
caffe Segnet 語義分割(一)
2018.02.26 learning journal
by 趙木木
1. 編譯slam3d出錯記錄
- Qt 編譯器可以清楚的查到錯誤所在位置;
在Issues中檢視
【error1】:
could not convert‘Eigen::PlainObject...
'Eigen::Map...
PCL_ADD_POINT4D;....【error2】:
/usr/local/include/eigen3/Eigen/src/Core/arch/CUDA/Half.h:48: error: using typedef-name '__half' after 'struct' 解決方案
將已有的第三方庫eigen-3-2-10安裝
cmake..
make
sudo make install也就是使用slam3d自帶的eigen的庫,就不會報錯。
2. 學習segnet-caffe
學習連結:
Segnet分割網路caffe教程
對照Segnet-Tutorial檔案內容
github上有開源的兩套原始碼,其中caffe-segnet是支援cudnn v2 版本;
另有支援cudnn v5版本的:原始碼地址為 https://github.com/TimoSaemann/caffe-segnet-cudnn5
已經下載好原始碼至本地並安裝。
說明:
This repository contains all the files for you to complete the ‘Getting Started with SegNet’ and the ‘Bayesian SegNet’ tutorials here: http://mi.eng.cam.ac.uk/projects/segnet/tutorial.html
Please see this link for detailed instructions.
教程
2.1 Setting Up Caffe and the Dataset
請注意,本教程假設您將所有檔案下載到本地的資料夾/ SegNet /中。如果您選擇使用不同的目錄,請在適當的地方修改命令。
Segnet 從監督學習來預測畫素點的分類標籤,因此我們需要一個具有相應 ground truth 標籤的輸入影象的資料集,標籤影象必須是單通道,每個畫素都標有其類別。在本教程中,我們將使用CamVid資料集,其中包含367個訓練和233個道路場景的測試影象。該資料集是在英國劍橋附近拍攝的,包含白天和黃昏場景。我們將使用影象大小為360 x 480的11類版本。從 Github-Segnet教程 下載SegNet所需的這個資料集以及本教程所需的其餘檔案。
檔案組織如下:
/SegNet/
CamVid/
test/
testannot/
train/
trainannot/
test.txt
train.txt
Models/
# SegNet and SegNet-Basic model files for training and testing
Scripts/
compute_bn_statistics.py
test_segmentation_camvid.py
caffe-segnet/
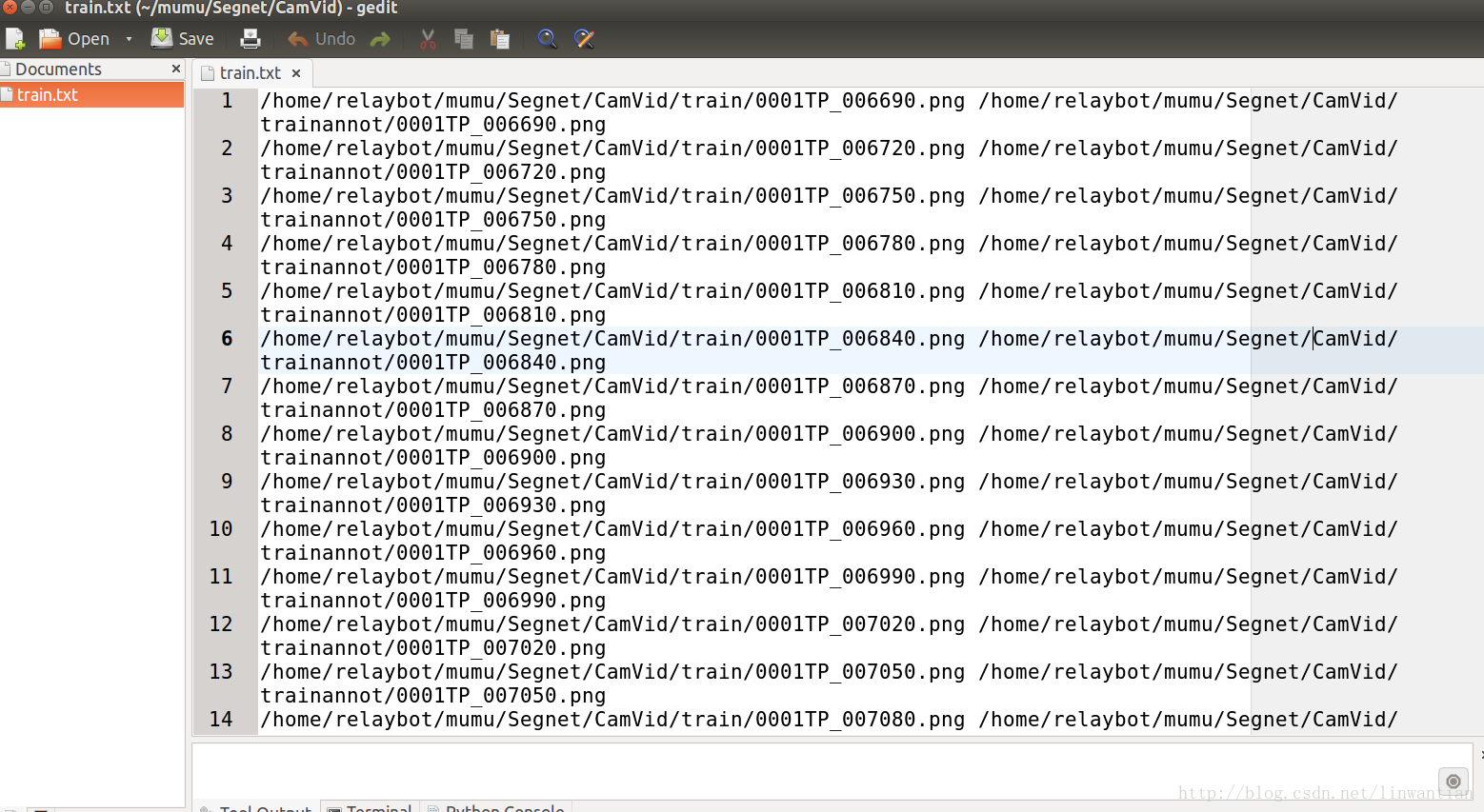
