
度學習Trick——用權重約束減輕深層網路過擬合|附(Keras)實現程式碼
摘要: 深度學習小技巧,約束權重以降低模型過擬合的可能,附keras實現程式碼。
在深度學習中,批量歸一化(batch normalization)以及對損失函式加一些正則項這兩類方法,一般可以提升模型的效能。這兩類方法基本上都屬於權重約束,用於減少深度學習神經網路模型對訓練資料的過擬合,並改善模型對新資料的效能。
目前,存在多種型別的權重約束方法,例如最大化或單位向量歸一化,有些方法也必須需要配置超引數。
在本教程中,使用Keras API,用於向深度學習神經網路模型新增權重約束以減少過擬合。
完成本教程後,您將瞭解:
- 如何使用Keras API建立向量範數約束;
- 如何使用Keras API為MLP、CNN和RNN層新增權重約束;
- 如何通過向現有模型新增權重約束來減少過度擬合;
下面,讓我們開始吧。

本教程分為三個部分:
- Keras中的權重約束;
- 圖層上的權重約束;
- 權重約束案例研究;
Keras中權重約束
Keras API支援權重約束,且約束可以按每層指定。
使用約束通常涉及在圖層上為輸入權重設定kernel_constraint引數,偏差權重設定為bias_constraint
一組不同的向量規範在
keras.constraints模組可以用作約束:
- 最大範數(max_norm):強制權重等於或低於給定限制;
- 非負規範(non_neg):強制權重為正數;
- 單位範數(unit_norm):強制權重為1.0;
- Min-Max範數(min_max_norm):強制權重在一個範圍之間;
例如,可以匯入和例項化約束:
# import norm from keras.constraints import max_norm # instantiate norm norm = max_norm(3.0)
圖層上的權重約束
權重規範可用於Keras的大多數層,下面介紹一些常見的例子:
MLP權重約束
下面的示例是在全連線層上設定最大範數權重約束:
# example of max norm on a dense layer
from keras.layers import Dense
from keras.constraints import max_norm
...
model.add(Dense(32, kernel_constraint=max_norm(3), bias_constraint==max_norm(3)))
...CNN權重約束
下面的示例是在卷積層上設定最大範數權重約束:
# example of max norm on a cnn layer
from keras.layers import Conv2D
