
KNN,K近鄰來做影象分類
KNN來做影象分類:如下圖所示,用CIFAR-10圖片作為訓練樣本,50000張圖片作為訓練集,10000圖片作為測試集。
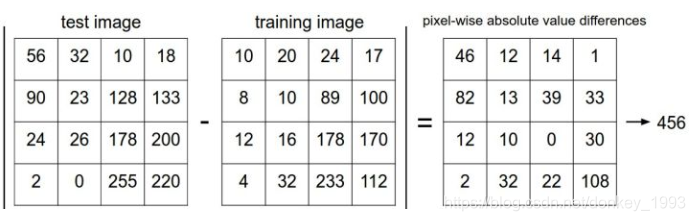
KNN分類就是將測試集的畫素值-訓練集的畫素值然後將畫素值相加就得到我們的距離,距離最小的就是我們最後的分類結果。
有時候只找到距離最近的一張圖片會出現誤差比較大,所以我們一般找5張距離最近的圖片,選區這5張圖片中類別最多的種類作為我們最終的分類結果。
下圖是L1距離,也叫曼哈頓距離
下圖是L2距離,也叫歐式距離
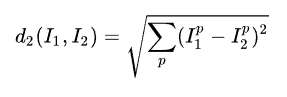
相關推薦
KNN,K近鄰來做影象分類
KNN來做影象分類:如下圖所示,用CIFAR-10圖片作為訓練樣本,50000張圖片作為訓練集,10000圖片作為測試集。 KNN分類就是將測試集的畫素值-訓練集的畫素值然後將畫素值相加就得到我們的距離,距離最小的就是我們最後的分類結果。 有時候只找到距離最近的一張圖片會出現誤差比較大,所以
python資料探勘入門與實踐--------電離層(Ionosphere), scikit-learn估計器,K近鄰分類器,交叉檢驗,設定引數
ionosphere.data下載地址:http://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/ 原始碼及相關資料下載 https://github.com/xxg1413/MachineLea
一看就懂的K近鄰演算法(KNN),K-D樹,並實現手寫數字識別!
1. 什麼是KNN 1.1 KNN的通俗解釋 何謂K近鄰演算法,即K-Nearest Neighbor algorithm,簡稱KNN演算法,單從名字來猜想,可以簡單粗暴的認為是:K個最近的鄰居,當K=1時,演算法便成了最近鄰演算法,即尋找最近的那個鄰居。 用官方的話來說,所謂K近鄰演算法,即是給定一個訓練資
K近鄰算法——多分類問題
避免 曼哈頓 相互 個數 一個 實例 給定 通過 enter 給定一個訓練數據集,對新的輸入實例,在訓練數據集中找到與該實例最鄰近的K個實例,這K個實例的多數屬於某個類,就把該類輸入實例分為這個類。 KNN是通過測量不同特征值之間的距離進行分類。它的的思路是:如果一個
豆瓣API接口開發,結合angularJS來做,感覺爽歪歪!
height 電影 ati object public date itl per 演員 第一次做還是先說下API 是什麽鬼? API : application program interface 應用程序編程接口: 有那些常見的API: webAPI : 通過WEB方式提
關於Java如何獲取系統時間,並用它來做一個圖書管理系統
首先,這個圖書管理系統自定義一個final常量不能更改,用作圖書館借閱歸還的最晚時間,也可以自定義歸還時間。 然後,先獲取使用者借閱時間,再用SimpleDataFormata元件來格式化日期(yyyy-MM-dd),再將獲取的時間加在系統的時間上得到使用者自定義的歸還時間。 最後,再通過方
【python與機器學習入門1】KNN(k近鄰)演算法2 手寫識別系統
參考部落格:超詳細的機器學習python入門knn乾貨 (po主Jack-Cui 參考書籍:《機器學習實戰》——第二章 KNN入門第二彈——手寫識別系統demo ——《機器學習實戰》第二章2.3 手寫識別系統 &
用NodeJS/express-4.0實現的靜態檔案伺服器(serveStatic外掛直接支援HTTP Range請求,因此可用來做mp4流媒體伺服器)
var express = require('express'), serveIndex = require('serve-index'), //只能列表目錄,不能下載檔案? serveStatic = require('serve-stat
美工請假了,程式設計師來做個圖頂一下
