似值。
上、下采樣都存在一個嚴重的問題,那就是影象變模糊了,因為縮放的過程中發生了資訊丟失的問題。要解決這個問題,就得看拉普拉斯金字塔了。
二、co-registration:影像融合
DoG:Difference of Gaussian 角點檢測
灰度影象增強和角點檢測的方法,其做法較簡單,證明較複雜,具體講解如下:
Difference of Gaussian(DOG)是高斯函式的差分。可以通過將影象與高斯函式進行卷積得到一幅影象的低通濾波結果,即去噪過程,這裡的Gaussian和高斯低通濾波器的高斯一樣,是一個函式,即為正態分佈函式。

那麼difference of Gaussian 即高斯函式差分是兩幅高斯影象的差,
一維表示:
二維表示:
具體到影象處理來講,就是將兩幅影象在不同引數下的高斯濾波結果相減,得到DoG圖。
1. 處理一幅影象在不同引數下的DoG
-
A = Process(Im, 0.3, 0.4, x); B = Process(Im, 0.6, 0.7, x); a = getExtrema(A, B, C, thresh);其中,
-
function [ out_img ] = Process( img, sig1, sig2, size )
是求影象DoG的結果,兩個高斯平滑引數分別為sig1和sig2,結果如下:
-
A = Process(Im, 0.3, 0.4, x);

- B = Process(Im, 0.6, 0.7, x);

- C = Process(Im, 0.7, 0.8, x);

2. 根據DOG求角點
Theory:DOG三維圖中的最大值和最小值點是角點
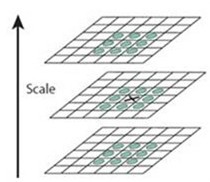
X標記當前畫素點,綠色的圈標記鄰接畫素點,用這個方式,最多檢測26個畫素點。X被標記為特徵點,如果它是所有鄰接畫素點的最大值或最小值點。
因此在上一步計算出的A,B,C三個DOG圖中求圖B中是極值的點,並標記(max:1;min:-1)
- a = getExtrema(A, B, C, thresh);
- figure;
- imshow(a, [-1 1]);
結果:
黑色為極小值,白色為極大值

最後在原圖上予以顯示:

就得到了一幅圖的DOG角點檢測結果。
三、mean basolute error 平均絕對誤差
1、顯著性目標檢測簡介
顯著性目標(Salient Object):
當我們在看一張圖片時,注意力首先會落在我們所感興趣的物體部分。比如我們看到一張畫有羊吃草的影象時,我們一般會先注意草坪上的羊,而不是羊的背景,所以我們把該圖中的羊就定義為影象的顯著性目標。
顯著性目標檢測(Salient Object Detection):
即讓計算機學會跟人類一樣,自動檢測並提取輸入影象中的顯著性目標。
評價指標(Evaluation Metrics):
顯著性目標檢測演算法常用的評價指標有:平均絕對誤差(Mean Absolute Error, MAE),PR曲線(Precision-Recall curves)以及F度量值(F-measure)。
這些度量指標我會依次介紹並程式設計實現,在本篇部落格中,主角是平均絕對誤差(Mean Absolute Error, MAE)。
2、Mean Absolute Error(MAE) 原理
MAE就是直接計算模型輸出的顯著性圖譜與Ground-truth 之間的平均絕對誤差,首先將兩者進行二值化,然後用下面的公式進行計算 [1]。