# caffe implementation我們現在需要修改 CamVid/train.txt和 CamVid/test.txt ,以便SegNet知道在哪裡找到資料。 SegNet需要一個由空白分隔的路徑的影象檔案(.jpg或.png)和相應的標籤影象(.png)。例如:
/path/to/image1.png /another/path/to/label1.png /path/to/image2.png /path/label2.png ...請在文字編輯器中開啟這兩個檔案,並使用查詢和替換工具將 ‘/ SegNet / …’ 更改為資料的絕對路徑。
2.2 Training SegNet
下一步是建立一個訓練模型。您可以使用SegNet或SegNet basic進行訓練。首先,開啟模型檔案Models/segnet_train.prototxt和推理模型檔案 Models/segnet_inference.prototxt 。您將需要修改所有模型資料層中的資料輸入的原始碼行,將其替換為本地電腦中到您的資料檔案的絕對目錄。根據您的GPU大小,您可能需要修改培訓模型中的批量大小。在12GB的GPU上,如NVIDIA K40或Titan X,您應該可以分別使用10或6的批量大小來處理SegNet-Basic或SegNet。如果你有一個更小的GPU,那麼儘量使它儘可能大,然而即使是低至2或3的批量也應該訓練得好。其次,請開啟解算器檔案Models/segnet_solver.prototxt並更改兩行; net和snapshot_prefix目錄應該將目錄與您的資料匹配。
原來的caffe訓練引數:有‘#’註釋的地方修改為絕對路徑

對SegNet-Basic模型,推理模型和解算器原型檔案重複以上步驟。建立一個資料夾以儲存您的訓練權重和解算器詳細資訊:mkdir /SegNet/Models/Training
我們現在準備好培訓SegNet!開啟一個終端併發出這些命令:
./SegNet/caffe-segnet/build/tools/caffe train -gpu 0 -solver /SegNet/Models/segnet_solver.prototxt # This will begin training SegNet on GPU 0
./SegNet/caffe-segnet/build/tools/caffe train -gpu 0 -solver /SegNet/Models/segnet_basic_solver.prototxt # This will begin training SegNet-Basic on GPU 0
./SegNet/caffe-segnet/build/tools/caffe train -gpu 0 -solver /SegNet/Models/segnet_solver.prototxt -weights /SegNet/Models/VGG_ILSVRC_16_layers.caffemodel # This will begin training SegNet on GPU 0 with a pretrained encoder對這個小資料集的培訓不應該花太長時間。大約50-100個時期後,你應該看到它收斂。你應該尋找超過90%的訓練準確性。一旦你對模型的匯合結果感到滿意,我們現在可以對其進行測試。
2.3 Testing SegNet
首先開啟指令碼Scripts/compute_bn_statistics.py和Scripts/test_segmentation_camvid.py並將第10行更改為您的SegNet Caffe安裝目錄。
SegNet中的批處理規範化層根據訓練期間每個小批量的均值和方差統計資訊對輸入特徵對映進行移位。在測試時間,我們必須使用整個資料集的統計資料。為此,請使用以下命令執行指令碼Scripts/compute_bn_statistics.py。確保您將訓練權重檔案更改為您希望使用的權重檔案。
python /Segnet/Scripts/compute_bn_statistics.py /SegNet/Models/segnet_train.prototxt /SegNet/Models/Training/segnet_iter_10000.caffemodel /Segnet/Models/Inference/ # compute BN statistics for SegNet
python /Segnet/Scripts/compute_bn_statistics.py /SegNet/Models/segnet_basic_train.prototxt /SegNet/Models/Training/segnet_basic_iter_10000.caffemodel /Segnet/Models/Inference/ # compute BN statistics for SegNet-Basic該指令碼將輸出目錄中的最終測試權重儲存為/SegNet/Models/Inference/test_weights.caffemodel請將它們重新命名為更具描述性的內容。
現在我們可以檢視SegNet的輸出了!
test_segmentation_camvid.py執行命令將顯示每個測試影象的輸入影象,地面實況和分割預測。嘗試使用這些命令,使用正確的推理統計資訊將權重檔案更改為剛才處理的權重檔案:
python /SegNet/Scripts/test_segmentation_camvid.py --model /SegNet/Models/segnet_inference.prototxt --weights /SegNet/Models/Inference/test_weights.caffemodel --iter 233 # Test SegNet
python /SegNet/Scripts/test_segmentation_camvid.py --model /SegNet/Models/segnet_basic_inference.prototxt --weights /SegNet/Models/Inference/test_weights.caffemodel --iter 233 # Test SegNetBasic2.4 Results
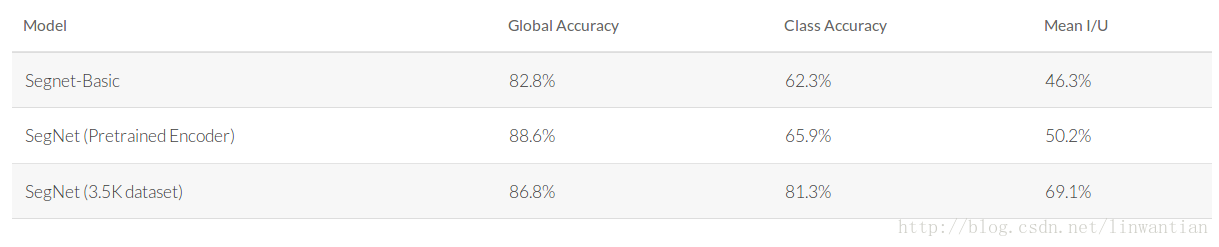
下表顯示了我們在CamVid資料集上使用SegNet獲得的效能。如果你已經正確地遵循了本教程,你應該能夠獲得前兩個結果。最終的結果是通過公開可用的資料集對3.5K額外的標記影象進行了訓練,請參閱該論文獲取更多詳細資訊。 webdemo已經接受了未公開的更多資料和額外的類別(道路標記)的訓練。
輸出結果圖示:

以下是記錄網頁瀏覽
(3)Awesome SLAM
github SLAM 資源
(6)【https://arxiv.org/pdf/1703.07334.pdf】
Pop-up SLAM: Semantic Monocular Plane SLAM for Low-texture Environments
論文文獻