TensorFlow HOWTO 2.3 支援向量分類(高斯核)
阿新 • • 發佈:2018-12-03
遇到非線性可分的資料集時,我們需要使用核方法,但為了使用核方法,我們需要返回到拉格朗日對偶的推導過程,不能簡單地使用 Hinge 損失。
操作步驟
匯入所需的包。
import tensorflow as tf
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import sklearn.datasets as ds
import sklearn.model_selection as ms
為了展示非線性可分的資料集,我們需要把它創建出來。依舊把標籤變成 1 和 -1,原標籤為 0 的樣本標籤為 1。
circles = ds.make_circles(n_samples=500, factor=0.5, noise=0.1)
x_ = circles[0]
y_ = (circles[1] == 0).astype(int)
y_[y_ == 0] = -1
y_ = np.expand_dims(y_ , 1)
x_train_, x_test_, y_train_, y_test_ = \
ms.train_test_split(x_, y_, train_size=0.7, test_size=0.3
定義超引數。
| 變數 | 含義 |
|---|---|
n_batch |
樣本批量大小 |
n_input |
樣本特徵數 |
n_epoch |
迭代數 |
lr |
學習率 |
gamma |
高斯核係數 |
n_batch = len(x_train_)
n_input = 2
n_epoch = 2000
lr = 0.05
gamma = 10
搭建模型。首先定義佔位符(資料)和變數(模型引數)。
由於模型引數a和樣本x是對應的,不像之前的w, b
| 變數 | 含義 |
|---|---|
x_train |
輸入,訓練集的特徵 |
y_train |
訓練集的真實標籤 |
a |
模型引數 |
x_train = tf.placeholder(tf.float64, [n_batch, n_input])
y_train = tf.placeholder(tf.float64, [n_batch, 1])
a = tf.Variable(np.random.rand(n_batch, 1))
定義高斯核。由於高斯核函式是個相對獨立,又反覆呼叫的東西,把它寫成函式抽象出來。
它的定義是這樣的:
,x和y是兩個向量。
但在這裡,我們要為兩個矩陣的每一行計算這個函式,用了一些小技巧。(待補充)
def rbf_kernel(x, y, gamma):
x_3d_i = tf.expand_dims(x, 1)
y_3d_j = tf.expand_dims(y, 0)
kernel = tf.reduce_sum((x_3d_i - y_3d_j) ** 2, 2)
kernel = tf.exp(- gamma * kernel)
return kernel
kernel = rbf_kernel(x_train, x_train, gamma)
定義損失。我們使用的損失為:
這個公式的來歷請見擴充套件閱讀的第一個連結。
| 變數 | 含義 |
|---|---|
loss |
損失 |
op |
優化操作 |
a_cross = a * tf.transpose(a)
y_cross = y_train * tf.transpose(y_train)
loss = tf.reduce_sum(a_cross * y_cross * kernel)
loss -= tf.reduce_sum(a)
loss /= n_batch
op = tf.train.AdamOptimizer(lr).minimize(loss)
定義度量指標。我們在測試集上計算它,為此,我們在計算圖中定義測試集。
| 變數 | 含義 |
|---|---|
x_test |
測試集的特徵 |
y_test |
測試集的真實標籤 |
y_hat |
標籤的預測值 |
x_test = tf.placeholder(tf.float64, [None, n_input])
y_test = tf.placeholder(tf.float64, [None, 1])
kernel_pred = rbf_kernel(x_train, x_test, gamma)
y_hat = tf.transpose(kernel_pred) @ (y_train * a)
y_hat = tf.sign(y_hat - tf.reduce_mean(y_hat))
acc = tf.reduce_mean(tf.to_double(tf.equal(y_hat, y_test)))
使用訓練集訓練模型。
losses = []
accs = []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for e in range(n_epoch):
_, loss_ = sess.run([op, loss], feed_dict={x_train: x_train_, y_train: y_train_})
losses.append(loss_)
使用訓練集和測試集計算準確率。
acc_ = sess.run(acc, feed_dict={x_train: x_train_, y_train: y_train_, x_test: x_test_, y_test: y_test_})
accs.append(acc_)
每一百步列印損失和度量值。
