
Spark介紹(一)簡介
一、Spark簡介
Spark是加州大學伯克利分校AMP實驗室(Algorithms, Machines, and People Lab)開發的通用記憶體平行計算框架
Spark使用Scala語言進行實現,它是一種面向物件、函數語言程式設計語言,能夠像操作本地集合物件一樣輕鬆地操作分散式資料集,具有以下特點。
1.執行速度快:Spark擁有DAG執行引擎,支援在記憶體中對資料進行迭代計算。官方提供的資料表明,如果資料由磁碟讀取,速度是Hadoop MapReduce的10倍以上,如果資料從記憶體中讀取,速度可以高達100多倍。
2.易用性好:Spark不僅支援Scala編寫應用程式,而且支援
3.通用性強:Spark生態圈即BDAS(伯克利資料分析棧)包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等元件,這些元件分別處理Spark Core提供記憶體計算框架、SparkStreaming的實時處理應用、Spark SQL的即席查詢、MLlib或MLbase的機器學習和GraphX的圖處理。
4.隨處執行:Spark具有很強的適應性,能夠讀取HDFS、Cassandra、HBase、S3和Techyon
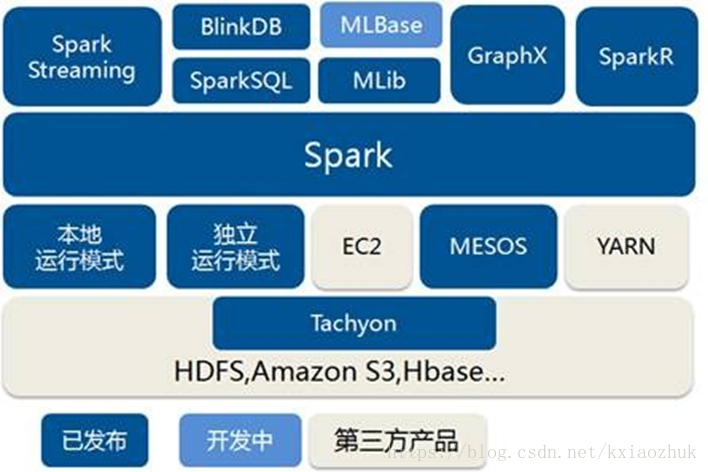
二、Spark與Hadoop差異
Spark是在借鑑了MapReduce之上發展而來的,繼承了其分散式平行計算的優點並改進了MapReduce明顯的缺陷,具體如下:
首先,Spark把中間資料放到記憶體中,迭代運算效率高。MapReduce中計算結果需要落地,儲存到磁碟上,這樣勢必會影響整體速度,而Spark支援DAG圖的分散式平行計算的程式設計框架,減少了迭代過程中資料的落地,提高了處理效率。
其次,Spark容錯性高。Spark引進了彈性分散式資料集RDD (Resilient Distributed Dataset) 的抽象,它是分佈在一組節點中的只讀物件集合,這些集合是彈性的,如果資料集一部分丟失,則可以根據“血統”(即充許基於資料衍生過程)對它們進行重建。另外在RDD計算時可以通過CheckPoint來實現容錯,而CheckPoint有兩種方式:CheckPoint Data,和Logging The Updates,使用者可以控制採用哪種方式來實現容錯。
最後,Spark更加通用。不像Hadoop只提供了Map和Reduce兩種操作,Spark提供的資料集操作型別有很多種,大致分為:Transformations和Actions兩大類。Transformations包括Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort和PartionBy等多種操作型別,同時還提供Count, Actions包括Collect、Reduce、Lookup和Save等操作。另外各個處理節點之間的通訊模型不再像Hadoop只有Shuffle一種模式,使用者可以命名、物化,控制中間結果的儲存、分割槽等。
三、Spark的適用場景
目前大資料處理場景有以下幾個型別:
1. 複雜的批量處理(Batch Data Processing),偏重點在於處理海量資料的能力,至於處理速度可忍受,通常的時間可能是在數十分鐘到數小時;
2. 基於歷史資料的互動式查詢(Interactive Query),通常的時間在數十秒到數十分鐘之間
3. 基於實時資料流的資料處理(Streaming Data Processing),通常在數百毫秒到數秒之間
目前對以上三種場景需求都有比較成熟的處理框架,第一種情況可以用Hadoop的MapReduce來進行批量海量資料處理,第二種情況可以Impala進行互動式查詢,對於第三中情況可以用Storm分散式處理框架處理實時流式資料。以上三者都是比較獨立,各自一套維護成本比較高,而Spark的出現能夠一站式平臺滿意以上需求。
通過以上分析,總結Spark場景有以下幾個:
1.Spark是基於記憶體的迭代計算框架,適用於需要多次操作特定資料集的應用場合。需要反覆操作的次數越多,所需讀取的資料量越大,受益越大,資料量小但是計算密集度較大的場合,受益就相對較小
2.由於RDD的特性,Spark不適用那種非同步細粒度更新狀態的應用,例如web服務的儲存或者是增量的web爬蟲和索引。就是對於那種增量修改的應用模型不適合
3.資料量不是特別大,但是要求實時統計分析需求
四、Spark常用術語
| 術語 |
描述 |
| Application |
Spark的應用程式,包含一個Driver program和若干Executor |
| SparkContext |
Spark應用程式的入口,負責排程各個運算資源,協調各個Worker Node上的Executor |
| Driver Program |
執行Application的main()函式並且建立SparkContext |
| Executor |
是為Application執行在Worker node上的一個程序,該程序負責執行Task,並且負責將資料存在記憶體或者磁碟上。 每個Application都會申請各自的Executor來處理任務 |
| Cluster Manager |
在叢集上獲取資源的外部服務 (例如:Standalone、Mesos、Yarn) |
| Worker Node |
叢集中任何可以執行Application程式碼的節點,執行一個或多個Executor程序 |
| Task |
執行在Executor上的工作單元 |
| Job |
SparkContext提交的具體Action操作,常和Action對應 |
| Stage |
每個Job會被拆分很多組task,每組任務被稱為Stage,也稱TaskSet |
| RDD |
是Resilient distributed datasets的簡稱,中文為彈性分散式資料集;是Spark最核心的模組和類 |
| DAGScheduler |
根據Job構建基於Stage的DAG,並提交Stage給TaskScheduler |
| TaskScheduler |
將Taskset提交給Worker node叢集執行並返回結果 |
| Transformations |
是Spark API的一種型別,Transformation返回值還是一個RDD, 所有的Transformation採用的都是懶策略,如果只是將Transformation提交是不會執行計算的 |
| Action |
是Spark API的一種型別,Action返回值不是一個RDD,而是一個scala集合;計算只有在Action被提交的時候計算才被觸發。 |