
淺議過擬合現象(overfitting)以及正則化技術原理
1. 過擬合(overfitting)簡介
0x1:假設空間(hypothesis space)
給定學習演算法 A,它所考慮的所有可能概念的集合稱為假設空間,用符號 H 表示。對於假設空間中的任一概念,我們用符號 h 表示,由於並不能確定它是否真是目標概念,因此稱為“假設”(hypothesis)
1. 模型空間/模型搜尋空間
模型空間針對的是模型結構上的定義,例如使用線性迴歸模型、高斯分佈模型、DNN複合線性模型、包含非線性啟用函式的非線性DNN模型、CNN模型等。
即使是選定了線性多項式函式作為目標函式,函式的專案有多少?每項的冪次是多少?這些都屬於模型搜尋的範疇。
2. 模型引數搜尋空間
模型引數搜尋,也就是所謂的模型訓練過程,本質上是在做模型超引數的搜尋過程,我們本章接下來統一都叫引數搜尋過程,筆者知道它們二者是相同的即可。
引數搜尋解決的最主要的問題就是“權重分配”,機器學習中的目標函式都是多元的,即由大量的“原子判別函式”組成,所有的原子判別函式共同作用於待預測資料,給出一個最終的綜合判斷結果。
引數搜尋會根據訓練資料中包含的概率分佈,對所有的原子判別函式的權重進行最優化調整,使其最大程度地擬合訓練資料。
0x2:什麼是過擬合?
首先,先丟擲筆者的幾個觀點:
觀點1:過擬合不是一個理論分析的結果,目前還不存在一個明確的理論,可以量化地分析過擬合是否發生、以及過擬合的程度(數值化)有多少。過擬合是一種可以被觀測到的現象,在具體的場景中,當觀測到某些現象的時候,我們說,此時發生了過擬合
觀點2:不是說使用了複雜函式就一定代表了過擬合,複雜函式不等於過擬合。
1. 判斷髮生過擬合的現象 - 訓練集上得到的模型無法適應測試集
我們通過一個例子來討論過擬合現象
1)資料集
假設我們要對一個簡單的資料集建立模型:

我們的目標是構建一個模型,得到基於 x 的能預測 y 的函式。
2)選用複雜函式進行擬合
這裡假設我們把 y 建模為關於 x 的多項式,這裡多項式就是模型選擇的結果。
並且省略模型引數搜尋過程,直接假設最終多項式為![]() 。
。
函式擬合的影象如下:

可以看到,函式精確擬合了資料
3)選用簡單函式進行擬合
使用線性模型![]()

4)是否發生了過擬合呢?哪個模型更容易產生過擬合呢?
嚴格來說,是否發生了過擬合,哪個模型更可能產生過擬合,這兩個問題非常微妙。簡單來說,答案是:實踐是檢驗真理的唯一標準。
我們說過,過擬合是一種在專案實踐中遇到的一個常見的現象,並不是一種高深的理論。
筆者希望向讀者朋友傳達的一個觀點是:
上面兩種函式(複雜的和簡單的),都有可能產生過擬合,也都可能不產生過擬合,也可能複雜函式產生過擬合而簡單函式泛化能力很好,所謂的“簡單函式的泛化能力更好”不是一個有著堅實理論和數學基礎的理論定理,它只是在長久的資料科學專案中,資料科學家們發現的一個普遍現象。
可以理解為屬於經驗科學的一個範疇,簡單的模型不容易產生過擬合,簡單的模型泛化能力更好,甚至所謂的奧卡姆剃刀原理。這個經驗在很多時候是有效的,我們也沒有什麼理由不去應用這個經驗。畢竟資料科學還是一個偏向實踐和以結果說話的學科,得到好的結果是最重要的。
只是說,筆者希望讀者朋友們不要太過於簡單粗暴地認死理,認為說你設計的模型一定就需要遵循簡單原理,凡是複雜的模型就是不好的。
判斷髮生過擬合的方法很簡單,就是測試集。當我們用一份新的測試集去測試模型的時候,如果precision和recall發生了很嚴重的下降,則說明發生了過擬合,不管是什麼內在原因(我們後面會分析可能的原因),過擬合肯定是發生了,模型在訓練集和測試集上表現不一致就是過擬合的最主要的現象。
2. 過擬合產生的本質原因
過擬合發生的本質原因,是由於監督學習問題的不適定。過擬合現象的發生原因,可以分解成以下三點:
1. 訓練集和測試機特徵分佈不一致: 假如給一群天鵝讓機器來學習天鵝的特徵,經過訓練後,知道了天鵝是有翅膀的,天鵝的嘴巴是長長的彎曲的,天鵝的脖子是長長的有點曲度,天鵝的整個體型像一個“2”且略大於鴨子.這時候你的機器已經基本能區別天鵝和其他動物了。但是很不巧訓練集中的天鵝全是白色的,於是機器經過學習後,會認為天鵝的羽毛都是白的,以後看到羽毛是黑的天鵝就會認為那不是天鵝。 可以看到,訓練集中的規律,“天鵝的體型是全域性特徵”,但是“天鵝的羽毛是白的”這實際上並不是所有天鵝都有的特徵,只是區域性樣本的特徵。 機器在學習全域性特徵的同時,又大量學習了局部特徵,這才導致了泛化能力變產,最終導致不能識別黑天鵝的情況. 2. 在有限的樣本中搜索過大的模型空間 在高中數學我們知道,從 n 個(線性無關)方程一定可以解 n 個變數,但是解 n+1 個變數就會解不出。因為有2個變數可能不在一個維度上。 在監督學習中,往往資料(對應了方程)遠遠少於模型空間(對應了變數)。 在有監督學習中,如果訓練樣本數小於模型搜尋空間,則有限的訓練資料不能完全反映出一個模型的好壞,然而我們卻不得不在這有限的資料上挑選模型,因此我們完全有可能挑選到在訓練資料上表現很好而在測試資料上表現很差的模型,因為我們完全無法知道模型在測試資料上的表現。 顯然,如果模型空間很大,也就是有很多很多模型可以給我們挑選,那麼挑到對的模型的機會就會很小。 3. 訓練過程中函式過多吸收了噪音資料的影響 fit model的時候加的parameter太多了,導致model太精準地抓住了這組資料的所有variance,不管是主要的資料趨勢帶來的variance還是噪音帶來的variance都一併被擬合在了模型裡。 用這個模型去預測原資料肯定是準確性更高,但放在一組具有相同趨勢但細節不同的資料裡時,預測效果就會下降。
0x3:複雜函式一定不好嗎?複雜函式一定會導致過擬合嗎?
我們從介紹兩個正確結果是複雜模型的例子開始這個小節的討論。
1. 複雜函式得到正確結果的例子
在 1940 年代物理學家馬塞爾施恩(Marcel Schein)宣佈發現了一個新的自然粒子。
他工作所在的通用電氣公司欣喜若狂並廣泛地宣傳了這一發現。但是物理學家漢斯貝特(Hans Bethe)卻懷疑這一發現。貝特拜訪了施恩,並且查看了新粒子的軌跡圖表。施恩向貝特一張一張地展示,但是貝特在每一張圖表上都發現了一些問題,這些問題暗示著資料應該被丟棄。
最後,施恩向貝特展示了一張看起來不錯的圖表。貝特說它可能只是一個統計學上的巧合。施恩說「是的,但是這種統計學巧合的機率,即便是按照你自己的公式,也只有五分之一。」貝特說「但是我們已經看過了五個圖表。」最後,施恩說道「但是在我的圖表上,每一個較好的圖表,你都用不同的理論來解釋,然而我有一個假設可以解釋所有的圖表,就是它們是新粒子。」貝特迴應道「你我的學說的唯一區別在於你的是錯誤的而我的都是正確的。你簡單的解釋是錯的,而我複雜的解釋是正確的。」隨後的研究證實了大自然是贊同貝特的學說的,之後也沒有什麼施恩的粒子了。
這個例子中,施恩聲稱自己發現的新粒子,就代表了一種簡單模型。
另一個例子是,1859 年天文學家勒維耶(Urbain Le Verrier)發現水星軌道沒有按照牛頓的引力理論,形成應有的形狀。
它跟牛頓的理論有一個很小很小的偏差,一些當時被接受的解釋是,牛頓的理論或多或少是正確的,但是需要一些小小的調整。1916 年,愛因斯坦表明這一偏差可以很好地通過他的廣義相對論來解釋,這一理論從根本上不同於牛頓引力理論,並且基於更復雜的數學。儘管有額外的複雜性,但我們今天已經接受了愛因斯坦的解釋,而牛頓的引力理論,即便是調整過的形式,也是錯誤的。這某種程度上是因為我們現在知道了愛因斯坦的理論解釋了許多牛頓的理論難以解釋的現象。此外,更令人印象深刻的是,愛因斯坦的理論準確的預測了一些牛頓的理論完全沒有預測的現象。但這些令人印象深刻的優點在早期並不是顯而易見的。如果一個人僅僅是以樸素這一理由來判斷,那麼更好的理論就會是某種調整後的牛頓理論。
在這個例子中,牛頓定理,就代表了一種簡單模型。
2. 故事背後的意義
這些故事有三個意義:
第一,判斷兩個解釋哪個才是真正的「簡單」是一個非常微妙的事情;
第二,即便我們能做出這樣的判斷,簡單是一個必須非常謹慎使用的指標;
第三,真正測試一個模型的不是簡單與否,更重要在於它在預測新的情況時表現如何;
0x4:解決過擬合的一個有效的方法 - 正則化
謹慎來說,經驗表明正則化的神經網路(在傳統機器學習演算法中也一樣)通常要比未正則化的網路泛化能力更好。
事實上,研究人員仍然在研究正則化的不同方法,對比哪種效果更好,並且嘗試去解釋為什麼不同的方法有更好或更差的效果。所以你可以看到正則化是作為一種「雜牌軍」存在的。雖然它經常有幫助,但我們並沒有一套令人滿意的系統理解為什麼它有幫助,我們有的僅僅是沒有科學依據的經驗法則。
筆者翻閱了大量的書籍和文獻,在《機器學習導論》、《深入理解機器學習》這兩本書的前部分章節中,介紹一些一些理論分析框架,可以從側面對過擬合和正則化帶來泛化能力上的優化背後的原理做了一些解釋。篇幅非常長也很理論化,建議讀者自行購書閱讀。
筆者這裡做一個概括性的總結:
1. 經典的 bias-variance decomposition; 2. PAC-learning 泛化界解釋; 3. Bayes先驗解釋,這種解釋把正則化變成先驗
1. 正則化作用一 - 減少權值引數個數
減小權值引數個數,主要是為了解決假設空間太大的問題。
先看一下二次多項式和十次多項式的區別——
二次多項式:
十次多項式:
下圖可以看出來十次項的形式很複雜,雖然可以擬合訓練集全部資料,但是“可能”嚴重過擬合。我們嘗試把十次項出現的機會打壓一下,即減少權值引數個數。
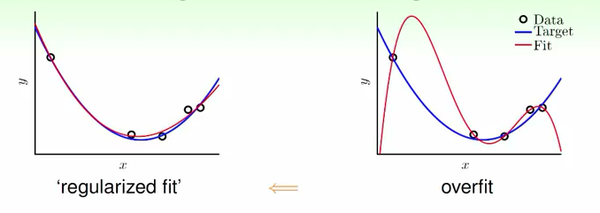

其實只要讓後面的w係數全等於零,那麼二次多項式和十次多項式本質上是一樣的,這樣子就客觀上把假設空間縮小了,這裡就是正則化的過程。
2. 正則化作用二 - 降低權值引數數值
擬合過程中通常都傾向於讓權值儘可能小,最後構造一個所有引數都比較小的模型。
因為一般認為引數值小的模型比較簡單,能適應不同的資料集,也在一定程度上避免了過擬合現象。
可以設想一下對於一個線性迴歸方程,若引數很大,那麼只要資料偏移一點點,就會對結果造成很大的影響;但如果引數足夠小,資料偏移得多一點也不會對結果造成什麼影響,一種流行的說法是『抗擾動能力強』。
Relevant Link:
https://www.jianshu.com/p/1aafbdf9faa6 https://hit-scir.gitbooks.io/neural-networks-and-deep-learning-zh_cn/content/chap3/c3s5ss2.html https://www.zhihu.com/question/32246256 https://www.zhihu.com/question/20700829
2. 從模型搜尋空間限制角度看線性模型中的正則化(Regularization)
0x1:正則化簡介
在機器學習中,不管是常規的線性模式,還是像深度學習這樣的複合線性模型,幾乎都可以看到損失函式後面會新增一個額外項。
常用的額外項一般有兩種,一般英文稱作ℓ1-norm和ℓ2-norm,中文稱作L1正則化和L2正則化,或者L1範數和L2範數。
L1正則化和L2正則化可以看做是損失函式的懲罰項。
所謂『懲罰』是指對損失函式中的某些引數做一些限制。具體是什麼限制,我們接下來會詳細討論。
對於線性迴歸模型,使用L1正則化的模型叫做Lasso迴歸;使用L2正則化的模型叫做Ridge迴歸(嶺迴歸)。
0x2:Lasso迴歸 - 包含L1正則化的線性迴歸
線性迴歸模型中,Lasso迴歸的損失函式如下:
 ,後面一項 α||w||1 即為L1正則化項。||w||1 是指權值向量 w 中各個元素的絕對值之和。
,後面一項 α||w||1 即為L1正則化項。||w||1 是指權值向量 w 中各個元素的絕對值之和。
一般都會在正則化項之前新增一個係數,Python中用 α 表示,一些文章也用 λ 表示。這個係數需要使用者指定。
1. L1正則化的作用
L1正則化可以產生稀疏權值矩陣,即產生一個稀疏模型,可以用於特徵選擇。
稀疏矩陣指的是很多元素為0,只有少數元素是非零值的矩陣,即得到的線性迴歸模型的大部分系數都是0。
我們知道,通常機器學習中特徵數量很多(人工提取地或者因為自動編碼產生的),例如文字處理時,如果將一個片語(term)作為一個特徵,那麼特徵數量會達到上萬個(bigram)。
在預測或分類時,但是如果代入所有這些特徵,可能會最終得到一個非常複雜的模型,而絕大部分特徵權重是沒有貢獻的,即該模型更容易產生過擬合(回想前面過擬合原因的分析)。
加入L1正則化後,得到的模型是一個稀疏模型,表示只有少數特徵對這個模型有貢獻,因此提高了模型的泛化能力。
2. 以二維損失函式視覺化解釋 L1正則化是如何影響模型權重分配的
在專案中我們的特徵肯定都是超高維的,不利於解釋原理本質,我們以視覺化的二維函式作為討論物件,解釋 L1正則化的原理。
假設有如下帶L1正則化的損失函式:
![]()
其中 J0 是原始的損失函式,加號後面的一項是L1正則化項,α 是正則化係數。
注意到 L1 正則化是權值的絕對值之和,J 是帶有絕對值符號的函式,因此 J 是不完全可微的。機器學習的任務就是要通過最優化方法(例如梯度下降)求出損失函式的最小值。
當我們在原始損失函式 J0 後新增 L1 正則化項時,相當於對 J0 做了一個約束。
令 ![]() ,則 J = J0 + L,此時我們的任務變成在 L 約束下求出 J0 取最小值的解。
,則 J = J0 + L,此時我們的任務變成在 L 約束下求出 J0 取最小值的解。
在二維的情況,即只有兩個權值 w1 和 w2,此時 L = a * ( ||w1| + |w2| )。L 函式在二維座標系上是一個菱形,讀者朋友可以自己推導下。
對於梯度下降法,求解 J0 的過程可以畫出等值線,同時 L1 正則化的函式 L 也可以在 w1,w2 的二維平面上畫出來。如下圖:

圖中等值線是 J0 的等值線,黑色方形是某個指定懲罰係數α(例如1)時,L 函式的圖形。
在圖中,當 J0 等值線與 L 圖形首次相交的地方就是最優解。
上圖中 J0 與 L在 L 的一個頂點處相交,這個頂點就是最優解。注意到這個頂點中,w1 = 0,w2 = w。
在懲罰係數 α 不同時,這個菱形會不斷擴大和縮小,可以直觀想象,因為 L 函式有很多『突出的角』(二維情況下四個,多維情況下更多),J0 與這些角接觸的機率會遠大於與 L 其它部位接觸的機率( 隨著α縮小,L 的尖角總是最先碰到 J0 ),而在這些角上,會有很多權值等於0,這就是為什麼 L1正則化可以產生稀疏模型,進而可以用於特徵選擇。
另一方面,而正則化前面的係數 α,可以控制 L 圖形的大小。
α 越小,L 的圖形越大(上圖中的黑色方框);
α 越大,L 的圖形就越小,可以小到黑色方框只超出原點範圍一點點;
通過擴大 α 的大小,使得 w 可以取到很小的值。
綜上可以看到,L1正則化能夠做到兩件事:
1. 使得權重向量 w 儘量稀疏,即被選中的特徵儘量少。且 ; 2. 即使被選中,也有能力盡量使得 w 儘量小;
3. L1正則化的懲罰因子引數怎麼選擇
α越大,越容易使得權值向量 w 取得稀疏情況,同時 權值向量 w 值也越小。
0x3:Ridge迴歸 - 包含L2正則化的線性迴歸
線性迴歸模型中,Ridge迴歸的損失函式如下:
 ,式中加號後面一項 α||w||2 即為L2正則化項。||w||2 是指權值向量 w 中各個元素的平方和然後再求平方根。
,式中加號後面一項 α||w||2 即為L2正則化項。||w||2 是指權值向量 w 中各個元素的平方和然後再求平方根。
一般都會在正則化項之前新增一個係數,Python中用 α 表示,一些文章也用 λ 表示。這個係數需要使用者指定。
1. L2正則化的作用
L2正則化可以防止模型過擬合(overfitting)。但是這不是L2正則化的專利,L1正則化也能一定程度上防止模型過擬合。
2. 以二維損失函式視覺化解釋 L2正則化是如何使模型權重分配趨向於小值
假設有如下帶L2正則化的損失函式:
![]()
分析的過程和L1正則化是一樣的,我們省略,同樣可以畫出他們在二維平面上的圖形,如下:

二維平面下L2正則化的函式圖形是個圓,與方形相比,被磨去了稜角。因此 J0 與 L 相交時使得 w1 或 w2 等於零的機率小了許多,這就是為什麼L2正則化不具有稀疏性的原因。
但是L2正則化對 w1 和 w2 的整體壓制效果還是一樣的,我們從數學公式上分析下,L2正則化對權值引數壓制的原理。
以線性迴歸中的梯度下降法為例。假設要求的引數為 θ,hθ(x) 是我們的假設函式,那麼線性迴歸的代價函式如下:

那麼在梯度下降法中,最終用於迭代計算引數 θ 的迭代式為(省略求導過程的推導): 
其中 α 是learning rate。在原始代價函式之後新增L2正則化,則迭代公式會變成下面的樣子:

其中 λ 就是正則化引數。從上式可以看到:
與未新增L2正則化的迭代公式相比,每一次迭代,θj 都要先乘以一個小於 1 的因子,從而使得 θj 不斷減小,因此總得來看,θ是不斷減小的; 而且 λ 越大,每次減少的程度也越大;
和 L1正則化相比,而且因為均方根的放大作用,L2對 w 的限制力要更強,因此 L2正則化更適合壓制權值w,使其儘量取小值。
3. L2正則化的懲罰因子引數怎麼選擇
λ越大,L2懲罰力度就越大,引數被小值化壓制的程度也越大。
0x4:L1、L2正則化各自適合的場景
1. ridge regression(L2) 並不具有產生稀疏解的能力,也就是說引數並不會真出現很多零。假設我們的預測結果與兩個特徵相關,L2正則傾向於綜合兩者的影響,給影響大的特徵賦予高的權重; 2. 而 L1 正則傾向於選擇影響較大的引數,而捨棄掉影響較小的那個;
實際應用中 L2正則表現往往會優於 L1正則,但 L1正則會大大降低我們的計算量
0x5:不同懲罰引數下,正則化效果視覺化
為了更好的直觀體會L1和L2正則化對權重的制約過程,我們在mnist上訓練一個經典的CNN分類器,提取出所有的權重,求出其分佈來看看。所有權重初始化為均值0,方差0.5的正態分佈。
# -*- coding: utf-8 -*- from __future__ import print_function import keras from keras.datasets import mnist from keras.models import Sequential, Model from keras.layers import Dense, Dropout, Flatten, Input from keras.layers import Conv2D, MaxPooling2D from keras import backend as K from keras import initializers import numpy as np import matplotlib.pyplot as plt from keras import regularizers (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) x_test = x_test.reshape(x_test.shape[0], 28, 28, 1) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255.0 x_test /= 255.0 y_train = keras.utils.to_categorical(y_train, 10) y_test = keras.utils.to_categorical(y_test, 10) def my_reg(weight_matrix): #return 0 # 無正則化 return 1.0 * K.sum(K.abs(weight_matrix)) # L1正則化 #return 2.0 * K.sum(K.abs(weight_matrix)) # L1正則化 #return 1.0 * K.sum(K.pow(K.abs(weight_matrix), 2)) # L2正則化 #return 2.0 * K.sum(K.pow(K.abs(weight_matrix), 2)) # L2正則化 #return 1.0 * K.sum(K.abs(weight_matrix)) + 1.0 * K.sum(K.pow(K.abs(weight_matrix), 2)) # L1-L2混合正則化 #return K.sum(K.pow(K.abs(weight_matrix), 3)) # L3正則化 # 所有權重初始化為均值0,方差0.5的正態分佈 init = initializers.random_normal(mean=0, stddev=0.25, seed=42) input = Input(shape=(28, 28, 1)) conv1 = Conv2D(32, kernel_size=(3, 3), activation='relu', kernel_initializer=init, kernel_regularizer=my_reg)(input) conv2 = Conv2D(64, (3, 3), activation='relu', kernel_initializer=init, kernel_regularizer=my_reg)(conv1) pool1 = MaxPooling2D(pool_size=(2, 2))(conv2) conv3 = Conv2D(128, (3, 3), activation='relu', kernel_initializer=init, kernel_regularizer=my_reg)(pool1) pool2 = MaxPooling2D(pool_size=(2, 2))(conv3) flat = Flatten()(pool2) dense1 = Dense(128, activation='relu', kernel_initializer=init, kernel_regularizer=my_reg)(flat) output = Dense(10, activation='softmax', kernel_initializer=init, kernel_regularizer=my_reg)(dense1) model = Model(inputs=input, outputs=output) model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy']) model.summary() for i in range(40): model.fit(x_train, y_train, batch_size=128, epochs=1, verbose=0, validation_data=(x_test, y_test)) # 每次只訓練一輪 score = model.evaluate(x_test, y_test, verbose=0) weights = model.get_weights() all_weights = np.zeros([0, ]) for w in weights: w_flatten = np.reshape(w, [-1]) all_weights = np.concatenate([all_weights, w_flatten], axis=0) plt.hist(all_weights, bins=100, color="b", normed=True, range=[-1, 1]) print("epoch=" + str(i) + " loss=%.2f ,acc=%.3f" % (score[0], score[1])) plt.title("epoch=" + str(i) + " loss=%.2f ,acc=%.3f" % (score[0], score[1])) plt.savefig("mnist_model_weights_hist_%d.png" % (i)) plt.clf()
讀者在執行的時候可以逐項把my_reg裡的註釋去除,逐個體驗不同的正則化懲罰因子,對權重引數的制約作用。程式碼執行可能較慢,讀者們不要著急。
筆者在學習這部分的時候,視覺化帶來了很多的有趣的思考,相信你也可以體會到數學公式的微小改變,給optimization帶來的巨大變化;以及機器學習專案中,提取出來的特徵是如何被模型選擇,我們如何去幹預這個特徵選擇過程等等。
程式碼執行完畢後會在本地目錄產生很多.png圖片,讀者朋友可以用這個來生成gif動圖,非常直觀。
1. 無正則化

2. L1正則化 - 懲罰因子 = 1e-4

很明顯,L1懲罰因子讓 w 朝著係數矩陣的方向優化。
3. L1正則化 - 懲罰因子 = 1e-3
可以看到,在這個實驗中,1e-3 對權值的壓制作用就已經非常明顯了。在第一輪訓練後,權值向量的分佈就大幅度集中在均值附近,即很多 w 被置為0。

筆者思考:在這個專案中,因為權值向量的維數不高,所以 L1懲罰因子的影響非常顯著,在具體的專案中,你的特徵feature可能高達上萬或者上百萬。相應的,L1懲罰因子可以選擇稍微大一些,提高制約能力。
4. L2正則化 - 懲罰因子 = 1e-4

5. L2正則化 - 懲罰因子 = 1e-3

可以看到,懲罰因子越大,制約能力越強。
6. L1-L2混合正則化

7. L3正則化
1. 過擬合(overfitting)簡介
0x1:假設空間(hypothesis space)
給定學習演算法 A,它所考慮的所有可能概念的集合稱為假設空間,用符號 H 表示。對於假設空間中的任一概念,我們用符號 h 表示,由於並不能確定它是否真是目標概念,因此稱為“假設”(hypothesis)
1 擬合 python sco bsp orm AS score 未知數 spa git:https://github.com/linyi0604/MachineLearning
正則化: 提高模型在未知數據上的泛化能力 避免參數過擬合正則化常用的方法: 在目 Dropout正則化是最簡單的神經網路正則化方法。其原理非常簡單粗暴:任意丟棄神經網路層中的輸入,該層可以是資料樣本中的輸入變數或來自先前層的啟用。它能夠模擬具有大量不同網路結構的神經網路,並且反過來使網路中的節點更具有魯棒性。
閱讀完本文,你就學會了在Keras框架中,如何將深度學習神經網路D 1.過擬合問題
對於過擬合問題,通常原因是模型選擇太過複雜,也有可能是訓練資料太少。對於模型太複雜的情況,我們一般有如下考慮:一是通過分析刪除部分特徵(比如重複多餘的特徵或者對輸出值貢獻不太大的特徵),但是這樣有可能會損失一部分資訊。所以,我們可以通過正則化的方法來降低引數值,從而避免過擬合問題。對於過擬合問
過擬合:
過擬合(over-fitting)是所建的機器學習模型或者是深度學習模型在訓練樣本中表現得過於優越,導致在驗證資料集以及測試資料集中表現不佳的現象。就像上圖中右邊的情況。 過擬合的模型太過具體從而缺少泛化能力,過度的擬合了訓練集中的資料。出現的原因是模型將其中的不重要的變
我們在先前博文中已經簡要介紹了決策樹的思想和幾個經典演算法來構造決策樹:《決策樹演算法簡介及其MATLAB實現程式碼》。今天我們要針對決策樹繼續深入探討一些的問題,目錄如下:
目錄
一、表示屬性測試條件的方法
二、選擇最佳劃分的度量
三、處理決策樹歸納中的過分擬合現象
一、表 Underfitting is easy to check as long as you know what the cost function measures. The definition of the cost function in linear regression is half
the me
過擬合:我們通過訓練集訓練的模型對於訓練樣本的的擬合程度十分高,就會放大一些不必要的特徵,再對測試集進行測試時,就容易造成測試精度很低,也就是模型的泛化能力很弱,這就是過擬合。
那麼我們如何解決過擬合
什麼是過擬合?
為了得到一致假設而使假設變得過度嚴格稱為過擬合。過擬合的模型一般對訓練資料表現很好,而對測試資料表現很差。
如何解決過擬合問題?
early stopping:可以設定一個迭代截斷的閾值,到了這個閾值迭代終止;也可以設定兩次迭代之間的accuracy提高 for 區分 技術分享 運用 圖片 environ top col tar 過擬合
過擬合(overfitting,過度學習,過度擬合):
過度準確地擬合了歷史數據(精確的區分了所有的訓練數據),而對新數據適應性較差,預測時會有很大誤差。
過擬合是機器學習中常見的問題
先驗概率
概念:本質上就是古典概型,是利用當前狀態對求解狀態的一種概率估計,可以理解為“由 因求果”中“因”出現的概率。
條件:
(1)實驗所有的可能結果是有限的;
(2) 每一種出現
本文為原創文章轉載必須註明本文出處以及附上 本文地址超連結以及 博主部落格地址:http://blog.csdn.NET/qq_20259459 和 作者郵箱(
[email prot class 中一 技術分享 cnblogs 訓練數據 是否 多個 期望 部分 怎樣評價我們的學習算法得到的假設以及如何防止過擬合和欠擬合的問題。
當我們確定學習算法的參數時,我們考慮的是選擇參數來使訓練誤差最小化。有人認為,得到一個很小的訓練誤差一定是一件好事。但其實,僅
過擬合:指模型在訓練集上表現很好,但是在測試集上表現很差。
造成過擬合的原因:
1. 訓練集過小,模型無法cover所有可能的情況(泛化能力差);
2. 模型過於複雜,過於貼合訓練資料;
解決方法:
1. 增加訓練資料(增加訓練資料多樣性,提升模型泛化能力),e.g. CNN資料
1、定義
在training data上的error漸漸減小,但是在驗證集上的error卻反而漸漸增大(過擬合是泛化的反面)
2、解決辦法
(1)正則化(Regularization)
L2正則化:目標函式中增加所有權重w引數的平方之和, 逼迫所有w儘可能趨向零但不為零.
什麼是過擬合
過擬合:我們通過訓練集訓練的模型對於訓練樣本的的擬合程度十分高,就會放大一些不必要的特徵,再對測試集進行測試時,就容易造成測試精度很低,也就是模型的泛化能力很弱,這就是過擬合。
怎麼解決過擬合
對應導致過擬合發生的幾種條件,我們可以想辦法來避免過擬合。
過於自負
在細說之前, 我們先用實際生活中的一個例子來比喻一下過擬合現象. 說白了, 就是機器學習模型於自信. 已經到了自負的階段了. 那自負的壞處, 大家也知道, 就是在自己的小圈子裡表現非凡, 不過在現實的大圈子裡卻往往處處碰壁. 所以在這個簡介裡, 我們把自負和過擬合畫上等號
上個系列【數字影象處理】還將繼續更新,最近由於用到機器學習演算法,因此將之前學習到的機器學習知識進行總結,打算接下來陸續出一個【機器學習系列】,供查閱使用!本篇便從機器學習基礎概念說起!
一、解釋監督學習,非監督學習,半監督學習的區別
監督學習、非監督學
說明:文章中的所有圖片均屬於Stanford機器學習課程
(一)過擬合問題(The Problem of Overfitting)
不管是在線性迴歸還是在邏輯迴歸中,我們都會遇到過擬合的問題。先從例子來看看什麼是過擬合。
i.線性迴歸中的過擬合
下面左圖即為欠擬合,中圖為合適的擬合,右圖為過擬合。
過擬合:在模型引數擬合過程中,由於訓練資料包含抽樣誤差,訓練時複雜的模型將抽樣誤差也考慮在內(抽樣誤差也進行了擬合)。模型泛化能力弱,在訓練集上效果好,在測試集上效果差。
導致過擬合的原因(包括但不限於如下幾個 
相關推薦
淺議過擬合現象(overfitting)以及正則化技術原理
機器學習之路: python線性回歸 過擬合 L1與L2正則化
【Keras】減少過擬合的祕訣——Dropout正則化
過擬合解決方案之正則化
機器學習中的過擬合和欠擬合現象,以及通過正則化的方式解決。
決策數演算法進階:屬性測試條件、最佳劃分度量、過擬合現象的處理
機器學習中:過擬合(overfitting)和欠擬合(underfitting)
14過擬合(Overfitting)
如何解決過擬合(overfitting)問題?
AI - TensorFlow - 過擬合(Overfitting)
概率統計與機器學習:極大後驗概率以及正則化項
深度學習 14. 深度學習調參,CNN引數調參,各個引數理解和說明以及調整的要領。underfitting和overfitting的理解,過擬合的解釋。
斯坦福大學公開課機器學習: advice for applying machine learning - evaluatin a phpothesis(怎麽評估學習算法得到的假設以及如何防止過擬合或欠擬合)
overfitting過擬合
overfitting過擬合問題
Overfitting-過擬合
什麼是過擬合 (Overfitting) 、解決方法、程式碼示例(tensorflow實現)
機器學習概念篇:監督學習、過擬合,正則化,泛化能力等概念以及防止過擬合方法總結
機器學習筆記05:正則化(Regularization)、過擬合(Overfitting)
過擬合overfitting