from keras.constraints import max_norm
...
model.add(Conv2D(32, (3,3), kernel_constraint=max_norm(3), bias_constraint==max_norm(3)))
...RNN權重約束
與其他圖層型別不同,遞迴神經網路允許我們對輸入權重和偏差以及迴圈輸入權重設定權重約束。通過圖層的recurrent_constraint引數設定遞迴權重的約束。
下面的示例是在LSTM圖層上設定最大範數權重約束:
# example of max norm on an lstm layer
from keras.layers import LSTM
from keras.constraints import max_norm
...
model.add(LSTM(32, kernel_constraint=max_norm(3), recurrent_constraint=max_norm(3), bias_constraint==max_norm(3)))
...基於以上的基本知識,下面進行例項實踐。
權重約束案例研究
在本節中,將演示如何使用權重約束來減少MLP對簡單二元分類問題的過擬合問題。
此示例只是提供了一個模板,讀者可以舉一反三,將權重約束應用於自己的神經網路以進行分類和迴歸問題。
二分類問題
使用標準二進位制分類問題來定義兩個半圓觀察,每個類一個半圓。其中,每個觀測值都有兩個輸入變數,它們具有相同的比例,輸出值分別為0或1,該資料集也被稱為“ 月亮”資料集,這是由於繪製時,每個類中出現組成的形狀類似於月亮。
可以使用make_moons()函式生成觀察結果,設定引數為新增噪聲、隨機關閉,以便每次執行程式碼時生成相同的樣本。
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1) 可以在圖表上繪製兩個變數x和y座標,並將資料點所屬的類別的顏色作為觀察的顏色。
下面列出生成資料集並繪製資料集的完整示例:
# generate two moons dataset
from sklearn.datasets import make_moons
from matplotlib import pyplot
from pandas import DataFrame
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
# scatter plot, dots colored by class value
df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y))
