CNN的LeNet-5模型及其TensorFlow實現
卷積神經網路的常見網路結構
常見的架構圖如下:
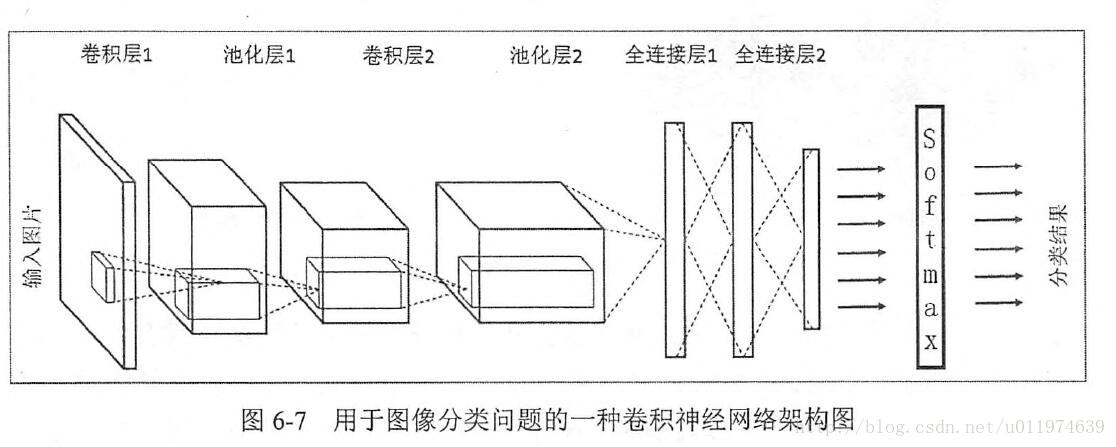
LeNet-5模型結構圖如下圖:

LeNet-5模型總共有7層。
第一層:卷積層
第一層卷積層的輸入為原始的影象,原始影象的尺寸為32×32×1。卷積層的過濾器尺寸為5×5,深度為6,不使用全0補充,步長為1。由於沒有使用全0補充,所以這一層的輸出的尺寸為32-5+1=28,深度為6。這一個卷積層總共有5×5×1×6+6=156個引數,其中6為偏置項引數個數,卷積層的引數個數只和過濾器的尺寸,深度以及當前層節點矩陣的深度有關。因為下一層節點矩陣有28×28×6=4704個節點,每個節點和5×5=25個當前層節點相連,所以本層卷積層總共有4704×(25+1)=122304個連線。
第二層:池化層
這一層的輸入為第一層的輸出,是一個28×28×6的節點矩陣。本層採用的過濾器大小為2×2,步長為2,所以本層的輸出矩陣大小為14×14×6。
第三層:卷積層
本層的輸入矩陣大小為14×14×6,採用的過濾器大小為5×5,深度為16,不使用全0補充,步長為1。這一層的輸出的尺寸為14-5+1=10,深度為16,即輸出矩陣大小為10×10×16。本層引數有5×5×6×16+16=2416個,連線有10×10×16×(5×5+1)=41600個。
第四層:池化層
本層的輸入矩陣大小為10×10×16,採用的過濾器大小為2×2,步長為2,本層的輸出矩陣大小為5×5×16。
第五層:全連線層
本層的輸入矩陣大小為5×5×16,在LeNet-5模型的論文中將這一層稱為卷積層,但是因為過濾器的大小就是5×5,所以和全連線層沒有區別,這裡直接看成全連線層。本層輸入為5×5×16矩陣,將其拉直為一個長度為5×5×16的向量,即將一個三維矩陣拉直到一維空間以向量的形式表示,這樣才可以進入全連線層進行訓練。本層的輸出節點個數為120,所以總共有5×5×16×120+120=48120個引數。
第六層:全連線層
本層的輸入節點個數為120個,輸出節點個數為84個,總共有120×84+84=10164個引數。
第七層:全連線層
本層的輸入節點個數為84個,輸出節點個數為10個,總共有84×10+10=850個引數。
接下來以TensorFlow程式碼展示一個基於LeNet-5模型的mnist數字識別程式碼。
(1)mnist_inference.py 構建CNN網路
import tensorflow as tf
INPUT_NODE=784
OUTPUT_NODE=10
NUM_CHANNELS=1
IMAGE_SIZE=28
CONV1_DEEP=6
CONV1_SIZE=5
CONV2_DEEP=16
CONV2_SIZE=5
FC_SIZE=120
FC2_SIZE=84
NUM_LABELS=10
#搭建CNN
def inference(input_tensor,train,regularizer):
#第一層卷積層
# 第一層:卷積層,過濾器的尺寸為5×5,深度為6,不使用全0補充,步長為1。
# 尺寸變化:32×32×1->28×28×6
with tf.variable_scope('layer1-conv1'):
conv1_weights=tf.get_variable(
"weight",[CONV1_SIZE,CONV1_SIZE ,NUM_CHANNELS,CONV1_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1)
)
conv1_biases=tf.get_variable(
"biases",[CONV1_DEEP],initializer=tf.constant_initializer(0.0)
)
conv1=tf.nn.conv2d(
input_tensor,conv1_weights,strides=[1,1,1,1],padding='VALID'
)
relu1=tf.nn.relu(tf.nn.bias_add(conv1,conv1_biases))
# 第2層卷積層
# 第二層:池化層,過濾器的尺寸為2×2,使用全0補充,步長為2。
# 尺寸變化:28×28×6->14×14×6
with tf.name_scope('layer2-pool1'):
pool1=tf.nn.max_pool(
relu1,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME'
)
# 第三層:卷積層,過濾器的尺寸為5×5,深度為16,不使用全0補充,步長為1。
# 尺寸變化:14×14×6->10×10×16
with tf.variable_scope('layer3-conv2'):
conv2_weights = tf.get_variable(
"weight", [CONV2_SIZE, CONV2_SIZE, CONV1_DEEP, CONV2_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1)
)
conv2_biases = tf.get_variable(
"biases", [CONV2_DEEP], initializer=tf.constant_initializer(0.0)
)
conv2 = tf.nn.conv2d(
pool1, conv2_weights, strides=[1, 1, 1, 1], padding='VALID'
)
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases))
# 第四層:池化層,過濾器的尺寸為2×2,使用全0補充,步長為2。
# 尺寸變化:10×10×6->5×5×16
with tf.name_scope('layer4-pool2'):
pool2 = tf.nn.max_pool(
relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME'
)
# 將第四層池化層的輸出轉化為第五層全連線層的輸入格式。
# 第四層的輸出為5×5×16的矩陣,然而第五層全連線層需要的輸入格式
# 為向量,所以我們需要把代表每張圖片的尺寸為5×5×16的矩陣拉直成一個長度為5×5×16的向量。
# 舉例說,每次訓練64張圖片,
# 那麼第四層池化層的輸出的size為(64,5,5,16),拉直為向量,
# nodes=5×5×16=400,尺寸size變為(64,400)
pool_shape=pool2.get_shape().as_list()
nodes=pool_shape[1]*pool_shape[2]*pool_shape[3]
reshaped = tf.reshape(pool2,[-1,nodes])
# 第五層:全連線層,nodes=5×5×16=400,400->120的全連線
# 尺寸變化:比如一組訓練樣本為64,那麼尺寸變化為64×400->64×120
# 訓練時,引入dropout,dropout在訓練時會隨機將部分節點的輸出改為0,
# dropout可以避免過擬合問題。
# 這和模型越簡單越不容易過擬合思想一致,和正則化限制權重的大小,
# 使得模型不能任意擬合訓練資料中的隨機噪聲,以此達到避免過擬合思想一致。
# 本文最後訓練時沒有采用dropout,
# dropout項傳入引數設定成了False,因為訓練和測試寫在了一起沒有分離,不過大家可以嘗試。
with tf.variable_scope('layer5-fc1'):
fc1_weights=tf.get_variable(
"weight",[nodes,FC_SIZE],
initializer=tf.truncated_normal_initializer(stddev=0.1)
)
if regularizer!=None:
tf.add_to_collection('losses',regularizer(fc1_weights))
fc1_biases=tf.get_variable(
"biases",[FC_SIZE],initializer=tf.constant_initializer(0.1)
)
fc1=tf.nn.relu(tf.matmul(reshaped,fc1_weights)+fc1_biases)
if train:
fc1=tf.nn.dropout(fc1,0.5)
# 第六層:全連線層,120->84的全連線
# 尺寸變化:比如一組訓練樣本為64,那麼尺寸變化為64×120->64×84
with tf.variable_scope('layer6-fc2'):
fc2_weights=tf.get_variable(
"weight",[FC_SIZE,FC2_SIZE],
initializer=tf.truncated_normal_initializer(stddev=0.1)
)
if regularizer!=None:
tf.add_to_collection('losses',regularizer(fc2_weights))
fc2_biases = tf.get_variable(
'biases',
[FC2_SIZE],
