
【機器學習】演算法原理詳細推導與實現(七):決策樹演算法
阿新 • • 發佈:2020-08-22
# 【機器學習】演算法原理詳細推導與實現(七):決策樹演算法
在之前的文章中,對於介紹的分類演算法有[邏輯迴歸演算法](https://www.cnblogs.com/TTyb/p/10976291.html)和[樸素貝葉斯演算法](https://www.cnblogs.com/TTyb/p/10989082.html),這類演算法都是二分類的分類器,但是往往只實際問題中$y$不僅僅只有$\{0,1\}$,當出現一個新的類別$y=2$時,之前的分類器就不太適用,這裡就要介紹一個叫做**決策樹**的新演算法,該演算法對於多個目標的離散特徵往往有比較好的分類效果,用以解決$x$是離散型的資料,這是判別模型,也是一個生成學習演算法。
## ID3決策樹
### 熵
假設當前網上有很多機器學習的教程,我想學機器學習,但是不知道哪一個教程比較好;又或者想買一個榴蓮,不知道哪一隻肉比較厚實,不知道該挑那一隻,對於這種不確定性就叫做熵。
**當一個事情有多種可能情況時,這件事情對於觀察人而言具體是哪種情況的不確定性叫做熵。**
### 資訊
當你不知道選擇哪一篇教程來學習機器學習時,有人和你說TTyb的機器學習教程很好,這個人對你提供的**TTyb的機器學習教程很好**就是資訊;又或者在買榴蓮的時候,賣榴蓮的人和你說這個榴蓮的肉肯定很厚實,賣榴蓮的人和你說的**這個榴蓮的肉肯定很厚實**就是資訊。當某件事情存在不確定性,能夠消除觀察人對於某件事情的不確定性,也就是前面說的熵,能夠消除不確定性的事物叫做資訊。
**資訊有很多種表現形式,能夠調整不確定的概率的事物可以叫做資訊**
例如賣榴蓮的老闆說有很大概率這個榴蓮的肉可能很厚實;能夠排除干擾的事物可以叫做資訊,例如賣榴蓮的老闆說這個榴蓮殼厚,肉肯定小不要選擇這個;能夠確定情況的事物可以叫做資訊,賣榴蓮的老闆說這個榴蓮肉肯定很厚實,開了不厚實算我的。
**熵和資訊數量相等,意義相反,獲取資訊意味著消除了不確定性熵。**
### 資訊熵
假設有4個榴蓮只有一個肉是厚實的,老闆和你說榴蓮A的肉不厚實,給你提供了$0.4bit$的資訊,榴蓮B的肉不厚實,給你提供了$0.6bit$的資訊,榴蓮C的肉不厚實,給你提供了$1bit$的資訊,最後讓你確定了榴蓮D肉是厚實的。老闆每次都給你提供了一次資訊,為什麼提供的資訊量卻是不一樣的?資訊是如何量化的?回想一下什麼東西有單位,質量、溫度等物理量,資訊也是一個物理量,要測量這個物理量,不妨回想一下我們是怎樣測量質量的,“千克”最初又是怎麼被定義出來的。

其實我們最初並不知道千克的質量,而是選定了一個參照物,把這個物體的質量就稱為*千克*。當想要測量其他物體的質量時,就看這個物體的質量相當於多少個參照物體的質量,這裡的“多少個”便是千克,如果參照物體換成“斤”,那麼單位就會變化。
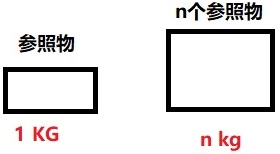
測量資訊也是一樣,既然資訊消除的是不確定性,那麼就選擇另外一個事件的不確定性作為參照事件,當想要測量其他事件的資訊時,就看待測事件的不確定性相當於“多少個”參照事件的不確定性,這裡的多少個便是資訊量。即待測物體質量為$m$,參照物體個數(資訊量)為$n$,參照物體質量(千克)為$x$,那麼:
$$
m=n\times x
$$
#### 均勻分佈的資訊熵
當選擇的參照物事件是像拋硬幣這樣,只有兩種等概率情況的事件時,測得的資訊量的單位就被稱為位元(bit),然而測量參照物體個數(資訊量)$n$時,我們是用待測物體質量$m$除以參照物體質量(千克)$x$,即:
$$
n=\frac{m}{x}
$$
可是測量資訊時卻不能用除法,因為拋擲3個硬幣能夠產生的等可能結果並非$3\times 2=6$,而是$2^3=8$種,也就是說資訊量不是線性關係,而是指數關係:
```
|正正正|反正正|
|正反正|正正反|
|反反正|反正反|
|正反反|反反反|
```
所以當知道可能情況的個數$m$,想求這些情況相當於多少個$n$參照事件$x$所產生的,用指數運算的反函式,即對數運算計算:
$$
n=log_xm
$$
而這裡硬幣只有正面和反面,那麼這裡的參照事件$x=2$,公式變換為:
$$
n=log_2m
$$
上面的式子代表,在拋硬幣的實驗中,假設8個不確定情況就相當於3個硬幣丟擲來結果$3=log_28$,即資訊量為$3bit$;4個不確定情況就相當於2個硬幣丟擲來結果$2=log_24$,即資訊量為$2bit$。
#### 一般分佈的資訊熵
而上面講的時拋擲硬幣,被測事件的所有可能情況都是等概率事件,但是如果存在如下假設,*這裡有4個榴蓮,只有一個榴蓮的肉是厚實的,其他3個榴蓮的肉是不厚實的*:
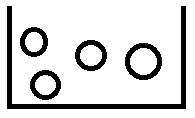
那麼買到肉是厚實榴蓮的不確定性(資訊熵)為$log_24=2bit$,因為這裡可能情況的個數$m=4$,所以不確定性是$2bit$。但是如果老闆和你說最大的那個(最右邊圓圈)榴蓮有50%概率是肉厚的,那麼從概率上來說買最大的那個(最右邊圓圈)是肉厚的概率為$\frac{1}{2}$,取出不是肉厚的概率是$\frac{1}{3}\times \frac{1}{2}$,這裡代表剩下3個榴蓮要瓜分剩下的$\frac{1}{2}$概率,所以剩下3個榴蓮每個的概率是$\frac{1}{6}$,這時候各個情況的概率不一樣了:
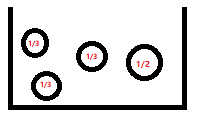
這時該如何計算總資訊量了呢?這時候就要分別測量每種可能情況的資訊量後,乘以他們各自發生的概率再相加即可,即這時候買到肉厚的榴蓮的不確定性(資訊熵)為:
$$
\frac{1}{6}log_2m_1+\frac{1}{6}log_2m_2+\frac{1}{6}log_2m_3+\frac{1}{2}log_2m_4
$$
不過怎麼測量每種情況的資訊量$log_2m$呢,怎麼知道概率為$\frac{1}{6}$的情況的不確定性相當於拋擲多少個硬幣所產生的不確定性呢?我們確實沒有辦法用$log_2m$這個公式了,但是我們知道$1%$會發生的情況,相當於從100個等概率情況中確定實際情況,即$p=1%=frac{1}{100}$,概率的倒數等於等概率情況的個數,即$m=\frac{1}{100}=\frac{1}{p}$,用概率的倒數$\frac{1}{p}$替換等概率情況的個數$m$後,我們就可以計算每種情況的資訊量了:
$$
m_1=\frac{1}{\frac{1}{6}},m_2=\frac{1}{\frac{1}{6}},m_3=\frac{1}{\frac{1}{6}},m_4=\frac{1}{\frac{1}{2}}
$$
再用每個情況的資訊量乘以對應事件發生的概率,再相加後就能算出總資訊量了:
$$
\frac{1}{6}log_2\frac{1}{\frac{1}{6}}+\frac{1}{6}log_2\frac{1}{\frac{1}{6}}+\frac{1}{6}log_2\frac{1}{\frac{1}{6}}+\frac{1}{2}log_2\frac{1}{\frac{1}{2}}=1.79bit
