
Paper Summary: Neural Machine Translation
一、 Sequence to Sequence Learning with Neural Networks - [email protected]
1、提出背景:
(1)雖然DNN可以解決現實生活中的很多問題,但是在解決機器翻譯過程中,主要的問題是其輸入和輸出的長度一致。
也許你覺得可以通過padding等方式使得輸入和輸出長度變得不一樣,比如輸入是10,固定輸出也是10,如果輸出是5,則將剩下的5個輸出使用null填充等,但是這樣不太合適,而且對於很多翻譯任務而言,並不能預先知道翻譯結果的最大長度。
(2)另外,DNN不能充分考慮序列之間的前後關係,其翻譯僅僅基於當前詞。
2、提出的方法:
使用Encoder-Decoder架構,如下圖所示:
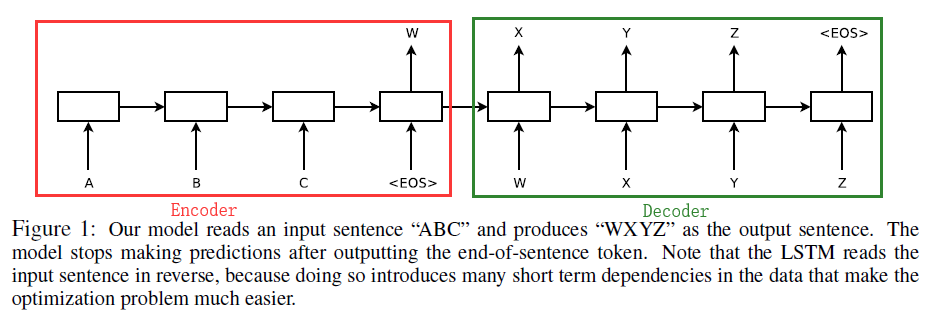
左側是Encoder部分,其主要功能是將輸入的序列處理成一個固定長度的語義特徵向量W,W中含有輸入序列的資訊,Encoder Cell可以是RNN/GRU/LSTM。右側是Decoder部分,主要任務是將語義特徵W作為輸入,首先生成target的第一個層詞X,基於X和W再生成Y…,Decoder Cell可以是RNN/GRU/LSTM。(Encoder Cell和Decoder Cell的選取可以在RNN/RGU/LSTM中隨便組合),文章中使用的是LSTM。
3、實驗任務
English-French的翻譯任務。
4、提到的小技巧
輸入序列逆序的情況下,翻譯效果剛好,可能是如下原因(作者好像也只是猜測):
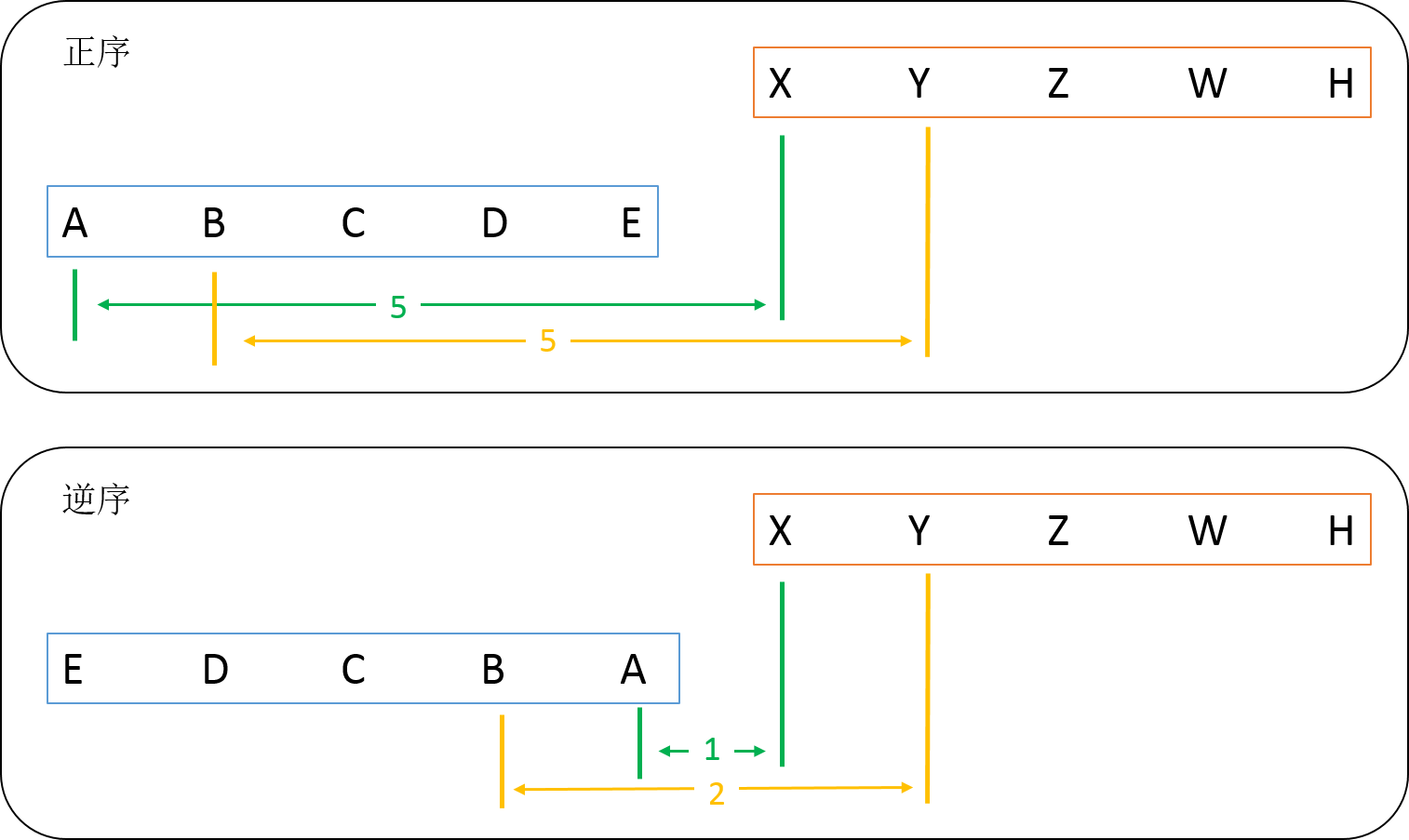
如圖,在將“ABCDE”翻譯成“XYZWH”任務中(假設翻譯結果與次序一對一),分析如下:
對於正序的情況,A翻譯成X,中間間隔距離為5;B翻譯成Y也一樣…。而在逆序的情況,A翻譯成X,中間間隔距離為1;B翻譯成Y,中間間隔距離為2,…也就是說再逆序的情況下,引入了很多短期依賴,這使得在翻譯開始的詞比較準確,這些準確的詞會對後面的翻譯帶來正面影響,使得結果比正序輸入更好。
二、 Neural Machine Translation by Jointly Learning to Align and Translate -
1、提出背景:
在普通的encoder-decoder模型中,將輸入的整個句子encode成一個語義編碼向量c,基於c再進行decoder的過程。但是語義編碼向量c是效能的一個瓶頸,因為固定長度向量所包含的資訊總歸是有限的,而且若句子非常長,其儲存的資訊也非常受限。
2、提出的方法:
本文提出了一個Soft-Search的方法,也就是現在大家說的“Attention”機制,這種機制能夠在翻譯
的時候自動搜尋哪些輸入words對當前的輸出比較有用,並給這些有用的詞更多的權重,使得其對輸出的作用更大。
其架構如下:
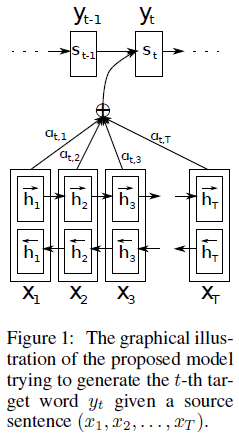
其和傳統的Encoder-Decoder模型的不同在於:
(1)在傳統的Encoder-Deocder模型中,直接接Encoder過程得到的語義編碼向量c輸入到每一個翻譯的序列中,也就是說,在每個時間點輸入的語義向量都是同一個c。
(2)而在含有Attetion機制的Encoder-Decoder中,語義編碼向量會針對每一個時間的翻譯任務有所側重。就好像人在翻譯的過程中,不是完全對一個句子進行翻譯,而是幾個單詞幾個單詞一起翻譯,在翻譯某個單詞的時候,他附近的幾個詞語對翻譯結果的影響是最大的。
簡單來說,在Decoder的過程中,傳統模型每個Cell的輸入都是同一個
,而在Attention機制的模型中,每個Cell的輸入都是不同的
。
的計算過程如下:
其中,
簡單來說,
是對所有Encoder Cell隱單元向量
的加權求和,這樣就把對於當前翻譯
位置的任務重要的單詞賦予更大的權重,使其發揮更大的作用。
那麼我們如何得到權重係數呢?
文中求
又使用了一個簡單的前饋神經網路,將其和整個Encoder-Decoder系統一起訓練,從而得到
。
3、實驗任務
English-to-French翻譯任務。
注:
關於更多Seq2Seq和Attention機制的直觀感受,請參見seq2seq model和Attention-based seq2seq Model(動圖展示)
三、Towards Neural Phrase-based Machine Translation
1、提出背景:
(1)先前的NMT任務,Decoder部分大多數基於注意力機制。
(2)基於Phrase/Segment的翻譯比基於Word的翻譯效果好。
(3)SWAN使用Attention機制翻譯,但是其基於的假設是原序列和目標翻譯序列是單調的對應關係,這個假設性太強。
2、提出的方法:
(1)摒棄原序列和目標序列的對應關係,提出基於(soft) local reordering的思想。
(2)句子結構是自動訓練的,不需要預定義。
(3)文章中的方法基於另一篇論文的模型SWAN(論文為:Sequence modeling via segmentations.),SWAN的模型如下:
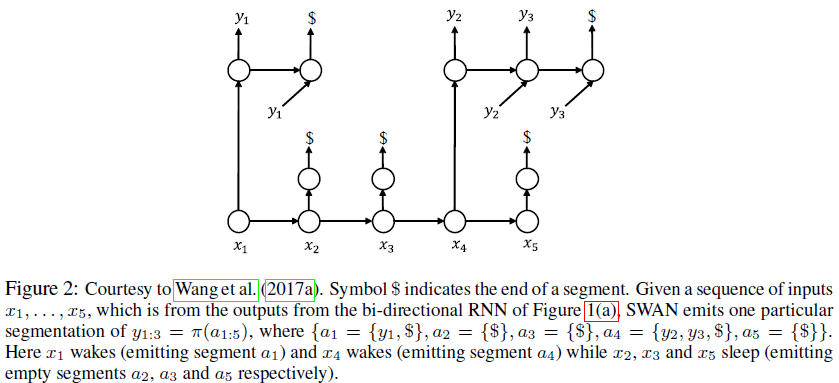
(4)本文提出的模型如下:
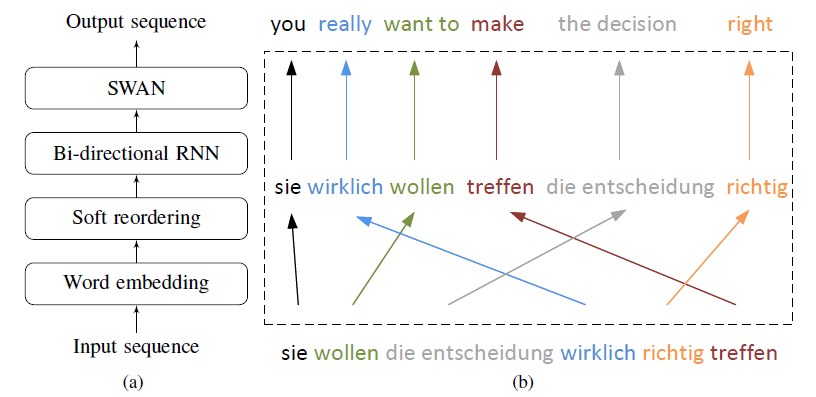
首先,對輸入序列Embedding操作,其次基於Embedding的結果重新變換句子順序,並將其輸入到雙向RNN中,最後,將輸出的結果喂入SWAN中得到翻譯結果。
(5)Reorder function.
Soft reordering第t個時間點的輸出
表示如下:
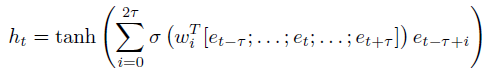
其中,
表示sigmoid function,
表示local reordering window size,
是向量
的拼接,給
加上一個sigmoid就當於給
加了一個門,最後
是所有的window中的
之和,
表示embedding的結果。如下圖所示:
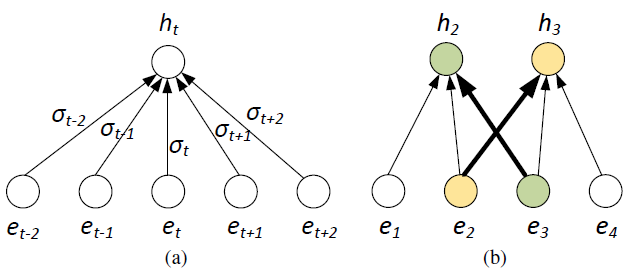
左圖展示的便是上面公式的含義。比如,在右圖中,如果發現
在第二個視窗中比重較大,
在第一個視窗中比重較大,則將
和
交換順序。
(6)reorder function中的