initializer=tf.truncated_normal_initializer(stddev=0.1)
)
fc2 = tf.nn.relu(tf.matmul(fc1, fc2_weights) + fc2_biases)
if train:
fc2 = tf.nn.dropout(fc2, 0.5)
#第七層:全連線層(近似表示),84->10的全連線
#尺寸變化:比如一組訓練樣本為64,那麼尺寸變化為64×84->64×10。
# 最後,64×10的矩陣經過softmax之後就得出了64張圖片分類於每種數字的概率,
#即得到最後的分類結果。
with tf.variable_scope('layer7-fc3'):
fc3_weights = tf.get_variable(
'weight',[FC2_SIZE,NUM_LABELS],
initializer=tf.truncated_normal_initializer(stddev=0.1)
)
if regularizer != None:
tf.add_to_collection('losses',regularizer(fc3_weights))
fc3_biases = tf.get_variable('biases',
[NUM_LABELS],
initializer=tf.truncated_normal_initializer(stddev=0.1)
)
logit = tf.matmul(fc2,fc3_weights) + fc3_biases
return logit
(2)mnist_train.py訓練和測試
from skimage import io,transform
import os
import glob
import numpy as np
import tensorflow as tf
import mnist_inference
#將所有的圖片重新設定尺寸為32*32
w = 32
h = 32
#mnist資料集中訓練資料和測試資料儲存地址
train_path = "C:/Users/casgj/PycharmProjects/Teansorflow_exam1/mnist/train/"
test_path = "C:/Users/casgj/PycharmProjects/Teansorflow_exam1/mnist/test/"
#讀取圖片及其標籤函式
def read_image(path):
label_dir = [path+x for x in os.listdir(path) if os.path.isdir(path+x)]
images = []
labels = []
for index,folder in enumerate(label_dir):
for img in glob.glob(folder+'/*.png'):
print("reading the image:%s"%img)
image = io.imread(img)
image = transform.resize(image,(w,h,mnist_inference.NUM_CHANNELS))
images.append(image)
labels.append(index)
return np.asarray(images,dtype=np.float32),np.asarray(labels,dtype=np.int32)
#讀取訓練資料及測試資料
train_data,train_label = read_image(train_path)
test_data,test_label = read_image(test_path)
#打亂訓練資料及測試資料
train_image_num = len(train_data)
train_image_index = np.arange(train_image_num)
np.random.shuffle(train_image_index)
train_data = train_data[train_image_index]
train_label = train_label[train_image_index]
test_image_num = len(test_data)
test_image_index = np.arange(test_image_num)
np.random.shuffle(test_image_index) #numpy.random.shuffle打亂順序函式
test_data = test_data[test_image_index]
test_label = test_label[test_image_index]
#輸入
