
python資料分析例項(1)
阿新 • • 發佈:2018-11-27
1.獲取資料:
想要獲得道指30只成分股的最新股價
import requests import re import pandas as pd def retrieve_dji_list(): try: r = requests.get('https://money.cnn.com/data/dow30/') except ConnectionError as err: print(err) search_pattern = re.compile('class="wsod_symbol">(.*?)<\/a>.*?<span.*?">(.*?)<\/span>.*?\n.*?class="wsod_stream">(.*?)<\/span>') dji_list_in_text = re.findall(search_pattern, r.text) dji_list = [] for item in dji_list_in_text: dji_list.append([item[0], item[1], float(item[2])]) return dji_list dji_list = retrieve_dji_list() djidf = pd.DataFrame(dji_list) print(djidf)
整理資料, 改變列名, index等
cols=['code','name','lasttrade'] djidf.columns=cols # 改變列名 djidf.index=range(1,len(djidf)+1)
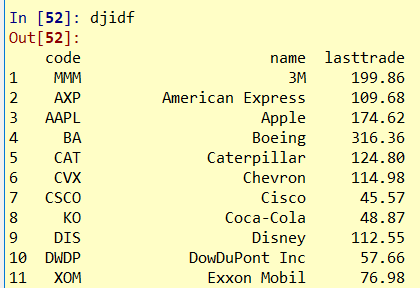
最後結果為:
資料的選擇
djidf.code # 獲取code列+index djidf['code'] # 獲取code列 , 兩者同功能 djidf.loc[1:5,] # 前5行 djidf.loc[:,['code','lasttrade']] #所有行 djidf.loc[1:5,['code','lasttrade']] #1-5行, loc表示標籤index djidf.loc[1,['code','lasttrade']] #1行 djidf.at[1,'lasttrade'] # 只有一個值的時候可以用at djidf.iloc[2:4,[0,2]] # 表示物理文職, 並且4取不到, 就只有第三行第四行 djidf.iat[1,2] # 單個值
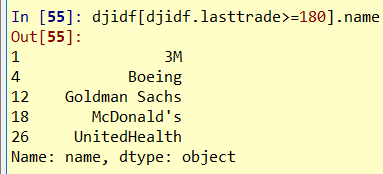
簡單的資料篩選: 平均股價, 股價大於180的公司名
djidf.lasttrade.mean() # 121.132
djidf[djidf.lasttrade>=180].name
找到股價前三名的公司 , 降序排列
tempdf=djidf.sort_values(by='lasttrade',ascending=False) tempdf[:3].name
如何根據index排序呢? 專門有函式sort_index()
df=pd.DataFrame(np.random.randn(3,3),index=['c','b','a'],columns=list('xyz')) df.sort_index() # 根據index 進行排序
*獲取AXP公司過去一年的股價資料獲取
import requests import re import json import pandas as pd from datetime import date def retrieve_quotes_historical(stock_code): quotes = [] url = 'https://finance.yahoo.com/quote/%s/history?p=%s' % (stock_code, stock_code) try: r = requests.get(url) except ConnectionError as err: print(err) m = re.findall('"HistoricalPriceStore":{"prices":(.*?),"isPending"', r.text) if m: quotes = json.loads(m[0]) # m = ['[{...},{...},...]'] quotes = quotes[::-1] # 原先資料為date最新的在最前面 return [item for item in quotes if not 'type' in item] quotes = retrieve_quotes_historical('AXP') list1=[] for i in range(len(quotes)): x=date.fromtimestamp(quotes[i]['date']) y=date.strftime(x,'%Y-%m-%d') list1.append(y) quotesdf_ori=pd.DataFrame(quotes,index=list1) quotesdf_m = quotesdf_ori.drop(['adjclose'], axis = 1) #刪除adjclose列 quotesdf=quotesdf_m.drop(['date'],axis=1) print(quotesdf)
上述需要對時間進行處理, 將時間轉為'%Y-%m-%d'的格式, 並且將這個時間作為一個list 成為quotesdf的index.
