TensorFlow HOWTO 2.2 支援向量迴歸(軟間隔)
阿新 • • 發佈:2018-11-29
將上一節的假設改一改,模型就可以用於迴歸問題。
操作步驟
匯入所需的包。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import sklearn.datasets as ds
import sklearn.model_selection as ms
匯入資料,並進行預處理。我們使用鳶尾花資料集中的後兩個品種,根據萼片長度預測花瓣長度。
iris = ds.load_iris()
x_ = iris.data[50:, 0]
y_ = iris.data[50 定義所需超引數。
| 變數 | 含義 |
|---|---|
n_input |
樣本特徵數 |
n_epoch |
迭代數 |
lr |
學習率 |
eps |
支援邊界到決策邊界的函式距離 |
lam |
L2 正則化函式 |
n_input = 1
n_epoch = 2000
lr = 0.05
eps = 0.5
lam = 0.05
搭建模型。
| 變數 | 含義 |
|---|---|
x |
輸入 |
y |
真實標籤 |
w |
權重 |
b |
偏置 |
z |
輸出,也就是標籤預測值 |
x = tf.placeholder(tf.float64, [None, n_input])
y = tf.placeholder(tf.float64, [None, 1])
w = tf.Variable(np.random.rand(n_input, 1))
b = tf.Variable(np.random.rand(1, 1))
z = x @ w + b
定義損失、優化操作、和 R 方度量指標。
我們使用 Hinge 損失和 L2 的組合。和上一節相比,Hinge 需要改一改:
在迴歸問題中,模型約束相反,是樣本落在支援邊界內部,也就是 。我們仍然將其加到損失中,於是,對於滿足約束的點,損失為零。對於不滿足約束的點,損失為 。這樣讓樣本儘可能到支援邊界之內。
L2 損失仍然用於最小化支援邊界的幾何距離,也就是 。
| 變數 | 含義 |
|---|---|
hinge_loss |
Hinge 損失 |
l2_loss |
L2 損失 |
loss |
總損失 |
op |
優化操作 |
y_mean |
y的均值 |
r_sqr |
R 方值 |
hinge_loss = tf.reduce_mean(tf.maximum(tf.abs(z - y) - eps, 0))
l2_loss = lam * tf.reduce_sum(w ** 2)
loss = hinge_loss + l2_loss
op = tf.train.AdamOptimizer(lr).minimize(loss)
y_mean = tf.reduce_mean(y)
r_sqr = 1 - tf.reduce_sum((y - z) ** 2) / tf.reduce_sum((y - y_mean) ** 2)
使用訓練集訓練模型。
losses = []
r_sqrs = []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for e in range(n_epoch):
_, loss_ = sess.run([op, loss], feed_dict={x: x_train, y: y_train})
losses.append(loss_)
使用測試集計算 R 方。
r_sqr_ = sess.run(r_sqr, feed_dict={x: x_test, y: y_test})
r_sqrs.append(r_sqr_)
每一百步列印損失和度量值。
if e % 100 == 0:
print(f'epoch: {e}, loss: {loss_}, r_sqr: {r_sqr_}')
得到擬合直線:
x_min = x_.min() - 1
x_max = x_.max() + 1
x_rng = np.arange(x_min, x_max, 0.1)
x_rng = np.expand_dims(x_rng, 1)
y_rng = sess.run(z, feed_dict={x: x_rng})
輸出:
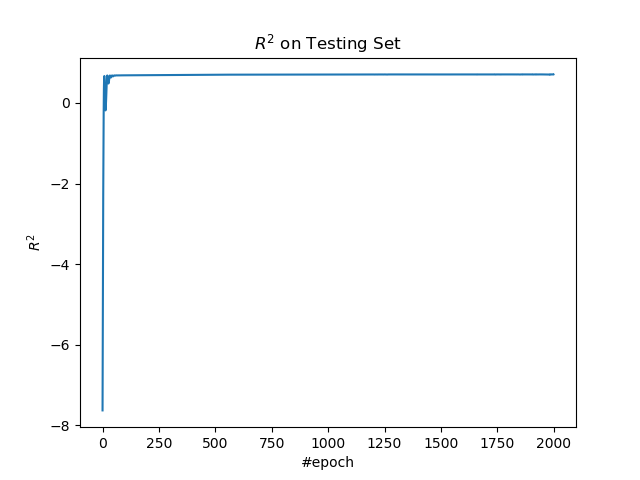
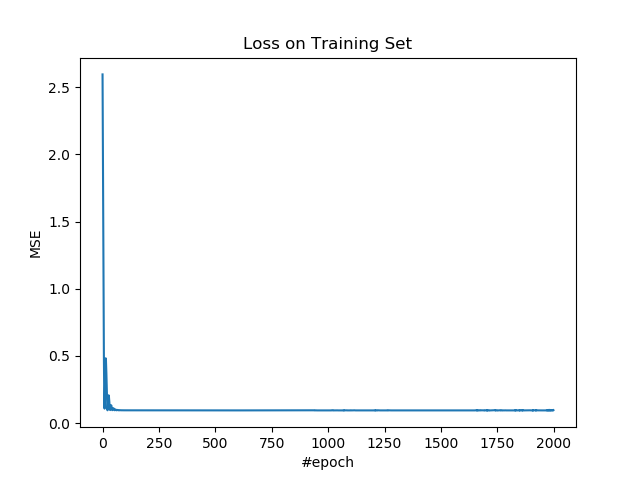
epoch: 0, loss: 2.595811345519854, r_sqr: -7.63455623000992
epoch: 100, loss: 0.09490037816660063, r_sqr: 0.6870450579269822
epoch: 200, loss: 0.0945981212813202, r_sqr: 0.6919725995177556
epoch: 300, loss: 0.0943360378730447, r_sqr: 0.6972100379246203
epoch: 400, loss: 0.0942670608490176, r_sqr: 0.7011480891041979
epoch: 500, loss: 0.09420861968646403, r_sqr: 0.7023977527848786
epoch: 600, loss: 0.09420462812797847, r_sqr: 0.7033420189633286
epoch: 700, loss: 0.09420331500841268, r_sqr: 0.7040990336920706
epoch: 800, loss: 0.09420013554417629, r_sqr: 0.7049244708036546
epoch: 900, loss: 0.09419894883980164, r_sqr: 0.7058068427331468
epoch: 1000, loss: 0.09419596028573823, r_sqr: 0.7063798499792275
epoch: 1100, loss: 0.09439172532153575, r_sqr: 0.7082249152615245
epoch: 1200, loss: 0.0942860145903332, r_sqr: 0.7082847730551416
epoch: 1300, loss: 0.09419431250773326, r_sqr: 0.7085666625849087
epoch: 1400, loss: 0.09419430203474248, r_sqr: 0.7086043351158677
epoch: 1500, loss: 0.09419435727421285, r_sqr: 0.7085638764264852
epoch: 1600, loss: 0.09419436716550869, r_sqr: 0.7085578243219421
epoch: 1700, loss: 0.09422521775113285, r_sqr: 0.7085955861355715
epoch: 1800, loss: 0.09419408061180848, r_sqr: 0.709039512302889
epoch: 1900, loss: 0.09425026677323756, r_sqr: 0.7088910272655065
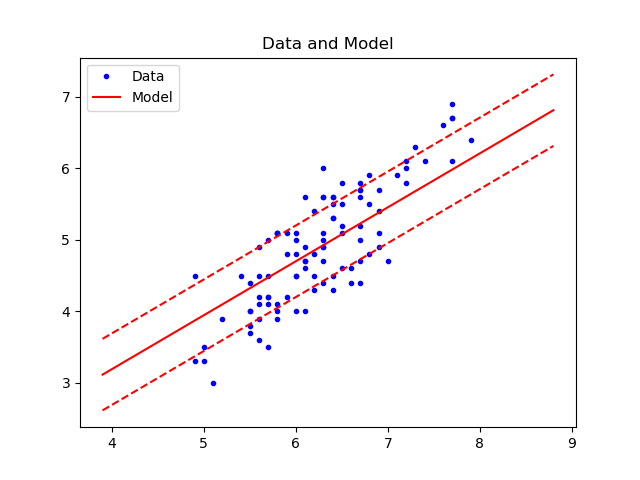
繪製整個資料集的預測結果以及支援邊界。
plt.figure()
plt.plot(x_, y_, 'b.', label='Data')
plt.plot(x_rng.ravel(), y_rng.ravel(), 'r', label='Model')
plt.plot(x_rng.ravel(), (y_rng + eps).ravel(), 'r--')
plt.plot(x_rng.ravel(), (y_rng - eps).ravel(), 'r--')
plt.title('Data and Model')
plt.legend()
plt.show()
繪製訓練集上的損失。
plt.figure()
plt.plot(losses)
plt.title('Loss on Training Set')
plt.xlabel('#epoch')
plt.ylabel('MSE')
plt.show()
繪製測試集上的 R 方。
plt.figure()
plt.plot(r_sqrs)
plt.title('$R^2$ on Testing Set')
plt.xlabel('#epoch')
plt.ylabel('$R^2$')
plt.show()