if e % 100 == 0:
print(f'epoch: {e}, loss: {loss_}, acc: {acc_}')
得到決策邊界:
x_plt = x_[:, 0]
y_plt = x_[:, 1]
c_plt = y_.ravel()
x_min = x_plt.min() - 1
x_max = x_plt.max() + 1
y_min = y_plt.min() - 1
y_max = y_plt.max() + 1
x_rng = np.arange(x_min, x_max, 0.05)
y_rng = np.arange(y_min, y_max, 0.05)
x_rng, y_rng = np.meshgrid(x_rng, y_rng)
model_input = np.asarray([x_rng.ravel(), y_rng.ravel()]).T
model_output = sess.run(y_hat, feed_dict={x_train: x_train_, y_train: y_train_, x_test: model_input}).astype(int)
c_rng = model_output.reshape(x_rng.shape)
輸出:
epoch: 0, loss: 3.71520431509184, acc: 0.9666666666666667
epoch: 100, loss: -0.0727806862453766, acc: 0.9733333333333334
epoch: 200, loss: -0.1344057865226747, acc: 0.9666666666666667
epoch: 300, loss: -0.19954100171678735, acc: 0.9666666666666667
epoch: 400, loss: -0.26744944765154044, acc: 0.9666666666666667
epoch: 500, loss: -0.3376130527328746, acc: 0.9666666666666667
epoch: 600, loss: -0.40968204759135396, acc: 0.9666666666666667
epoch: 700, loss: -0.48337264821214987, acc: 0.9666666666666667
epoch: 800, loss: -0.5584322960888252, acc: 0.9666666666666667
epoch: 900, loss: -0.634641530183908, acc: 0.9666666666666667
epoch: 1000, loss: -0.7118203254530981, acc: 0.9666666666666667
epoch: 1100, loss: -0.7898283716352298, acc: 0.9666666666666667
epoch: 1200, loss: -0.8685602440121085, acc: 0.9666666666666667
epoch: 1300, loss: -0.9479390005125, acc: 0.9666666666666667
epoch: 1400, loss: -1.02791046598349, acc: 0.9666666666666667
epoch: 1500, loss: -1.1084388930145652, acc: 0.9666666666666667
epoch: 1600, loss: -1.1895038125649773, acc: 0.9666666666666667
epoch: 1700, loss: -1.2710975807209766, acc: 0.9666666666666667
epoch: 1800, loss: -1.3532232661574393, acc: 0.9666666666666667
epoch: 1900, loss: -1.4358926633795104, acc: 0.9733333333333334
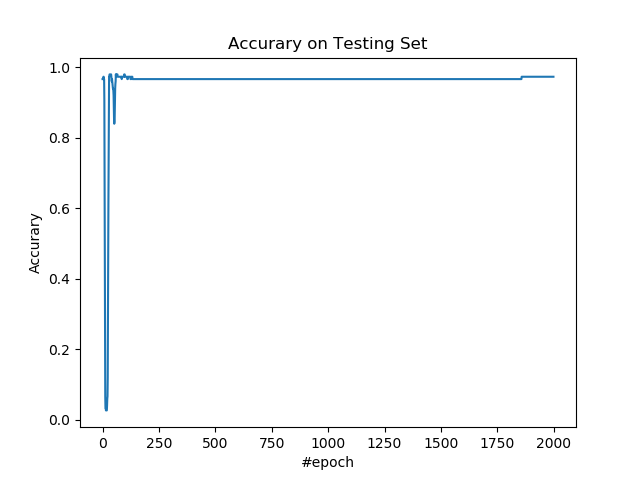
繪製整個資料集以及決策邊界。
plt.figure()
cmap = mpl.colors.ListedColormap(['r', 'b'])
plt.scatter(x_plt, y_plt, c=c_plt, cmap=cmap)
plt.contourf(x_rng, y_rng, c_rng, alpha=0.2, linewidth=5, cmap=cmap)
plt.title('Data and Model')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
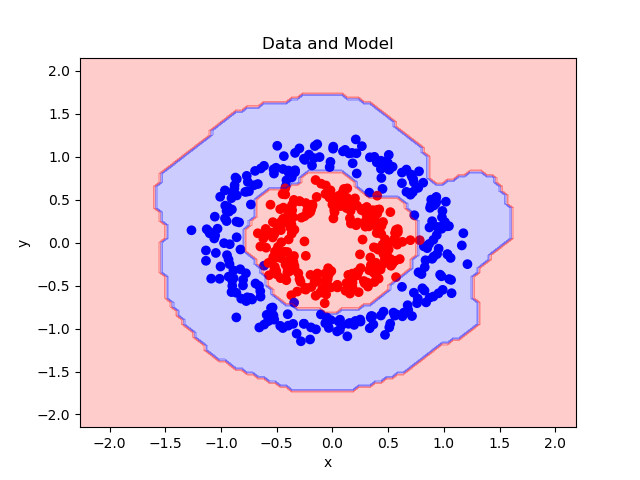
繪製訓練集上的損失。
plt.figure()
plt.plot(losses)
plt.title('Loss on Training Set')
plt.xlabel('#epoch')
plt.ylabel('SVM Loss')
plt.show()
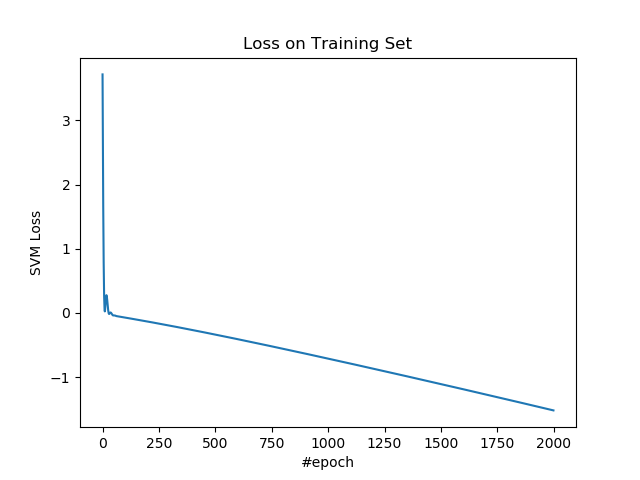
繪製測試集上的準確率。
plt.figure()
plt.plot(accs)
plt.title('Accurary on Testing Set')
plt.xlabel('#epoch')
plt.ylabel('Accurary')
plt.show()