
yarn效能調優
一、相關配置情況
關於Yarn記憶體分配與管理,主要涉及到了ResourceManage、ApplicationMatser、NodeManager這幾個概念,相關的優化也要緊緊圍繞著這幾方面來開展。這裡還有一個Container的概念,現在可以先把它理解為執行map/reduce task的容器,後面有詳細介紹。
1.1 RM的記憶體資源配置, 配置的是資源排程相關
RM1:yarn.scheduler.minimum-allocation-mb 分配給AM單個容器可申請的最小記憶體 RM2:yarn.scheduler.maximum-allocation-mb
注:
- 最小值可以計算一個節點最大Container數量
- 一旦設定,不可動態改變
1.2 NM的記憶體資源配置,配置的是硬體資源相關
NM1:yarn.nodemanager.resource.memory-mb 節點最大可用記憶體 NM2:yarn.nodemanager.vmem-pmem-ratio 虛擬記憶體率,預設2.1
注:
- RM1、RM2的值均不能大於NM1的值
- NM1可以計算節點最大最大Container數量,max(Container)=NM1/RM1
- 一旦設定,不可動態改變
1.3 AM記憶體配置相關引數,配置的是任務相關
AM1:mapreduce.map.memory.mb 分配給map Container的記憶體大小 AM2:mapreduce.reduce.memory.mb 分配給reduce Container的記憶體大小
- 這兩個值應該在RM1和RM2這兩個值之間
- AM2的值最好為AM1的兩倍
- 這兩個值可以在啟動時改變
AM3:mapreduce.map.java.opts 執行map任務的jvm引數,如-Xmx,-Xms等選項 AM4:mapreduce.reduce.java.opts
注:
- 這兩個值應該在AM1和AM2之間
二、對於這些配置概念的理解
知道有這些引數,還需理解其如何分配,下面我就一副圖讓大家更形象的瞭解各個引數的含義。
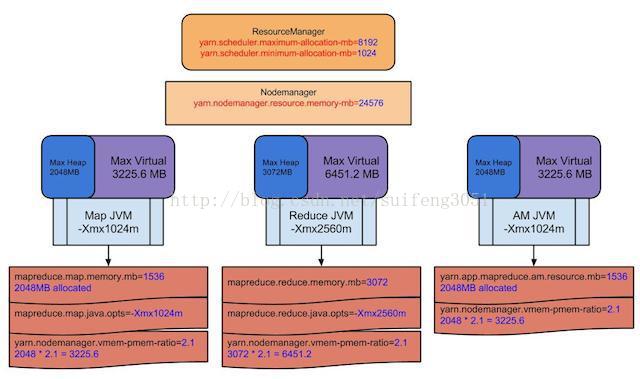
如上圖所示,先看最下面褐色部分,
AM引數mapreduce.map.memory.mb=1536MB,表示AM要為map Container申請1536MB資源,但RM實際分配的記憶體卻是2048MB,因為yarn.scheduler.mininum-allocation-mb=1024MB,這定義了RM最小要分配1024MB,1536MB超過了這個值,所以實際分配給AM的值為2048MB(這涉及到了規整化因子,關於規整化因子,在本文最後有介紹)。
AM引數mapreduce.map.java.opts=-Xmx 1024m,表示執行map任務的jvm記憶體為1024MB,因為map任務要執行在Container裡面,所以這個引數的值略微小於mapreduce.map.memory.mb=1536MB這個值。
NM引數yarn.nodemanager.vmem-pmem-radio=2.1,這表示NodeManager可以分配給map/reduce Container 2.1倍的虛擬記憶體,安照上面的配置,實際分配給map Container容器的虛擬記憶體大小為2048*2.1=3225.6MB,若實際用到的記憶體超過這個值,NM就會kill掉這個map Container,任務執行過程就會出現異常。
AM引數mapreduce.reduce.memory.mb=3072MB,表示分配給reduce Container的容器大小為3072MB,而map Container的大小分配的是1536MB,從這也看出,reduce Container容器的大小最好是map Container大小的兩倍。
NM引數yarn.nodemanager.resource.mem.mb=24576MB,這個值表示節點分配給NodeManager的可用記憶體,也就是節點用來執行yarn任務的記憶體大小。這個值要根據實際伺服器記憶體大小來配置,比如我們hadoop叢集機器記憶體是128GB,我們可以分配其中的80%給yarn,也就是102GB。
上圖中RM的兩個引數分別1024MB和8192MB,分別表示分配給AM map/reduce Container的最大值和最小值。
三、關於任務提交過程
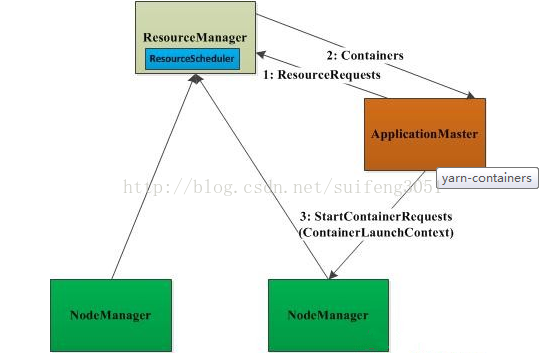
3.1 任務提交過程
- 步驟1:使用者將應用程式提交到ResourceManager上;
- 步驟2:ResourceManager為應用程式ApplicationMaster申請資源,並與某個NodeManager通訊,以啟動ApplicationMaster;
- 步驟3:ApplicationMaster與ResourceManager通訊,為內部要執行的任務申請資源,一旦得到資源後,將於NodeManager通訊,以啟動對應的任務。
-
步驟4:所有任務執行完成後,ApplicationMaster向ResourceManager登出,整個應用程式執行結束。
3.2 關於Container
(1)Container是YARN中資源的抽象,它封裝了某個節點上一定量的資源(CPU和記憶體兩類資源)。它跟Linux Container沒有任何關係,僅僅是YARN提出的一個概念(從實現上看,可看做一個可序列化/反序列化的Java類)。
(2)Container由ApplicationMaster向ResourceManager申請的,由ResouceManager中的資源排程器非同步分配給ApplicationMaster;
(3)Container的執行是由ApplicationMaster向資源所在的NodeManager發起的,Container執行時需提供內部執行的任務命令(可以使任何命令,比如java、Python、C++程序啟動命令均可)以及該命令執行所需的環境變數和外部資源(比如詞典檔案、可執行檔案、jar包等)。
另外,一個應用程式所需的Container分為兩大類,如下:
(1) 執行ApplicationMaster的Container:這是由ResourceManager(向內部的資源排程器)申請和啟動的,使用者提交應用程式時,可指定唯一的ApplicationMaster所需的資源;