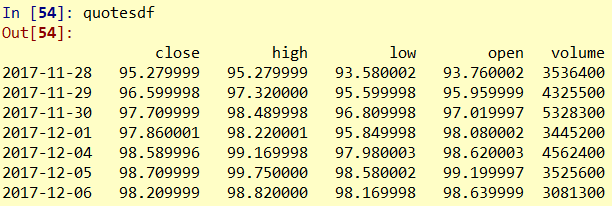
資料的篩選
quotesdf[(quotesdf.index>='2017-03-01') & (quotesdf.index<='2017-03-31')] quotesdf[(quotesdf.index>='2017-11-30') & (quotesdf.index<='2018-03-31')& (quotesdf.close>=90)]
簡單計算
(1) 統計AXP股價漲跌的天數 (close>open)
len(quotesdf.close>quotesdf.open)
(2) 相鄰兩天的漲跌
import numpy as np status=np.sign(np.diff(quotesdf.close)) status # 250 的長度, 比quotesdf 少1 status[np.where(status==1)].size # np.where(status==1)是由下標構成的array #
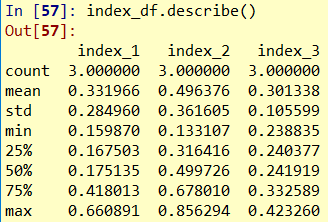
上述統計還可以直接用describe函式, 得到基本統計資訊
import pandas as pd import numpy as np index_df = pd.DataFrame(np.random.rand(3,3), index=['a','b','c'], columns=['index_1','index_2','index_3']) index_df.describe() # 超級強大
(3) 統計2018一月的交易日天數
t=quotesdf[(quotesdf.index>='2018-01-01') & (quotesdf.index<'2018-02-01')] len(t) #21
進一步, 如何統計近一年每個月的交易日天數?
統計每個月的出現天數就行了, 如何提取月份資訊? 要把時間的字串轉化為 時間格式,
import time list2=[] for i in range(len(quotesdf)): temp=time.strptime(quotesdf.index[i],'%Y-%m-%d') list2.append(temp.tm_mon) # 取月份 tempdf=quotesdf.copy() tempdf['month']=list2 # 新增一列月份的資料 print(tempdf['month'].value_counts()) # 計算每個月的出現次數
注意:
strptime 將字串格式化為time結構, time 中會包含年份, 月份等資訊
strftime 將time 結構格式化一個字串, 之前生成quotesdf中用到過
上述方法略微麻煩, 如何快速知道每個月的交易日天數? groupby
# 統計每一月的股票開盤天數 x=tempdf.groupby('month').count() # 統計近一年每個月的成交量 tempdf.groupby('month').sum().volume # 先每個月進行求和, 但是這些對其他列也進行了求和, 屬於無效計算, 如何避免? tempdf.groupby('month').volume.sum() # 交換順序即可
引申: 一般groupby 與apply 在一起用. 具體不展開了
def f(df): return df.age.count() data_df.groupby('taste of mooncake').apply(f)
(二) 合併DataFrame: append, concat, join
# append p=quotesdf[:2] q=quotesdf['2018-01-01':'2018-01-05'] p.append(q) # concat pieces=[tempdf[:5],tempdf[len(tempdf)-5:]] pd.concat(pieces)
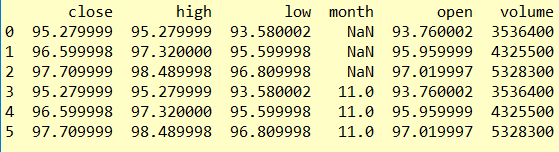
兩個結構不同的DataFrame 如何合併?
piece1=quotesdf[0:3] piece2=tempdf[:3] pd.concat([piece1,piece2],ignore_index=True)
piece2有month 但是piece1中沒有這個欄位
join函式中的各種引數, 可以用來實現SQL的各種合併功能.
#join 兩個dataframe要有共同的欄位(列名) #djidf: code/name #AKdf: volume/code/month # 合併之後的欄位: code/name/volume/month pd.merge(djidf.drop(['lasttrade'],axis=1),AKdf, on='code')