
spark叢集配置
阿新 • • 發佈:2018-11-27
1.jdk環境
2.scala安裝和環境配置

3.spark

配置spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_141 export SCALA_HOME=/usr/scala export SPARK_MASTER_IP=han01 export SPARK_MASTER_PORT=7077 export SPARK_WORKER_CORES=1 #每個Worker程序所需要的CPU核的數目; export SPARK_WORKER_INSTANCES=1 #每個Worker節點上執行Worker程序的數目 export SPARK_WORKER_CORES=1 #每個WORK再節點執行時佔用的cpu個數 export SPARK_WORKER_MEMORY=1g export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.3/etc/hadoop SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.de ploy.zookeeper.url=han01:2181,han02:2181,han03:2181 -Dspark.deploy.zooke eper.dir=/spark"

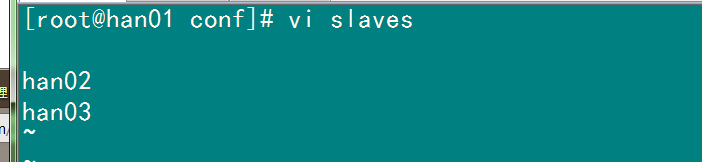
4.配置slaves(worker坐在的機器)
5.避免與hadoop啟動命令衝突
修改.sh

6.jdk
將配置 拷貝到其他兩個機器

重新整理環境變數: source /etc/profile
7.啟動spark

8.進入shell介面

9.(出現問題)拒絕連線:
