
Spark學習(一)--Spark入門介紹和安裝
本次主要介紹spark的入門概念和安裝
- Spark概念
- Spark安裝
- Spark HA 高可用部署
1. Spark概念
1.1 什麼是Spark
Spark 是一種快速、 通用、 可擴充套件的大資料分析引擎, 2009 年誕生於加州大學伯克利分校 AMPLab, 2010 年開源, 2013 年 6 月成為 Apache 孵化專案, 2014年 2 月成為 Apache 頂級專案。 目前, Spark 生態系統已經發展成為一個包含多個子專案的集合, 其中包含 SparkSQL、 Spark Streaming、 GraphX、 MLlib 等子專案,Spark 是基於記憶體計算的大資料平行計算框架。
Spark 基於記憶體計算, 提高了在大資料環境下資料處理的實時性, 同時保證了高容錯性和高可伸縮性, 允許使用者將Spark 部署在大量廉價硬體之上, 形成叢集。
1.2 Spark的優勢
Spark 是一個開源的類似於 Hadoop MapReduce 的通用的平行計算框架,Spark基於 map reduce 演算法實現的分散式計算, 擁有 Hadoop MapReduce 所具有的優點; 但不同於 MapReduce 的是 Spark 中的 Job 中間輸出和結果可以儲存在記憶體中,從而不再需要讀寫 HDFS, 因此 Spark 能更好地適用於資料探勘與機器學習等需要迭代的 map-reduce 的演算法。 Spark 是 MapReduce 的替代方案, 而且相容 HDFS、 Hive, 可融入 Hadoop 的生態系統, 以彌補 MapReduce 的不足。
1.3 Spark的特點
-
快 與 Hadoop 的 MapReduce 相比, Spark 基於記憶體的運算要比MR快 100 倍以上, Spark基於硬碟的運算也要比MR快 10 倍以上。 Spark 實現了高效的 DAG 執行引擎, 可以通過基於記憶體來高效處理資料流。
-
易用 Spark 支援 Java、 Python 和 Scala 的 API, 還支援超過 80 種高階演算法, 使使用者可以快速構建不同的應用。 而且 Spark 支援互動式的 Python 和 Scala 的 shell, 可以非常方便地在這些 shell 中使用 Spark 叢集來驗證解決問題的方法。
-
通用 Spark 提供了統一的解決方案。 Spark 可以用於批處理、 互動式查詢(Spark SQL) 、 實時流處理(Spark Streaming) 、 機器學習(Spark MLlib) 和圖計算(GraphX) 。 這些不同型別的處理都可以在同一個應用中無縫使用。 Spark統一的解決方案非常具有吸引力, 畢竟任何公司都想用統一的平臺去處理遇到的問題, 減少開發和維護的人力成本和部署平臺的物力成本。
-
相容性好 Spark 可以非常方便地與其他的開源產品進行融合。 比如, Spark 可以使用 Hadoop 的 YARN 和 Apache Mesos 作為它的資源管理和排程器, 器, 並且可以處理所有 Hadoop 支援的資料, 包括 HDFS、 HBase 和 Cassandra 等。 這對於已經部署 Hadoop 叢集的使用者特別重要, 因為不需要做任何資料遷移就可以使用 Spark的強大處理能力。 Spark 也可以不依賴於第三方的資源管理和排程器, 它實現了Standalone 作為其內建的資源管理和排程框架, 這樣進一步降低了 Spark 的使用門檻, 使得所有人都可以非常容易地部署和使用 Spark。 此外, Spark 還提供了在EC2 上部署 Standalone 的 Spark 叢集的工具。


2. Spark的安裝
2.1 下載 spark 安裝包
2. 2 解壓安裝包
tar -zxvf spark-2.0.2-bin-hadoop2.7.tgz
2.3 重新命名目錄
mv spark-2.0.2-bin-hadoop2.7 spark
2.4 修改配置檔案
配置檔案目錄在 /opt/bigdata/spark/conf
#配置 java 環境變數
export JAVA_HOME=/export/server/jdk1.8.0_45
#指定 spark 老大 Master 的 IP
export SPARK_MASTER_HOST=nodel01
#指定 spark 老大 Master 的埠
export SPARK_MASTER_PORT=7077
- vi slaves 修改檔案(先把 slaves.template 重新命名為 slaves)
#worker的啟動節點配置
nodel02
nodel03
2.5 拷貝檔案到其他主機
通過 scp 命令將 spark 的安裝目錄拷貝到其他機器上
scp -r /export/server/spark nodel02:/export/server/
scp -r /export/server/spark nodel03:/export/server/
2.6配置 spark 環境變數
將 spark 新增到環境變數,新增以下內容到 /etc/profile
#spark
export SPARK_HOME=/export/server/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
2.7啟動和通知spark
#在主節點啟動spark
$spark /sbin/start-all.sh
#在主節點停止spark
$spark /sbin/stop-all.sh
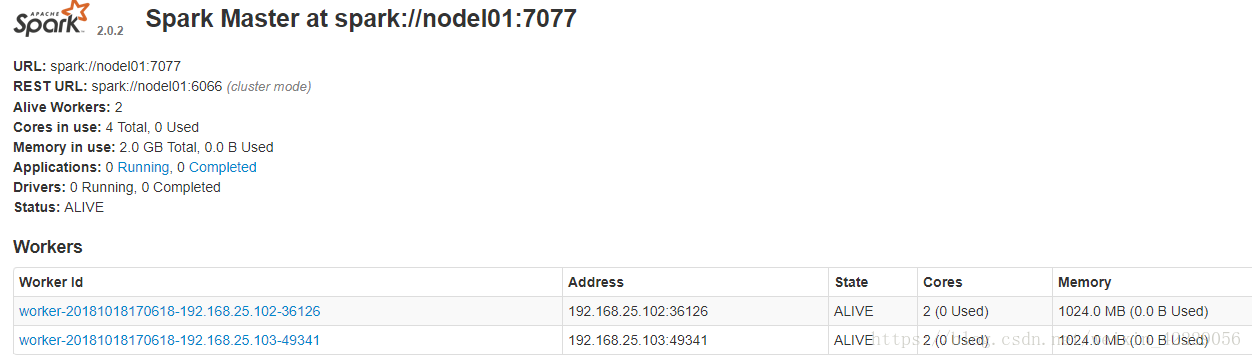
2.8 spark的web介面
正常啟動 spark 集群后, 可以通過訪問 http://nodel01:8080,檢視 spark 的 web 介面,檢視相關資訊。
3. Spark HA 高可用部署
3.1 高可用部署說明
Spark Standalone 叢集是 Master-Slaves 架構的叢集模式, 和大部分的Master-Slaves 結構叢集一樣, 存在著 Master 單點故障的問題。 如何解決這個單點故障的問題, Spark 提供了兩種方案:
- 基 於 文 件 系 統 的 單 點 恢 復 主要用於開發或測試環境。 當 spark 提供目錄儲存 spark Application和 worker 的註冊資訊, 並將他們的恢復狀態寫入該目錄中, 這時, 一旦 Master發生故障, 就可以通過重新啟動 Master 程序( sbin/start-master.sh) , 恢復已執行的 spark Application 和 worker 的註冊資訊。
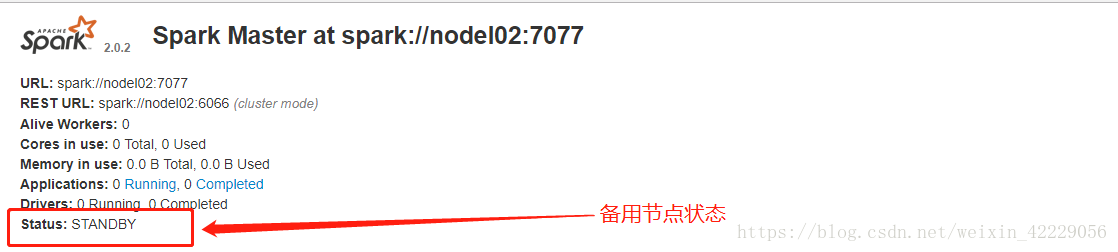
- 基於 zookeeper 的 Standby Masters 用於生產模式。 其基本原理是通過 zookeeper 來選舉一個 Master, 其他的 Master 處於 Standby 狀態。 將 spark 叢集連線到同一個 ZooKeeper 例項並啟動多個 Master, 利用 zookeeper 提供的選舉和狀態儲存功能, 可以使一個 Master被選舉成活著的 master, 而其他 Master 處於 Standby 狀態。 如果現任 Master死去, 另一個 Master 會通過選舉產生, 並恢復到舊的 Master 狀態, 然後恢復排程。 整個恢復過程可能要 1-2 分鐘。
3.2 基於zookeeper的高可用叢集部署
該 HA 方案使用起來很簡單, 首先需要搭建一個 zookeeper 叢集, 然後啟動 zooKeeper 叢集, 最後在不同節點上啟動 Master。 具體配置如下: 1) vi spark-env.sh 註釋掉 export SPARK_MASTER_HOST=nodel01 2)在 spark-env.sh 新增 SPARK_DAEMON_JAVA_OPTS, 內容如下:
//HA的配置檔案
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=nodel01:2181,nodel02:2181,nodel03:2181, -Dspark.deploy.zookeeper.dir=/spark"
3)分發到另外兩個節點
scp spark-env.sh nodel02:/export/server/spark/conf/
scp spark-env.sh nodel03:/export/server/spark/conf/
3.3 啟動HA叢集
// 1.首先在主節點啟動zookeeper
startzk.sh
//2.在主節點啟動spark
$spark /sbin/start-all.sh
//3.在任意分節點啟動saprk備用節點
$spark /sbin/start-master.sh
//jps檢視程序
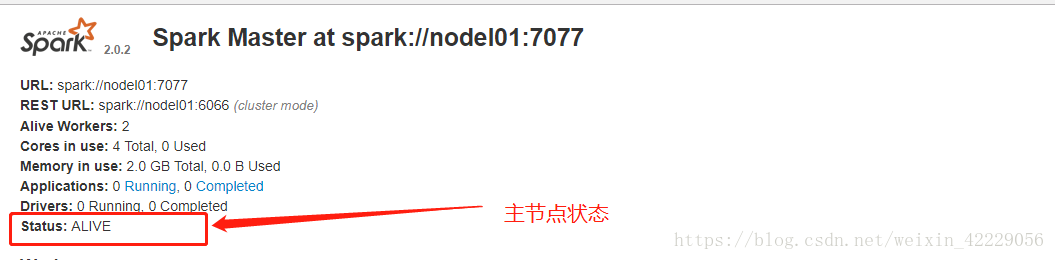
3.4 HA的web頁面
主節點
本次結束