本文來源:EDIUS(今日頭條) 連結:http://www.toutiao.com/a6438868399145763073/ 圖片來自:Reddit 如果哪天設計師消失了,這個世界會變成什麼樣? 經常逛淘寶的朋友會發現,在淘寶或者其他電商網站,有一個“設計”流派,叫做“設計師跑路了”派,跟“江南
淺談knn(k近鄰)演算法
概述 K近鄰演算法是一種懶惰演算法,即沒有對資料集進行訓練的過程,其模型的三個要素:距離度量、k值的選擇和分類決策規則決定。 K近鄰的思想很簡單,即在一個數據集上,給定一個新樣本,找到與新樣本距離最近的k個例項,在這些例項中屬於多數的類即為這個新樣本的類。
KNN(k近鄰)演算法原理
原理:樣本點的特性與該鄰居點的特性類似,可以簡單理解為“物以類聚”。因此可以使用目標點的多個鄰近點的特性表示當前點的特性。2.KNN演算法包含:1、KNN分類演算法:“投票法”,選擇這k 個樣本中出現最多的類別標記作為預測結果;2、KNN迴歸演算法:“平均法”,將這k 個樣本
Windows下用Matlab載入caffemodel做影象分類
1.編譯caffe的matlab介面 用到了happynear提供的caffe-windows-master,編譯caffe和matlab介面的過程看這裡。編譯好之後,caffe-windows-master\matlab\+caffe\private內的檔案如下: 如果
實現KNN(K近鄰平滑濾波器)
要求:演算法實現為函式[im]=KNN_denoise (I,K,N),其中I為讀入的影象矩陣;K為最近鄰個數,N為模板大小引數(N*N)。 參考測試程式碼: I = imread('peppers
kNN(k近鄰演算法)
K近鄰分析(KNN) 一、概述 KNN演算法是一種有監督學習的分類演算法。所謂有監督學習,就是在應用演算法之前我們必須準備一組訓練集,訓練集中的每個例項都是由一些特徵和一個分類標籤組成;通常還會存在一個測試集,用來測試訓練出來的分類模型的準確性。其實KNN演算法並沒有體現
KNN(K近鄰)演算法的簡單入門
機器學習實戰(第二章:k-近鄰演算法) 今天學習了第二章,在此就我理解做一下簡單的總結,算是加深我的理解和用我自己的語言描述出這個演算法吧。 距離計算 基於向量空間的歐幾里得距離的計算。(L2距離) 特別情況下可採用Lp距離(明氏距離) L1距離。 簡單點來說就是 在一
【計算機視覺之三】運用k近鄰演算法進行圖片分類
這篇文章主要給不知道計算機視覺是啥的人介紹一下影象分類問題以及最近的最近鄰演算法。 目錄 影象分類 1.1 影象分類的原理 1.2 面臨的問題 1.3 影象分類任務 最近鄰演算法 程式碼實現 L2距離 用k-近鄰進行圖片分類 5.1 k近鄰分類原理
機器學習之KNN(k近鄰)演算法
1、演算法介紹k近鄰演算法是學習機器學習的入門演算法,可實現分類與迴歸,屬於監督學習的一種。演算法的工作原理是:輸入一個訓練資料集,訓練資料集包括特徵空間的點和點的類別,可以是二分類或是多分類。預測時,輸入沒有類別的點,找到k個與該點距離最接近的點,使用多數表決的方法,得出最後的預測分類。
機器學習之KNN(k近鄰)算法
target rom val zip 定義 stat 2-0 datasets tro 1、算法介紹k近鄰算法是學習機器學習的入門算法,可實現分類與回歸,屬於監督學習的一種。算法的工作原理是:輸入一個訓練數據集,訓練數據集包括特征空間的點和點的類別,可以是二分類或是多分類
7、KNN(K近鄰)
KNN(K最近鄰演算法) 1、KNN行業應用: 比如文字識別,面部識別;預測某人是否喜歡推薦電影(Netflix);基因模式識別,比如用於檢測某中年疾病;客戶流失預測、欺詐偵測(更適合於稀有事件的分類問題) KNN應用場景:通常最近鄰分類器使用於特徵與目標類之間的關係為比較
tensorflow 1.0 學習:用Google訓練好的模型來進行影象分類
谷歌在大型影象資料庫ImageNet上訓練好了一個Inception-v3模型,這個模型我們可以直接用來進來影象分類。下載地址:github:https://github.com/taey16/tf/tree/master/imagenet下載完解壓後,得到幾個檔案:其中的c