(2)執行各類任務的Container:這是由ApplicationMaster向ResourceManager申請的,並由ApplicationMaster與NodeManager通訊以啟動之。
以上兩類Container可能在任意節點上,它們的位置通常而言是隨機的,即ApplicationMaster可能與它管理的任務執行在一個節點上。
Container是YARN中最重要的概念之一,懂得該概念對於理解YARN的資源模型至關重要,望大家好好理解。
注意:如下圖,map/reduce task是執行在Container之中的,所以上面提到的mapreduce.map(reduce).memory.mb大小都大於mapreduce.map(reduce).java.opts值的大小。

四、HDP平臺引數調優建議
根據上面介紹的相關知識,我們就可以根據我們的實際情況作出相關引數的設定,當然還需要在執行測試過程中不斷檢驗和調整。
以下是hortonworks給出的配置建議:
http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.1.1/bk_installing_manually_book/content/rpm-chap1-11.html
4.1 記憶體分配
Reserved Memory = Reserved for stack memory + Reserved for HBase Memory (If HBase is on the same node)
系統總記憶體126GB,預留給作業系統24GB,如果有Hbase再預留給Hbase24GB。
下面的計算假設Datanode節點部署了Hbase。
4.2containers 計算:
MIN_CONTAINER_SIZE = 2048 MB
containers = min (2*CORES, 1.8*DISKS, (Total available RAM) / MIN_CONTAINER_SIZE)
\# of containers = min (2*12, 1.8*12, (78 * 1024) / 2048)
\# of containers = min (24,21.6,39)
\# of containers = 22
container 記憶體計算:
RAM-per-container = max(MIN_CONTAINER_SIZE, (Total Available RAM) / containers))
RAM-per-container = max(2048, (78 * 1024) / 22))
RAM-per-container = 3630 MB4.3Yarn 和 Mapreduce 引數配置:
yarn.nodemanager.resource.memory-mb = containers * RAM-per-container
yarn.scheduler.minimum-allocation-mb = RAM-per-container
yarn.scheduler.maximum-allocation-mb = containers * RAM-per-container
mapreduce.map.memory.mb = RAM-per-container
mapreduce.reduce.memory.mb = 2 * RAM-per-container
mapreduce.map.java.opts = 0.8 * RAM-per-container
mapreduce.reduce.java.opts = 0.8 * 2 * RAM-per-container
yarn.nodemanager.resource.memory-mb = 22 * 3630 MB
yarn.scheduler.minimum-allocation-mb = 3630 MB
yarn.scheduler.maximum-allocation-mb = 22 * 3630 MB
mapreduce.map.memory.mb = 3630 MB
mapreduce.reduce.memory.mb = 22 * 3630 MB
mapreduce.map.java.opts = 0.8 * 3630 MB
mapreduce.reduce.java.opts = 0.8 * 2 * 3630 MB附:規整化因子介紹
為了易於管理資源和排程資源,Hadoop YARN內建了資源規整化演算法,它規定了最小可申請資源量、最大可申請資源量和資源規整化因子,如果應用程式申請的資源量小於最小可申請資源量,則YARN會將其大小改為最小可申請量,也就是說,應用程式獲得資源不會小於自己申請的資源,但也不一定相等;如果應用程式申請的資源量大於最大可申請資源量,則會丟擲異常,無法申請成功;規整化因子是用來規整化應用程式資源的,應用程式申請的資源如果不是該因子的整數倍,則將被修改為最小的整數倍對應的值,公式為ceil(a/b)*b,其中a是應用程式申請的資源,b為規整化因子。
比如,在yarn-site.xml中設定,相關引數如下:
yarn.scheduler.minimum-allocation-mb:最小可申請記憶體量,預設是1024
yarn.scheduler.minimum-allocation-vcores:最小可申請CPU數,預設是1
yarn.scheduler.maximum-allocation-mb:最大可申請記憶體量,預設是8096
yarn.scheduler.maximum-allocation-vcores:最大可申請CPU數,預設是4對於規整化因子,不同調度器不同,具體如下:
FIFO和Capacity Scheduler,規整化因子等於最小可申請資源量,不可單獨配置。
Fair Scheduler:規整化因子通過引數yarn.scheduler.increment-allocation-mb和yarn.scheduler.increment-allocation-vcores設定,預設是1024和1。
通過以上介紹可知,應用程式申請到資源量可能大於資源申請的資源量,比如YARN的最小可申請資源記憶體量為1024,規整因子是1024,如果一個應用程式申請1500記憶體,則會得到2048記憶體,如果規整因子是512,則得到1536記憶體。