x = tf.placeholder(tf.float32,[None,w,h,mnist_inference.NUM_CHANNELS],name='x')
y_ = tf.placeholder(tf.int32,[None],name='y_')
#-------構建CNN---------------------
#正則化,交叉熵,平均交叉熵,損失函式,最小化損失函式,預測和實際equal比較,tf.equal函式會得到True或False,
#正則化
regularizer = tf.contrib.layers.l2_regularizer(0.001)
#前向網路結果
y = mnist_inference.inference(x,False,regularizer)
#損失函式
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=y_)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
#最小化損失函式
train_op = tf.train.AdamOptimizer(0.001).minimize(loss)
#accuracy首先將tf.equal比較得到的布林值轉為float型,即True轉為1.,False轉為0,
# 最後求平均值,即一組樣本的正確率。
#比如:一組5個樣本,tf.equal比較為[True False True False False],
# 轉化為float型為[1. 0 1. 0 0],準確率為2./5=40%。
correct_prediction = tf.equal(tf.cast(tf.argmax(y,1),tf.int32),y_)
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#每次獲取batch_size個樣本進行訓練或測試
def get_batch(data,label,batch_size):
for start_index in range(0,len(data)-batch_size+1,batch_size):
slice_index = slice(start_index,start_index+batch_size)
yield data[slice_index],label[slice_index]
#建立Session會話
with tf.Session() as sess:
#初始化所有變數(權值,偏置等)
sess.run(tf.global_variables_initializer())
#將所有樣本訓練10次,每次訓練中以64個為一組訓練完所有樣本。
#train_num可以設定大一些。
train_num = 10
batch_size = 64
for i in range(train_num):
train_loss,train_acc,batch_num = 0, 0, 0
for train_data_batch, train_label_batch in get_batch(train_data, train_label, batch_size):
_, err, acc = sess.run([train_op, loss, accuracy], feed_dict={x: train_data_batch, y_: train_label_batch})
train_loss += err;
train_acc += acc;
batch_num += 1
print("train loss:", train_loss / batch_num)
print("train acc:", train_acc / batch_num)
test_loss,test_acc,batch_num = 0, 0, 0
for test_data_batch,test_label_batch in get_batch(test_data,test_label,batch_size):
err2,acc2 = sess.run(
[loss,accuracy],
feed_dict={x:test_data_batch,y_:test_label_batch}
)
test_loss += err;
test_acc += acc;
batch_num += 1
print("test loss:", test_loss / batch_num)
print("test acc:", test_acc / batch_num)
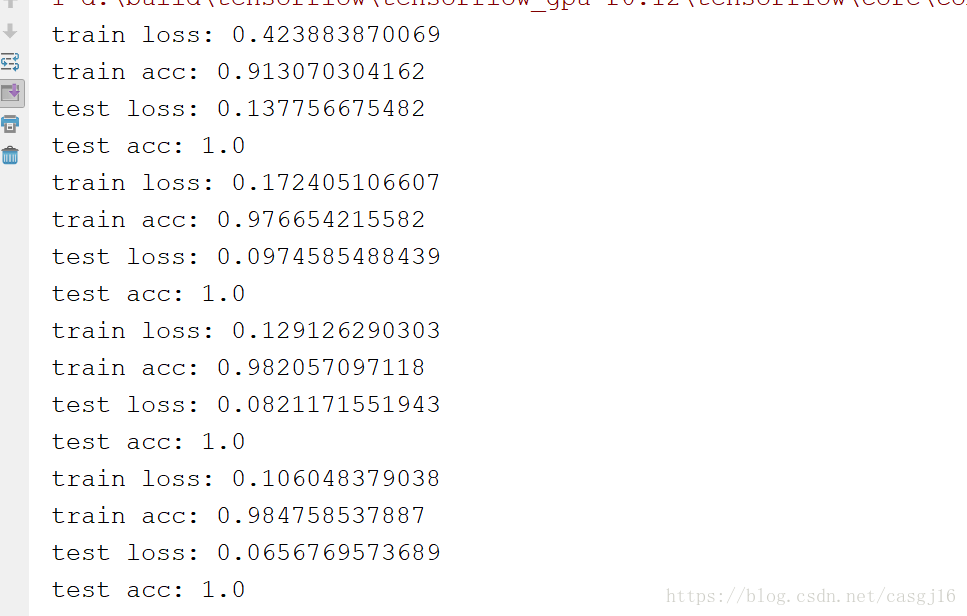
(3)實驗結果