$$
由此可得到,任何隨機變數$X$資訊熵為:
$$
H(X)=\sum_{i=1}^n p_ilog_2\frac{1}{p_i}
$$
### 資訊增益
既然任何隨機變數$X$資訊熵為:
$$
H(X)=\sum_{i=1}^n p_ilog_2\frac{1}{p_i}
$$
那麼假設$p$是隨機變數$X$發生的概率,如果存在多個變數$X$和$Y$,則他們的聯合熵為:
$$
H(X,Y)=\sum_{i=1}^n p(x_i,y_i)log_2p(x_i,y_i)
$$
其中$p(x_i,y_i)$代表事件$X=x$和$Y=y$一起出現的聯合概率。有了聯合熵,又可以得到條件熵的表示式$H(X|Y)$,條件熵類似於條件概率,當事件$Y$發生過後,事件$X$還剩下的不確定性(資訊熵):
$$
\begin{split}
H(X|Y)&=\sum_{y} p(y)H(X|Y=y) \\
&=-\sum_{y} p(y)\sum_{x}p(x|y)log(p(x|y)) \\
&=-\sum_{y}\sum_{x}p(x,y)log(p(x|y)) \\
&=-\sum_{x,y}p(x,y)log(p(x|y))
\end{split}
$$
其中$H(X|Y)=H(X,Y)−H(Y)$,資訊熵和資訊增益的關係如下圖所示:
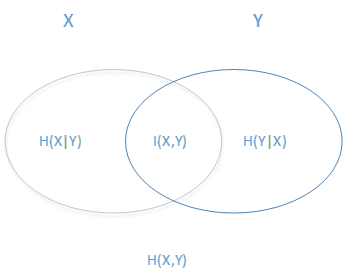
左邊的橢圓代表隨機變數$X$的資訊熵$H(X)$,右邊的橢圓代表隨機變數$Y$的資訊熵$H(Y)$,中間重合的部分就是資訊增益$I(X,Y)$, 左邊的橢圓去掉重合部分就是$H(X|Y)$,右邊的橢圓去掉重合部分就是$H(Y|X)$,兩個橢圓的並就是$H(X,Y)$,由此可以得到資訊增益的公式為:
$$
I(X,Y)=H(X)−H(X|Y)
$$
回到最初的問題,當4個榴蓮中不知道那個是肉厚的榴蓮的時候,隨機變數$X=肉厚$,不確定性(資訊熵)的套用公式為:
$$
\begin{split}
H(X)&=\sum_{i=1}^n p_ilog_2\frac{1}{p_i} \\
&=\frac{1}{4}log_2\frac{1}{\frac{1}{4}}+\frac{1}{4}log_2\frac{1}{\frac{1}{4}}+\frac{1}{4}log_2\frac{1}{\frac{1}{4}}+\frac{1}{4}log_2\frac{1}{\frac{1}{4}} \\
&=2
\end{split}
$$
假設每個榴蓮從左到右記為隨機變數$X1$、$X2$、$X3$、$X4$,老闆告訴說最大的那個$X4$(最右邊圓圈)榴蓮有50%概率是肉厚的,即提供了資訊$Y$,求肉厚的資訊熵。這時候先計算的資訊熵為條件熵$H(X|Y)$:
$$
\begin{split}
H(X|Y)&=H(X1)+H(X2)+H(X3)+H(X4|Y=y) \\
&=\frac{1}{6}log_2\frac{1}{\frac{1}{6}}+\frac{1}{6}log_2\frac{1}{\frac{1}{6}}+\frac{1}{6}log_2\frac{1}{\frac{1}{6}}+\frac{1}{2}log_2\frac{1}{\frac{1}{2}} \\
&=1.79bit
\end{split}
$$
最後由總的不確定性(資訊熵)減去後面的不確定性(資訊熵),得到老闆說的話“最大的那個(最右邊圓圈)榴蓮有50%概率是肉厚的”提供的資訊為:
$$
\begin{split}
I(X,Y)&=H(X)−H(X|Y) \\
&=2-1.79 \\
&=0.21bit
\end{split}
$$
提供的資訊$0.21bit$也叫做**資訊增益**
### ID3決策樹演算法步驟
輸入的是$m$個樣本,樣本輸出集合為$X$,每個樣本有$n$個離散特徵,特徵集合即為$Y$,輸出為決策樹$T$。例如存在樣本如下所示:
| 天氣 | 氣溫 | 溼度 | 風力 | 外出 |
|:----:|:----:|:----:|:----:|:----:|
| 晴朗 | 高溫 | 高 | 無風 | 否 |
| 晴朗 | 高溫 | 高 | 有風 | 否 |
| 多雲 | 高溫 | 高 | 無風 | 是 |
| 下雨 | 溫暖 | 高 | 無風 | 是 |
| 下雨 | 寒冷 | 正常 | 無風 | 是 |
則樣本數量$m=5$;輸出集合為`是`或者`否`,即$X_1=是,X_2=否$;每個樣本的離散特徵為$n=4$,即`天氣`、`氣溫`、`溼度`、`風力`;特徵集合為$Y$,當離散特徵$Y'$是`天氣`時,特徵集合$Y_i$為`{晴朗,多雲,下雨}`。演算法的過程為:
>1. 計算$m$中的各個特徵(一共$n$個)對輸出$X$的資訊增益,選擇資訊增益最大的特徵$Y'$,其中$Y' \in Y$
>2. 按特徵$Y'$的不同取值$Y_i$將對應的樣本輸出$X$分成不同的類別$X_i$,其中$i \in n$。每個類別產生一個子節點。對應特徵值為$Y_i$。返回增加了節點的數$T$。
>3. 對於所有的子節點,令$X=X_i,m=m−\{Y'\}$遞迴呼叫1-2步,得到子樹$T_j$並返回。
## C4.5決策樹
ID3演算法雖然提出了新思路,但是還是有如下4點需要改進的地方:
>1. ID3沒有考慮連續特徵,比如長度、密度都是連續值,無法在ID3運用,這大大限制了ID3的用途。--資料分箱即可解決
>2. ID3採用資訊增益大的特徵優先建立決策樹的節點,但資訊增益準則對可取值數目較多的屬性有所偏好。
>3. 演算法對於缺失值的情況沒有做考慮。--特徵工程即可解決
>4. 沒有考慮過擬合的問題。--預剪枝和後剪枝
對於上面的第2點需要做一下解釋。從上面可以知道,ID3資訊增益的計算公式為:
$$
I(X,Y)=H(X)−H(X|Y)
$$
資訊增益的大小取決於隨機變數$Y$資訊熵的大小,$H(X|Y)$越小則資訊增益越大,而什麼情況下$H(X|Y)$會有極小的資訊熵呢?舉一個極端的例子,如果上面的例子中,變數天氣的特徵互不相同變成:
| 天氣 | 氣溫 | 溼度 | 風力 | 外出 |
|:----:|:----:|:----:|:----:|:----:|
| 大晴 | 高溫 | 高 | 無風 | 否 |
| 小晴 | 高溫 | 高 | 有風 | 否 |
| 多雲 | 高溫 | 高 | 無風 | 是 |
| 大雨 | 溫暖 | 高 | 無風 | 是 |
| 小雨 | 寒冷 | 正常 | 無風 | 是 |
那麼天氣的資訊熵會等於0,計算如下,當天氣為大晴時,$\frac{1}{1}$的概率不外出,$0$的概率外出,那麼大晴的資訊熵$H(X=外出|Y=大晴)$為:
$$
\begin{split}
H(X=外出|Y=大晴)&=\frac{1}{1}log_2\frac{1}{\frac{1}{1}}+0log_20 \\
&=0
\end{split}
$$
同理天氣條件下其他特徵的資訊熵都是$0$,那麼天氣的資訊熵$H(X=外出|Y=天氣)=0$,得到天氣的資訊增益就最大了。也就是說決策樹給天氣這個屬性下的離散特徵都單獨分成了一個子類,也就是說有多少種天氣情況就有多少種取值,那麼原資料集中有多少個離散特徵,就會被劃分為多少個子類。雖然這種劃分毫無意義,但是從資訊增益準則來講,這就是最好的劃分結果。
對於這種結果看似完美劃分了隨機變數的特徵,然而根據**大數定律**,只有當樣本數足夠多的時候,頻率才可以準確的近似概率。也就是說,**樣本數越少,對概率的估計結果的方差就會越大,結果也就越不準**。想象一下做拋硬幣實驗來近似正面向上的概率,如果只拋兩次,那麼得到的正面向上的概率可能會非常離譜。而如果拋1萬次,不論何時何地幾乎總能得到近似0.5的概率。
而C4.5就是為了解決**資訊增益準則對可取值數目較多的屬性有所偏好**這種問題,由此提出了**資訊增益比**,計算公式為:
$$
Ir=(X,Y)=\frac{I(X,Y)}{IV(Y)}
$$
其中$IV(Y)$計算方式為:
$$
IV(Y)=\sum_yp_ylogp_y
$$
$p_y$等於隨機變數$Y=y$的概率。當資訊熵$H(X|Y)$最小時,也就是分類各不相等的時候,$IV(Y)$也相對最小,這樣就減輕了劃分行為本身的影響。
## cart決策樹
### 基尼係數
有一個盒子裡面放著小球,如果小球的顏色都是綠色,那麼代表綠色的概率是$p_綠=1$,我們可以稱隨機變數$X=綠$是純正的:

如果盒子裡面的小球包含不同的顏色,不同顏色發生的概率為$p_1,p_2,...$,我們可以稱隨機變數$X$不純正的:

假設某組樣本存在多個隨機變數$X_1,X_2,...,X_n$,他們各自發生的概率是$\{p_1,p_2,...,p_n\}$,那麼這組樣本的純正程度可以使用基尼係數(Gini)衡量:
$$
Gini=1-p_1^2-p_2^2-...-p_n^2
$$
假設一個盒子存在3種顏色的小球,他們的概率是:$\{\frac{1}{3},\frac{1}{3},\frac{1}{3}\}$,那麼基尼係數為:$Gini=1-(\frac{1}{3})^2-(\frac{1}{3})^2-(\frac{1}{3})^2=0.6666$。其他情況的基尼係數計算:
$\{\frac{1}{10},\frac{2}{10},\frac{7}{10}\}$,$\{1,0,0\}$
計算的基尼係數為:
$$
Gini=1-(\frac{1}{10})^2-(\frac{2}{10})^2-(\frac{7}{10})^2=0.46
$$
$$
Gini=1-(1)^2-(0)^2-(0)^2=0
$$
基尼係數越大,代表樣本越不純淨;基尼係數越小,代表樣本越純淨,最終會找出$Gini$指數最小的來作為最優的劃分點
### 剪枝
決策樹演算法為了避免過擬合和簡化決策樹模型,提出了剪枝的方法,剪枝分為預剪枝和後剪枝,剪枝的原理如下:
- 預剪枝:在構造決策樹的同時進行剪枝,也就是在節點劃分前進行判斷。所有決策樹的構建方法,都是在無法進一步降低熵的情況下才會停止建立分支的過程,為了避免過擬合,可以設定一個閾值,熵減小的數量小於這個閾值,即使還可以繼續降低熵,也停止繼續建立分支。但是這種方法實際中的效果並不好。
- 後剪枝:在決策樹生長完全構造好了過後,對樹進行剪枝。剪枝的過程是對擁有同樣父節點的一組節點進行檢查,判斷如果將其合併,熵的增加量是否小於某一閾值。如果確實小,則這一組節點可以合併一個節點。後剪枝是目前最普遍的做法。
常見的剪枝有REP(Reduced Error Pruning)、PEP(Pessimistic Error Pruning)、CCP(Cost Complexity Pruning)和MEP(Minimum Error Pruning)演算法,以下分別進行說明。
#### Reduced-Error Pruning(REP,錯誤率降低剪枝)
`REP`是最簡單粗暴的一種後剪枝方法,其目的減少誤差樣本數量。該演算法是從下往上依次遍歷所有的子樹,直至沒有任何子樹可以替換使得在驗證集上的表現得以改進時,演算法就可以終止。
假設樹$T$存在很多結點$t$,其中$t \in T$,$e(t)$表示節點$t$下訓練樣本誤判的數量,則有訓練樣本誤判總數量$f(T)$為:
$$
f(T)=-\sum_{t \in T}e(t)
$$
假設樹$T$去掉某個節點$t'$變成樹$T'$,則有訓練樣本誤判總數量$f(T')$為:
$$
f(T')=-\sum_{t \in T'}e(t)
$$
如果誤判的數量降低,即剪枝之後使得誤差降低:
$$
f(T) \leqslant f(T')
$$
那麼代表剪枝後能使誤差降低,剪枝成功。反覆進行上面的操作,從底向上的處理結點,刪除那些有害的結點,直到進一步修剪不能減低誤差為止。例如:存在如下一棵樹:
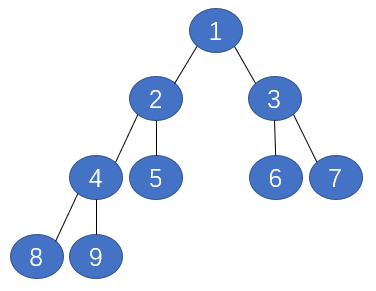
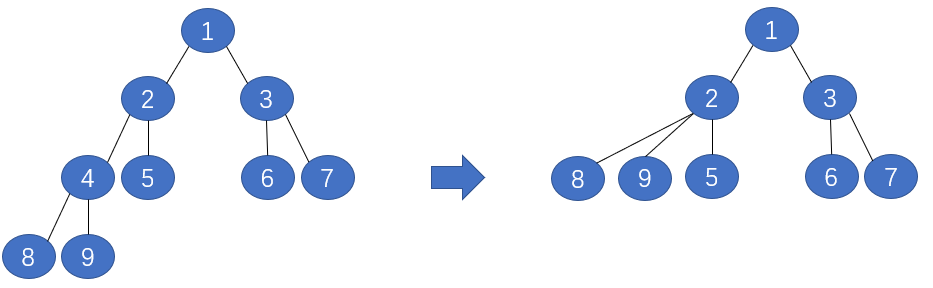
Step 1: 將節點4刪掉替換成8和9,測試在驗證集上的表現,若表現更好,則將節點4刪掉並替換成8和9的並集,若表現不好則保留原樹的形狀
Step 2: 將節點2刪掉替換成8、9和5,測試在驗證集上的表現
Step 3: 將節點3刪掉替換成6和7,測試在驗證集上的表現
`REP`是最簡單的後剪枝方法之一,不過由於使用獨立的驗證集,如果資料量較少(資料要分為訓練集、驗證集、測試集三份),那麼在使用驗證集進行剪枝的時候,可能會在驗證集出現的稀有例項,卻在測試集中沒有出現,那麼就會存在過度剪枝的情況。**如果資料集較小,通常不考慮採用REP演算法**。儘管REP有這個缺點,但還是能夠解決一定程度的過擬合問題。
#### Pesimistic-Error Pruning(PEP,悲觀錯誤剪枝)
上文的`REP`方法思想簡單且易於使用,不過最大的問題在於它需要一個新的驗證集來修正我們的決策樹在,`PEP`方法中不需要新的驗證集,並且`PEP`是自上而下剪枝的。`PEP`的剪枝是把一顆子樹(具有多個葉子節點)的分類用一個葉子節點來替代,如下所示:
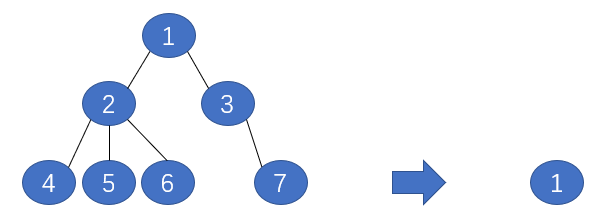
原來子樹1可以分成(4,5,6,7)多個類,但是剪枝變成只能分成一個類(1)。同樣的樣本子集,如果用子樹分類可以分成多個類,準確率肯定要高一些,而用單顆葉子節點來分的話只能分成一個類,準確肯定要低一些,所以$PEP$的誤判率肯定是上升的。訓練資料也帶來錯分誤差偏向於訓練集,為了解決這一問題,給每個子葉節點加入修正項$\frac{1}{2}$。具有$T$個節點的樹的錯誤率為:
$$
E(T) = \sum_{t \in T}\frac{e(t)+1/2}{N(t)}
$$
去掉節點$K$個子葉節點之後T′個節點的樹的錯誤率為:
$$
E(T')=\sum_{t \in T, excep K}\frac{e(t)+1/2K}{N(t)}
$$
其中$e(t)$表示節點$t$下訓練樣本誤判的數量,$N(t)$表示節點$t$下訓練樣本的總數量。
`PEP`悲觀錯誤剪枝剪枝法定義,**如果 E(剪枝後誤判數均值)−E(剪枝前誤判數均值)