colors = {0:'red', 1:'blue'}
fig, ax = pyplot.subplots()
grouped = df.groupby('label')
for key, group in grouped:
group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key])
pyplot.show()執行該示例會建立一個散點圖,可以從圖中看到,對應類別顯示的影象類似於半圓形或月亮形狀。
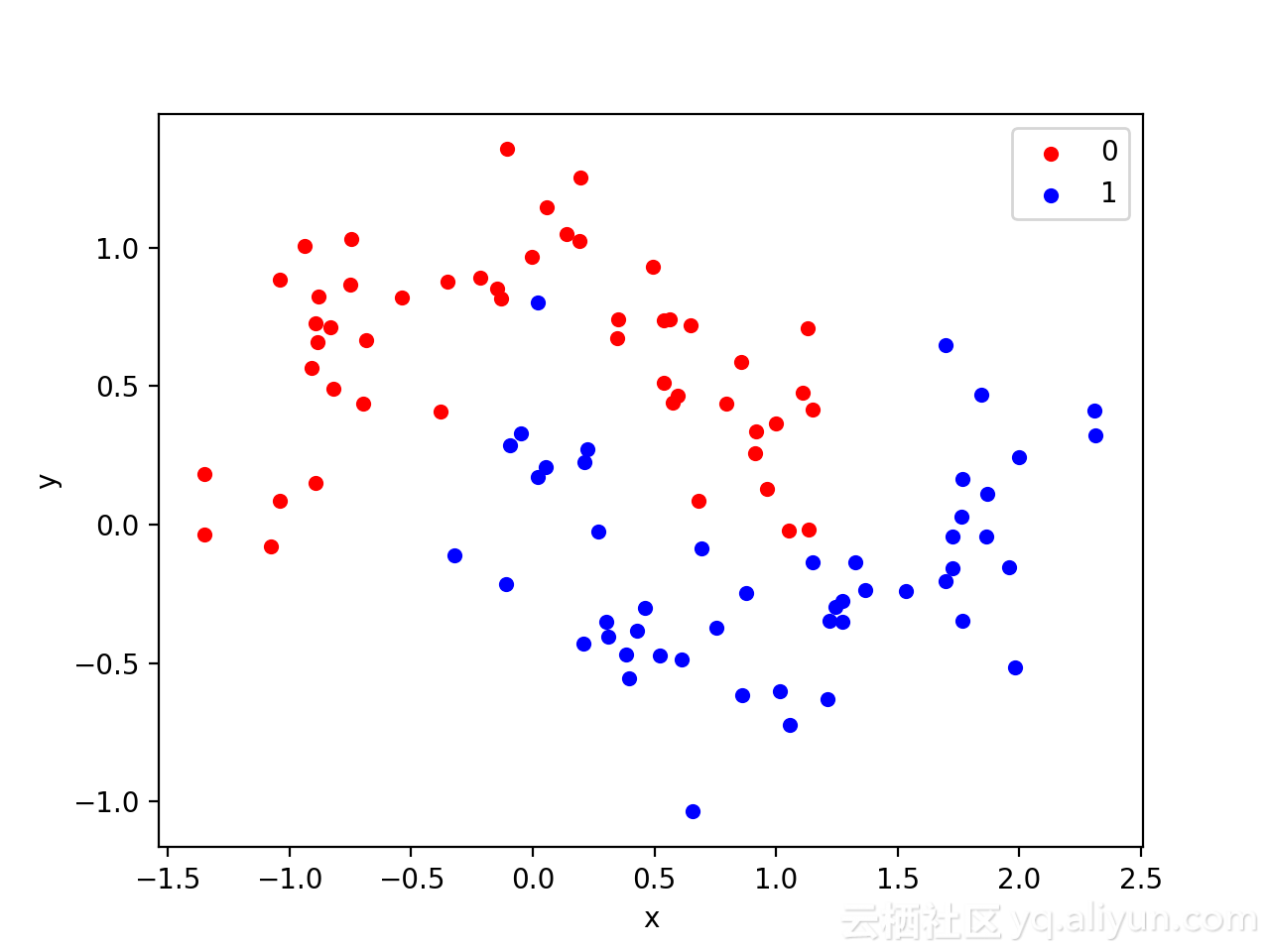
上圖的資料集表明它是一個很好的測試問題,因為不能用直線劃分,需要非線性方法,比如神經網路來解決。
只生成了100個樣本,這對於神經網路而言較小,也提供了過擬合訓練資料集的概率,並且在測試資料集上具有更高的誤差。因此,也是應用正則化的一個好例子。此外,樣本具有噪聲,使模型有機會學習不一致的樣本的各個方面。
多層感知器過擬合
在機器學習力,MLP模型可以解決這類二進位制分類問題。
MLP模型只具有一個隱藏層,但具有比解決該問題所需的節點更多的節點,從而提供過擬合的可能。
在定義模型之前,需要將資料集拆分為訓練集和測試集,按照3:7的比例將資料集劃分為訓練集和測試集。
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
# split into train and test
n_train = 30
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:] 接下來,定義模型。隱藏層的節點數設定為500、啟用函式為RELU,但在輸出層中使用Sigmoid啟用函式以預測輸出類別為0或1。
該模型使用二元交叉熵損失函式進行優化,這類啟用函式適用於二元分類問題和Adam版本梯度下降方法。
# define model
model = Sequential()
model.add(Dense(500, input_dim=2, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])然後,設定迭代次數為4,000次,預設批量訓練樣本數量為32。
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0)這裡將測試資料集作為驗證資料集驗證演算法的效能:
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))最後,繪製出模型每個時期在訓練和測試集上效能。如果模型確實對訓練資料集過擬合了,對應繪製的曲線將會看到,模型在訓練集上的準確度繼續增加,而測試集上的效能是先上升,之後下降。
# plot history
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show()將以上過程組合在一起,列出完整示例:
# mlp overfit on the moons dataset
from sklearn.datasets import make_moons
from keras.layers import Dense
from keras.models import Sequential
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
# split into train and test
n_train = 30
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# define model
model = Sequential()
model.add(Dense(500, input_dim=2, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot history
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show() 執行該示例,給出模型在訓練資料集和測試資料集上的效能。
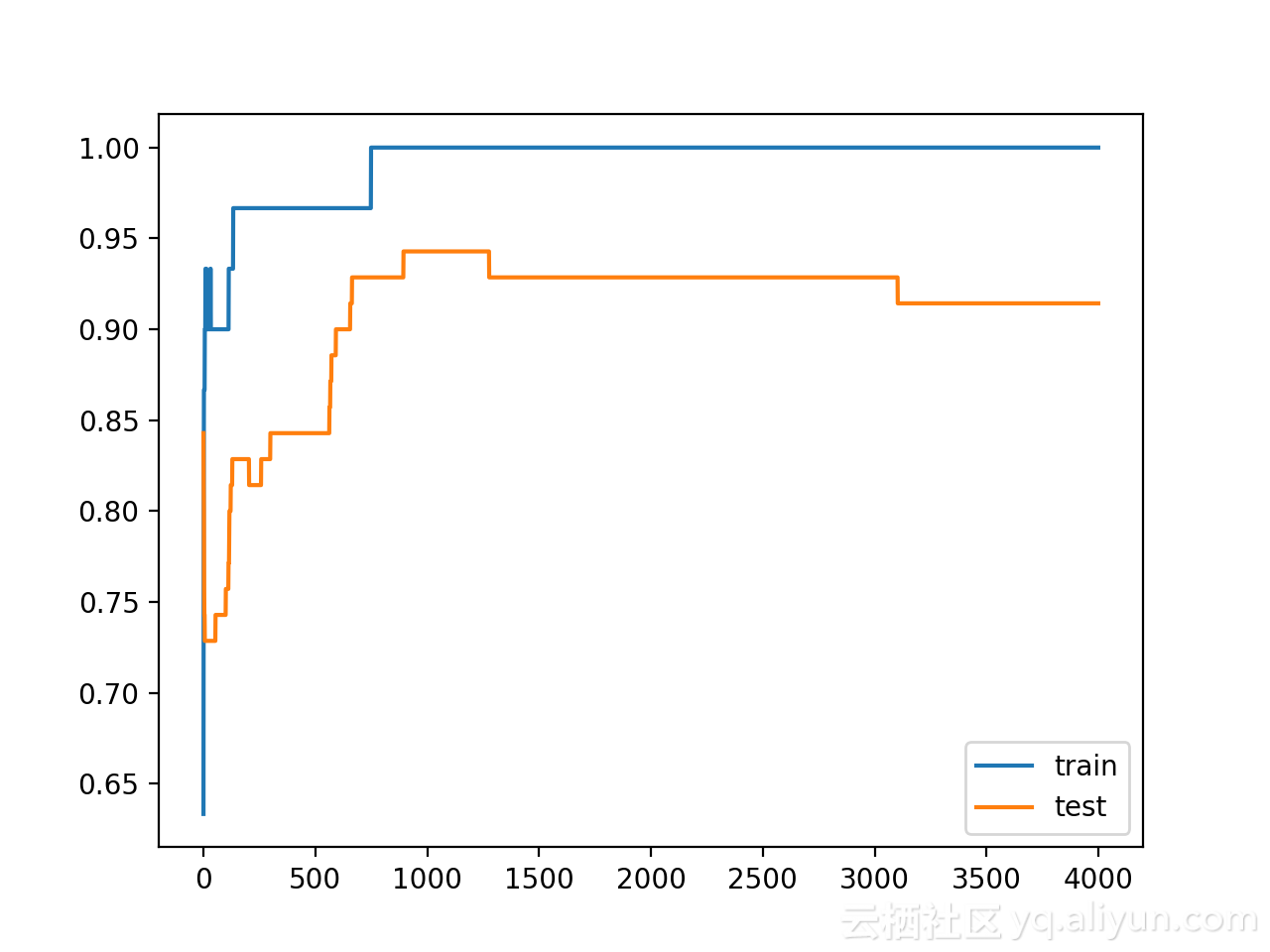
可以看到模型在訓練資料集上的效能優於測試資料集,這是發生過擬合的標誌。鑑於神經網路和訓練演算法的隨機性,每次模擬的具體結果可能會有所不同。因為模型是過擬合的,所以通常不會期望在相同資料集上能夠重複執行得到相同的精度。
Train: 1.000, Test: 0.914建立一個圖,顯示訓練和測試集上模型精度的線圖。從圖中可以看到模型過擬合時的預期形狀,其中測試精度達到一個臨界點後再次開始減小。
具有權重約束的多層感知器過擬合
為了和上面做對比,現在對MLP使用權重約束。目前,有一些不同的權重約束方法可供選擇。本文選用一個簡單且好用的約束——簡單地標準化權重,使得其範數等於1.0,此約束具有強制所有傳入權重變小的效果。
在Keras中可以通過使用unit_norm來實現,並且將此約束新增到第一個隱藏層,如下所示:
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=unit_norm())) 此外,也可以通過使用min_max_norm並將min和maximum設定為1.0 來實現相同的結果,例如:
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=min_max_norm(min_value=1.0, max_value=1.0)))但是無法通過最大範數約束獲得相同的結果,因為它允許規範等於或低於指定的限制; 例如:
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=max_norm(1.0)))下面列出具有單位規範約束的完整程式碼:
# mlp overfit on the moons dataset with a unit norm constraint
from sklearn.datasets import make_moons
from keras.layers import Dense
from keras.models import Sequential
from keras.constraints import unit_norm
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
# split into train and test
n_train = 30
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# define model
model = Sequential()
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=unit_norm()))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot history
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show() 執行該示例,給出模型在訓練資料集和測試資料集上的效能。
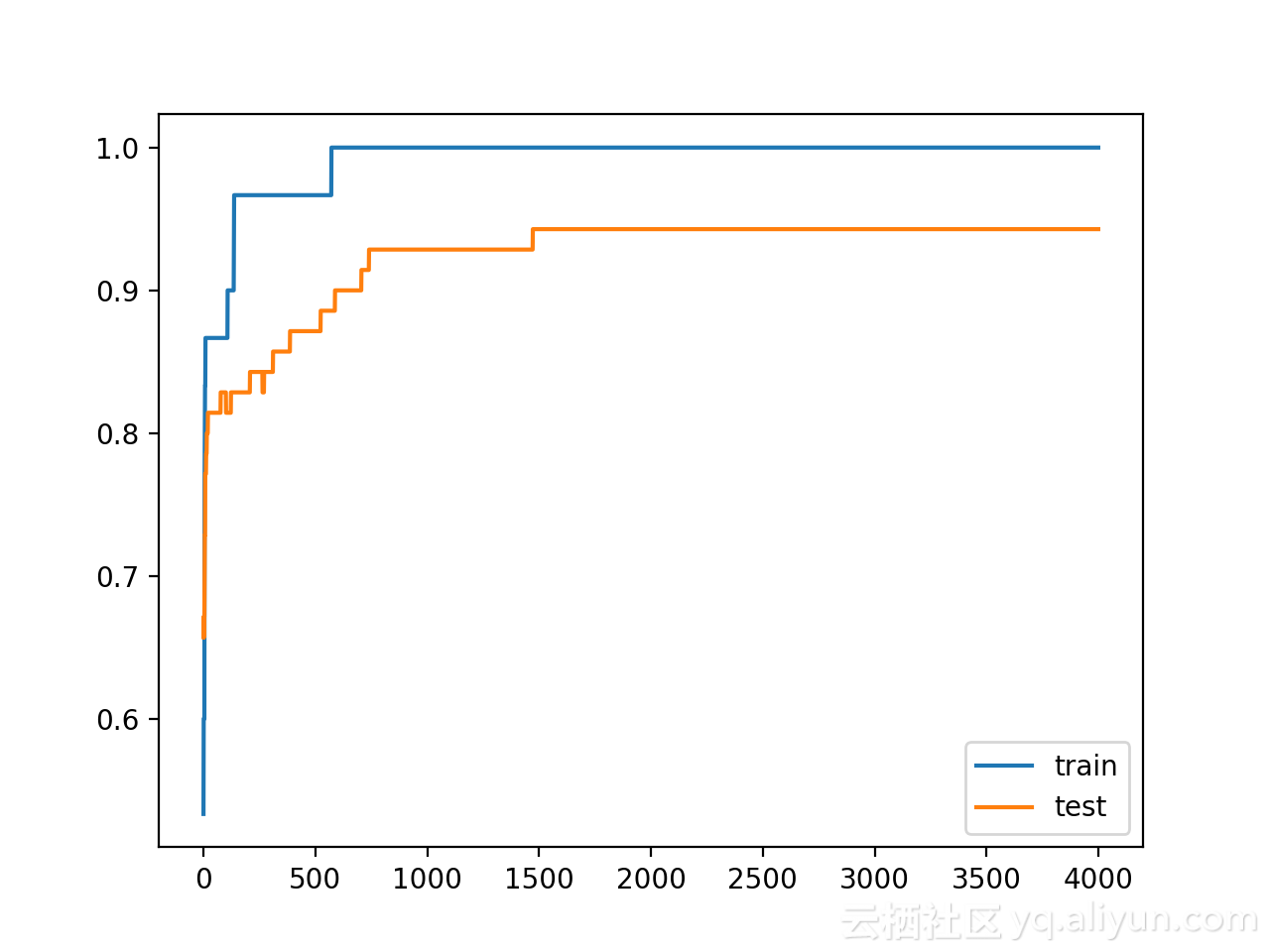
從下圖可以看到,對權重進行嚴格約束確實提高了模型在驗證集上的效能,並且不會影響訓練集的效能。
Train: 1.000, Test: 0.943從訓練和測試精度曲線圖來看,模型已經在訓練資料集上不再過擬合了,且模型在訓練和測試資料集的精度保持在一個穩定的水平。
擴充套件
本節列出了一些讀者可能希望探索擴充套件的教程:
- 報告權重標準:更新示例以計算網路權重的大小,並證明使用約束後,確實使得幅度更小;
- 約束輸出層:更新示例以將約束新增到模型的輸出層並比較結果;
- 約束偏置:更新示例以向偏差權重新增約束並比較結果;
- 反覆評估:更新示例以多次擬合和評估模型,並報告模型效能的均值和標準差;
進一步閱讀
如果想進一步深入瞭解,下面提供一些有關該主題的其它資源: