
NEURAL MACHINE TRANSLATION
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
ABSTRACT
神經機器翻譯是最近提出的機器翻譯方法。與傳統的統計機器翻譯不同,神經機器翻譯旨在構建單個神經網路,通過聯合調整以最大化翻譯效能。最近提出的用於神經機器翻譯的模型通常屬於一系列編碼 - 解碼器,並將源句編碼成固定長度的向量,解碼器從該向量生成翻譯。在本文中,我們推測固定長度向量的使用是在改善這種基本編碼器 - 解碼器架構效能過程中的瓶頸,並且建議通過允許模型自動搜尋與預測目標詞相關的源句子部分來擴充套件這一點,無需明確地將這些部分形成為 hard segment 。通過這種新的翻譯方法,我們在英法翻譯任務中實現了與現有最先進的基於短語的系統相當的翻譯效能。此外,定性分析表明,模型發現的對齊與我們的直覺很吻合。
1 INTRODUCTION
神經機器翻譯是一種新興的機器翻譯方法,最近由 Kalchbrenner 和 Blunsom(2013),Sutskever等人提出。傳統的基於短語的翻譯系統由許多可以分開調整的小的子元件組成,與其不同的是,神經機器翻譯試圖建立和訓練一個單獨的大型神經網路來讀取句子並輸出正確的翻譯。
大多數所提出的神經機器翻譯模型屬於編碼器 - 解碼器系列,具有針對每種語言的編碼器和解碼器,或涉及應用於其輸出然後進行比較的每個句子的語言專用編碼器。編碼器神經網路將源句子讀取並編碼為固定長度的向量。然後,解碼器從編碼向量輸出翻譯。對於每個語言對來說,整個編碼器 - 解碼器系統由編碼器和解碼器組成,它們被聯合訓練,以最大化給定源句子的正確翻譯的概率。
這種編碼器 - 解碼器方法的潛在問題是神經網路需要能夠將源句子的所有必要資訊壓縮成固定長度的向量。這可能使神經網路難以處理長句,特別是那些比訓練語料庫中的句子長的句子。Cho et al. 表明,隨著輸入句子的長度增加,基本編碼器 - 解碼器的效能急劇惡化。
為了解決這個問題,我們擴充套件了編碼器 - 解碼器模型,該模型學習了共同對齊和翻譯。每次在翻譯中生成單詞時,所提出的模型搜尋源語句中的一組位置,該位置中最相關的資訊集中在一起。然後,模型基於與這些源位置和所有先前生成的與目標詞相關聯的上下文向量來預測目標詞。
這種方法與基本的編解碼器最重要的區別在於它不試圖將整個輸入句子編碼為單個固定長度的向量。相反,它將輸入語句編碼為一系列向量,並在解碼翻譯時自適應地選擇這些向量的子集。這使得神經翻譯模型不必將源語句的所有資訊(不論其長度如何)壓縮到固定長度的向量中。我們表明,該模型能更好地處理長句。
在本文中,我們證明所提出的聯合學習對齊和翻譯的方法與基本的編解碼器方法相比顯著提高了翻譯效能。用較長的句子進行改進更明顯,但可以用任意長度的句子來觀察。在英法翻譯任務時,所提出的方法在單個模型下實現了與傳統的基於短語的系統相當或接近的翻譯效能。此外,定性分析表明,所提出的模型在源句和相應的目標句之間找到了語言上可信的對齊。
3 LEARNING TO ALIGN AND TRANSLATE
在本節中,我們提出了一種新穎的神經機器翻譯架構。新架構由作為編碼器的雙向RNN和模擬在解碼翻譯期間搜尋源句的解碼器組成。
3.1
應當注意,與現有的編碼器 - 解碼器方法不同,這裡的每個目標詞的概率 是以不同的上下文 為條件的。
上下文向量 取決於編碼器對映到輸入語句的 annotation 序列( )。每個 annotation hi 都包含關於整個輸入序列的資訊,並且關注輸入單詞xi周圍的詞。我們將在下一節詳細解釋如何計算 annotation。 也即 與 的某種組合。
然後,上下文向量ci是這些hi的加權和:

的權重
為:
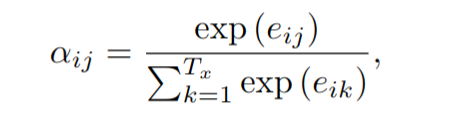
其中,
為:
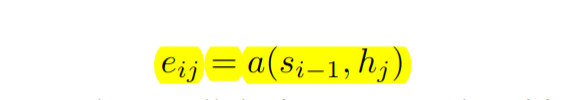
可以看做一個對齊模型,用來衡量第 j 個位置的輸入詞與第i個輸出詞的匹配程度。這個程度基於 Decoder 的隱藏狀態
和輸入句子的第 j 個 annotation
計算得到。
直觀來想就是,如果你想要決定要花多少注意力在t的啟用值上,它似乎很大程度上取決於你上一個時間步的的隱藏狀態的啟用值。你還沒有當前狀態的啟用值,但是看看你生成上一個翻譯的RNN的隱藏狀態,然後對於每一個位置,每一個詞都看向他們的特徵值,這看起來很自然,即 應該取決於這兩個量。但是我們不知道具體函式是什麼,所以我們可以做的事情就是訓練一個很小的神經網路,去學習這個函式到底是什麼。
因此我們引數化對齊模型a為前饋神經網路,該網路與所繫統的所有其他元件共同訓練。請注意,不同於傳統的對齊模型,將源語言端每個詞明確對齊到目標語言端一個或多個詞( hard segment),而是計算得到的是一種軟對齊(soft alignment),可以融入整個 NMT 框架,通過反向傳播演算法求得梯度以更新引數。
我們可以理解將所有 annotations 的加權和作為計算預期 annotation 的方法。讓 是目標詞 與源詞 對齊或翻譯的概率。然後,第 i 個上下文向量 是對所有具有 概率的 annotations 的預期 annotations 。
概率 或其相關的 反映了 相對於先前隱藏狀態 在決定下一狀態 和產生 時的重要性。直觀地講,這實現瞭解碼器中的 attention 機制。解碼器決定要關注的源句的哪些部分。通過讓解碼器具有 attention 機制,我們減輕了編碼器必須將源句中的所有資訊編碼為固定長度的向量的負擔。利用這種新方法,資訊可以在整個 annotation 序列中傳播,這可以由解碼器相應有選擇性地檢索。
#3.2
通常的RNN,按照從第一個符號x1到最後一個符號 的順序讀取輸入序列x。但是,在提出的方案中,我們希望每個單詞的 annotation 不僅要概述前面的單詞,還要概述下面的單詞。因此,我們計劃使用一個雙向RNN,最近在語音識別中得到了成功的應用。
雙向 RNN 由前向和後向 RNN 組成。前向RNN 以順序 的順序讀取輸入序列,並且計算前向隱藏狀態序列 。反向RNN 以順序 的順序讀取輸入序列,並且計算反向隱藏狀態序列 。
對於每一個詞 我們獲取其 annotation 是通過串聯其前向隱藏狀態