
python如何實現爬蟲技術
阿新 • • 發佈:2018-11-28
一、什麼是爬蟲
爬蟲:一段自動抓取網際網路資訊的程式,從網際網路上抓取對於我們有價值的資訊。
二、Python爬蟲架構
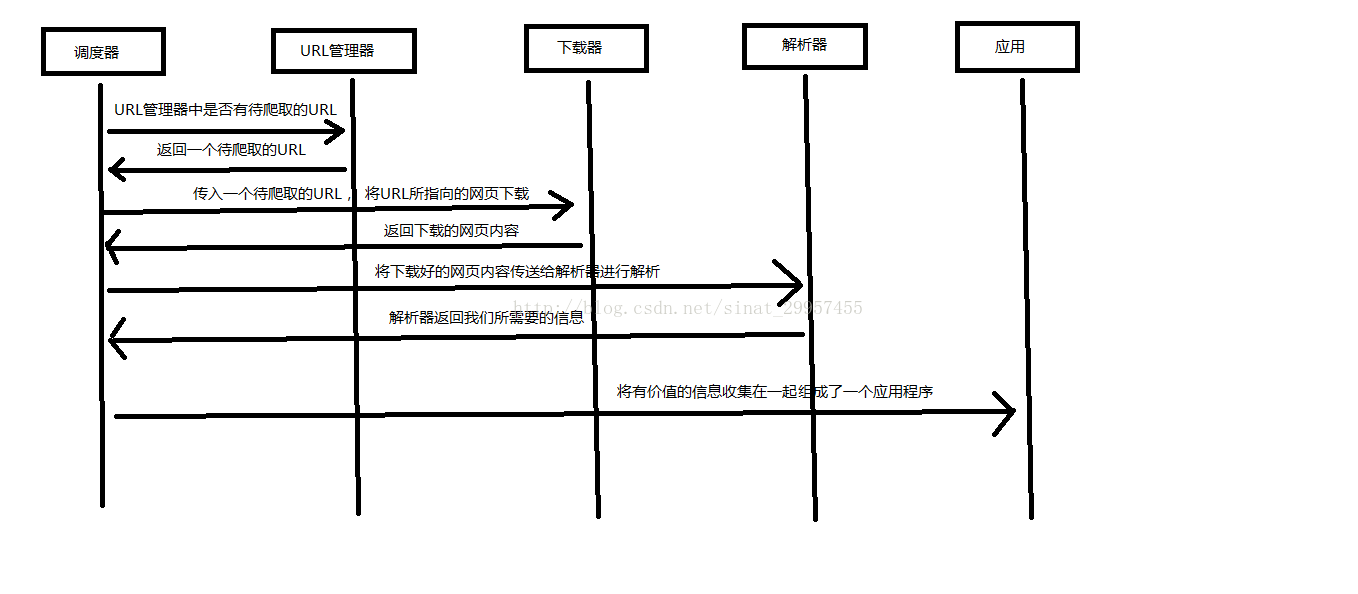
Python 爬蟲架構主要由五個部分組成,分別是排程器、URL管理器、網頁下載器、網頁解析器、應用程式(爬取的有價值資料)。
- 排程器:相當於一臺電腦的CPU,主要負責排程URL管理器、下載器、解析器之間的協調工作。
- URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重複抓取URL和迴圈抓取URL,實現URL管理器主要用三種方式,通過記憶體、資料庫、快取資料庫來實現。
- 網頁下載器:通過傳入一個URL地址來下載網頁,將網頁轉換成一個字串,網頁下載器有urllib2(Python官方基礎模組)包括需要登入、代理、和cookie,requests(第三方包)
- 網頁解析器:將一個網頁字串進行解析,可以按照我們的要求來提取出我們有用的資訊,也可以根據DOM樹的解析方式來解析。網頁解析器有正則表示式(直觀,將網頁轉成字串通過模糊匹配的方式來提取有價值的資訊,當文件比較複雜的時候,該方法提取資料的時候就會非常的困難)、html.parser(Python自帶的)、beautifulsoup(第三方外掛,可以使用Python自帶的html.parser進行解析,也可以使用lxml進行解析,相對於其他幾種來說要強大一些)、lxml(第三方外掛,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 樹的方式進行解析的。
- 應用程式:就是從網頁中提取的有用資料組成的一個應用。
下面用一個圖來解釋一下排程器是如何協調工作的:
三、urllib2 實現下載網頁的三種方式
#!/usr/bin/python # -*- coding: UTF-8 -*- import cookielib import urllib2 url = "http://www.baidu.com" response1 = urllib2.urlopen(url) print "第一種方法" #獲取狀態碼,200表示成功 print response1.getcode() #獲取網頁內容的長度 print len(response1.read()) print "第二種方法" request = urllib2.Request(url) #模擬Mozilla瀏覽器進行爬蟲 request.add_header("user-agent","Mozilla/5.0") response2 = urllib2.urlopen(request) print response2.getcode() print len(response2.read()) print "第三種方法" cookie = cookielib.CookieJar() #加入urllib2處理cookie的能力 opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie)) urllib2.install_opener(opener) response3 = urllib2.urlopen(url) print response3.getcode() print len(response3.read()) print cookie
四、第三方庫 Beautiful Soup 的安裝
Beautiful Soup: Python 的第三方外掛用來提取 xml 和 HTML 中的資料,官網地址 https://www.crummy.com/software/BeautifulSoup/
1、安裝 Beautiful Soup
開啟 cmd(命令提示符),進入到 Python(Python2.7版本)安裝目錄中的 scripts 下,輸入 dir 檢視是否有 pip.exe, 如果用就可以使用 Python 自帶的 pip 命令進行安裝,輸入以下命令進行安裝即可:
pip install beautifulsoup42、測試是否安裝成功
編寫一個 Python 檔案,輸入:
import bs4 print bs4
執行該檔案,如果能夠正常輸出則安裝成功。
五、使用 Beautiful Soup 解析 html 檔案
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#建立一個BeautifulSoup解析物件
soup = BeautifulSoup(html_doc,"html.parser",from_encoding="utf-8")
#獲取所有的連結
links = soup.find_all('a')
print "所有的連結"
for link in links:
print link.name,link['href'],link.get_text()
print "獲取特定的URL地址"
link_node = soup.find('a',href="http://example.com/elsie")
print link_node.name,link_node['href'],link_node['class'],link_node.get_text()
print "正則表示式匹配"
link_node = soup.find('a',href=re.compile(r"ti"))
print link_node.name,link_node['href'],link_node['class'],link_node.get_text()
print "獲取P段落的文字"
p_node = soup.find('p',class_='story')
print p_node.name,p_node['class'],p_node.get_text()