什麼是過擬合 (Overfitting) 、解決方法、程式碼示例(tensorflow實現)
過於自負

在細說之前, 我們先用實際生活中的一個例子來比喻一下過擬合現象. 說白了, 就是機器學習模型於自信. 已經到了自負的階段了. 那自負的壞處, 大家也知道, 就是在自己的小圈子裡表現非凡, 不過在現實的大圈子裡卻往往處處碰壁. 所以在這個簡介裡, 我們把自負和過擬合畫上等號
迴歸分類的過擬合

機器學習模型的自負又表現在哪些方面呢. 這裡是一些資料. 如果要你畫一條線來描述這些資料, 大多數人都會這麼畫. 對, 這條線也是我們希望機器也能學出來的一條用來總結這些資料的線. 這時藍線與資料的總誤差可能是10. 可是有時候, 機器過於糾結這誤差值, 他想把誤差減到更小, 來完成他對這一批資料的學習使命. 所以, 他學到的可能會變成這樣 . 它幾乎經過了每一個數據點, 這樣, 誤差值會更小

那麼在分類問題當中. 過擬合的分割線可能是這樣, 小二, 再上一打資料 . 我們明顯看出, 有兩個黃色的資料並沒有被很好的分隔開來. 這也是過擬合在作怪.好了, 既然我們時不時會遇到過擬合問題, 那解決的方法有那些呢.
解決方法一

方法一: 增加資料量, 大部分過擬合產生的原因是因為資料量太少了. 如果我們有成千上萬的資料, 紅線也會慢慢被拉直, 變得沒那麼扭曲 .
解決方法二:

建立 dropout 層
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelBinarizer
#define placeholeder for inputs to network keep_prob = tf.placeholder(tf.float32) xs = tf.placeholder(tf.float32,[None,64]) #8*8 ys = tf.placeholder(tf.float32,[None,10])
這裡的keep_prob是保留概率,即我們要保留的結果所佔比例,它作為一個placeholder,在run時傳入, 當keep_prob=1的時候,相當於100%保留,也就是dropout沒有起作用。 下面我們分析一下程式結構,首先準備資料,
#load data
digits = load_digits()
X = digits.data
y = digits.target
y = LabelBinarizer().fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3)
其中X_train是訓練資料, X_test是測試資料。 然後新增隱含層和輸出層
# add output layer
l1 = add_layer(xs, 64, 50, 'l1', activation_function=tf.nn.tanh)
prediction = add_layer(l1, 50, 10, 'l2', activation_function=tf.nn.softmax)
loss函式(即最優化目標函式)選用交叉熵函式。交叉熵用來衡量預測值和真實值的相似程度,如****果完全相同,交叉熵就等於零。
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
train方法(最優化演算法)採用梯度下降法。
訓練
最後開始train,總共訓練500次。
sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 0.5})
#sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 1})
視覺化結果
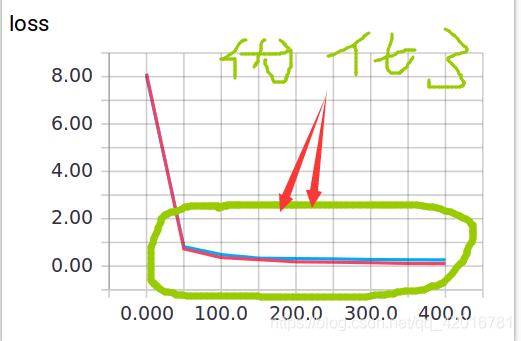
訓練中keep_prob=1時,就可以暴露出overfitting問題。keep_prob=0.5時,dropout就發揮了作用。 我們可以兩種引數分別執行程式,對比一下結果。
當keep_prob=1時,模型對訓練資料的適應性優於測試資料,存在overfitting,輸出如下: 紅線是 train 的誤差, 藍線是 test 的誤差.
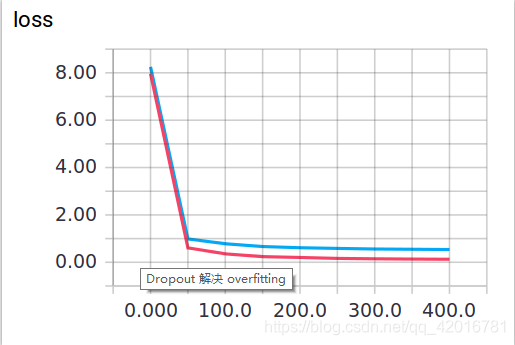
當keep_prob=0.5時效果好了很多,輸出如下: