
LeNet-5模型實現
現在逐漸的開始接觸深度學習的知識,最近看了Ng老師的深度學習視訊,看到裡面介紹了幾種經典的卷積神經網路其中就包含LeNet-5所以就照葫蘆畫瓢,用tensorflow實現了一下最原始的LeNet-5模型,順便也是為了學習tensorflow。雖然程式碼很簡單,由於是新手遇到了很多意想不到的坑。所以寫篇部落格記錄一下。
開始一定要牢記的一句話,一定要把模型分析透了再去寫程式碼,每一層的輸入是什麼shape,輸出是什麼shape。最好寫紙上,要不寫著寫著就亂了。(笑哭)
模型的結構很簡單,上圖:
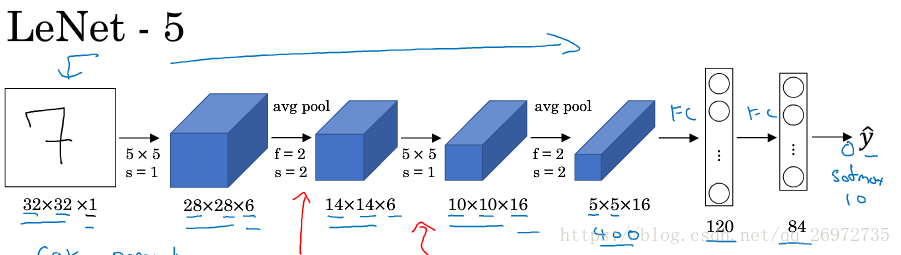
模型一共進行了兩次卷積,每次卷積後面有一層平均池化層,最後再加兩層全連線層。 實驗用的資料是手寫數字。每一層具體如下:
卷積層:
輸入層:輸入的圖片大小為:28*28*1
第一層卷積:filter_size為5*5,步長(s)為1,卷積核的個數為6,no padding,啟用函式為relu
第一層平均池化:filter_size為2*2,步長(s)為2(這種池化會使輸入的feature map長和寬縮小一倍),no padding
第二層卷積:filter_size為5*5,步長(s)為1,卷積核的個數為16, no padding,啟用函式為relu
第二層平均池化:filter_size為2*2,步長(s)為2,no padding
全連線層:
第一層120個節點,啟用函式為relu
第二層84個節點,啟用函式為relu
輸出層10個節點,沒有啟用函式
def inference(self, input_tensor): with tf.variable_scope("layer1-conv1"): conv1_weight = tf.get_variable(name = "conv1_variable", shape=[5,5,1,6], initializer=tf.truncated_normal_initializer()) conv1_bias = tf.get_variable(name = "conv1_bias", shape = [6], initializer=tf.constant_initializer(0.0)) conv1 = tf.nn.conv2d(input = input_tensor, filter = conv1_weight, strides = [1, 1, 1, 1], padding = "VALID") relu1 = tf.nn.relu(tf.add(conv1, conv1_bias)) pool1 = tf.nn.avg_pool(relu1, ksize = [1, 2, 2, 1], strides = [1, 2, 2, 1], padding = "VALID") with tf.variable_scope("layer2-conv2"): conv2_weight = tf.get_variable(name = "conv2_variable", shape=[5,5,6,16], initializer=tf.truncated_normal_initializer()) conv2_bias = tf.get_variable(name = "conv2_bias", shape = [16], initializer=tf.constant_initializer(0.0)) conv2 = tf.nn.conv2d(input = pool1, filter = conv2_weight, strides = [1, 1, 1, 1], padding = "VALID") relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_bias)) pool2 = tf.nn.avg_pool(relu2, ksize = [1,2,2,1], strides = [1,2,2,1], padding = "VALID") with tf.variable_scope("layer3-fc1"): conv_layer_flatten = tf.layers.flatten(inputs = pool2) #[batch_size, 256] fc1_variable = tf.get_variable(name = 'fc1_variable', shape = [256, 120], initializer = tf.random_normal_initializer()) * 0.01 fc1_bias = tf.get_variable(name = 'fc1_bias', shape = [1, 120], initializer = tf.constant_initializer(value=0)) fc1 = tf.nn.relu(tf.add(tf.matmul(conv_layer_flatten, fc1_variable), fc1_bias)) #[batch_size, 120] with tf.variable_scope("layer4-fc2"): fc2_variable = tf.get_variable(name = "fc2_variable", shape=[120,84], initializer=tf.random_normal_initializer()) * 0.01 #[batch_size, 84] fc2_bias = tf.get_variable(name = "fc2_bias", shape=[1, 84],initializer = tf.constant_initializer(value=0)) fc2 = tf.nn.relu(tf.add(tf.matmul(fc1, fc2_variable), fc2_bias)) #[batch_size, 84] with tf.variable_scope("layer5-output"): output_variable = tf.get_variable(name = "output_variable", shape = [84, 10],initializer = tf.random_normal_initializer()) * 0.01 output_bias = tf.get_variable(name = "output_bias", shape = [1, 10],initializer = tf.constant_initializer(value=0)) output = tf.add(tf.matmul(fc2, output_variable), output_bias) #[batch_size, 10] return output
在模型訓練的過程中出現了一些問題,開始我為了讓初始化的權值儘量都小一些,讓每一層的卷積核的權重初始化時都乘以0.01,但是發現如果這麼做損失函式收斂的很慢甚至都不會收斂。剛開始的時候我以為是我程式碼有問題,那個費勁的找bug啊!都是淚。我原來一直認為神經網路權值初始化時應該儘量小一些,看來也不是這樣的。經過了千辛萬苦模型終於訓練好了。
最終在訓練集、測試集、驗證集上的精度如下:
if __name__ == "__main__":
model = LeNet5()
# model.train(iter_num=200)
#evaluate model on trainSet
images_train = model.mnist.train.images
y_true_train = model.mnist.train.labels
images_train = images_train.reshape([-1, 28,28,1])
y_true_train = np.argmax(y_true_train, axis=1).reshape(-1, 1)
model.evaluate(images_train, y_true_train) #accuracy is 0.9611818181818181
#evaluate model on testSet
images_test = model.mnist.test.images.reshape([-1, 28,28,1])
y_true_test = model.mnist.test.labels
y_true_test = np.argmax(y_true_test, axis = 1).reshape(-1, 1)
model.evaluate(images_test, y_true_test) #accuracy is 0.9645
#evaluate model on validate
images_validation = model.mnist.validation.images.reshape([-1, 28,28,1])
y_true_validation = model.mnist.validation.labels
y_true_validation = np.argmax(y_true_validation, axis = 1).reshape(-1, 1)
model.evaluate(images_validation, y_true_validation) #accuracy is 0.9648完整程式碼在我的github中,地址:https://github.com/NewQJX/DeepLearning/tree/master/LeNet5