
常見的無失真壓縮演算法
無失真壓縮演算法
LZ77 演算法
LZ77 演算法的關鍵是搜尋,即在已經處理過的符號序列(資料流)中,尋找與待編碼符號序列相同的模式,如果找到匹配的模式,就設法對這個模式進行索引,也就是生成一個指標,然後輸出該索引即可。LZ77 演算法巧妙地實現了這個處理。為了幫助讀者理解演算法原理,我們用圖 5-8 描述 LZ77 演算法的操作過程,其中涉及到演算法用到的幾個關鍵概念。
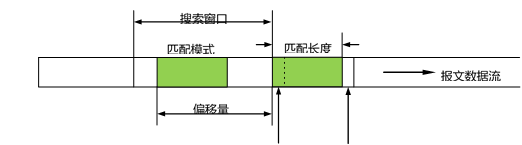
當前編碼位置,即匹配模式的首字元 下一個字元
5-8 描述 LZ77 演算法的操作過程
壓縮處理是從整個報文的第一個字元開始的。但是,為了使描述不失一般性,我們假設壓縮過程已經推進到了當前編碼位置。圖 5-8
第一個問題,圖 5-8 中的"下一個字元"(next_char)有什麼用?下一個字元是緊跟在從
當前編碼位置開始的匹配模式的後面的一個字元。實際上,在搜尋不到匹配模式的情況下,我們還是需要將壓縮過程往前推進,如果直接輸出 next char,就可以往前推進一個字元。否則的話,演算法就會原地踏步。由此可見,next_char 的設計起到了一個保證壓縮排程不會中途停止的作用。
第二問題是,隨著壓縮過程往前推進,已經處理過的資料會越來越長,這顯然會使後續的搜尋時間增加。不難想見,如果能夠限制搜尋範圍,自然可以避免這種增加。這就是圖 5-8 中搜索視窗的由來。從資料結構的角度看,搜尋視窗就是從當前編碼位置開始往回統計的字元個數(max_window_size
程式碼 5-1 給出了 LZ77 演算法的偽碼描述,其中的變數名稱採用了上面論述中類似的命名方法,如 off 表示偏移量,length 表示匹配長度,等等。
程式碼 5-1 描述 LZ77 演算法的偽碼
______________________________________________________________________________ Algorithm_LZ77( input:message output: compressed_message)
{ set current coding position pointer to the start of message; while ( TRUE) { search the max matched string in the slide window;
get the off and the length; if ( length ≠ 0){ add (off, length, next_char) to the end of compressed_message; move the current coding position pointer ahead length+1;
} else{ add (0, 0, next_char) to the end of compressed_message; move the current coding position pointer ahead 1;
}
If ( the current coding position pointer is the end of message) return ;
}
}
_______________________________________________________________________________
下面來看一個例子。設輸入報文是(AABCBBABCAABCE),搜尋視窗長度為 10。第一輪迴圈結束時的狀態如圖 5-9 所示。
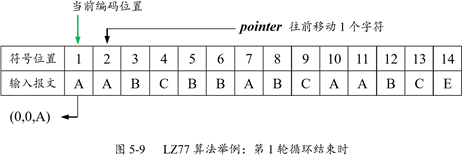
最初,當前編碼位置為 1,搜尋視窗為空。然後開始搜尋,即在搜尋視窗中查詢與 A 相同的字元,顯然找不到,因為視窗為空,故 off 和 length 均等於 0,按照演算法要求,輸出編碼為(0,0,A),指標 pointer 往前移動 1 個字元,指向位置 2,也就是下一輪迴圈的當前編碼位置。
第二輪迴圈的當前編碼位置是 2,且視窗含有字元 A。開始搜尋,能夠為 2 號位置的 A 找到匹配模式 A,且 off 等於 1,length 也等於 1,因此,輸出(1,1,B),並將 pointer 往前移動 2 個字元。第二輪迴圈結束時的狀態如圖 5-10 所示。

第三輪迴圈的結果如圖 5-11 所示。儘管第三輪迴圈開始的時候,搜尋視窗中已經包含了 AAB 三個字元,但仍不能為當前的 C 找到匹配模式,因此輸出(0,0,C)。

第四輪迴圈的時候,我們滿意地看到,視窗中包含的 AABC 正好與當前編碼位置開始的模式 AABC 匹配,所以,off 等於 4,length 也等於 4(這是巧合),因此輸出為(4,4,C)。注意,這個輸出的三元組中的 C 是位置 9 上的字元 C。迴圈結束時,pointer 往前移動 5 個字元,即指向第 10 個字元位置。第四輪迴圈結束時的狀態如圖 5-12 所示。

第五輪迴圈開始的時候,視窗中包含的字元達到了 9 個,即 AABCAABCC,它們均屬於搜尋視窗。當前編碼位置是上輪迴圈結束時 pointer 指向的位置 10。開始搜尋,我們再次看到 AABC 這個匹配模式,而且在視窗中存在兩個匹配的模式,左邊那個的 off 等於 9,右邊那個匹配模式的 off 為 5,length 為 4,因此,輸出結果是(5,4,E)或(9,4,E)。第五輪迴圈結束時的狀態如圖 5-13 所示。
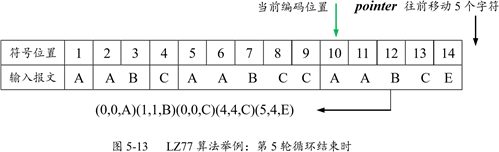
第五輪迴圈結束時,整個壓縮處理即告結束。
在第五輪迴圈中,我們看到搜尋過程並非一個簡單的順序查詢,實際上是一個從多個匹配逐步演變為最佳匹配的過程。因此,如果要真正實現 LZ77 演算法,在搜尋過程中,還需要精心設計有效的資料結構。
作為最早提出來的詞典編碼演算法,LZ77 的開創性貢獻自不待言,但也存在一些需要改進的地方。首先,輸出資料的格式可以簡化,例如,在沒有找到匹配模式的時候,只要輸出下一個字元(next_char)即可,不需要採用(0,0,next_char)這種格式,這樣可以消除不少冗餘。第二,匹配模式的最小長度需要往上提高,因為匹配長度越短,意味著壓縮效率越低,但輸出資料消耗的儲存空間不會減少。第三,在可以找到匹配模式的情況下,輸出資料中不需要捎帶 next_char,因為這時 next_char 是直接複製到輸出資料中去了,實際上沒有參與壓縮,如果將它留下來參與後續的壓縮,可以提高整個壓縮過程的有效性。
LZSS 演算法
LZSS 演算法正是在 LZ77 演算法基礎上改進而來的,它的總體框架與 LZ77 演算法一樣,主要區別在於它設定了一個最小匹配長度,並改進了輸出資料格式。如果匹配模式的長度大於最小匹配長度,就輸出(off,length),否則就直接輸出原字元序列(其長度取決於最小匹配長度,例如,如果最小匹配長度為 2,那麼直接輸出的原字元長度等於 1)。
程式碼 5-2 給出了 LZSS 演算法的偽碼描述。
程式碼 5-2 描述 LZSS 演算法的偽碼
______________________________________________________________________________ Algorithm_LZSS( input:message output: compressed_message)
{ set current coding position pointer to the start of message;
set MINIMUM_MATCHED_LENGTH;
while ( TRUE) { search the max matched string in the slide window;
get the off and the length;
if ( length ≥ MINIMUM_MATCHED_LENGTH ){
add (off, length) to the end of compressed_message; move the current coding position pointer ahead length;
} else{ add original_char_string to the end of compressed_message; move the current coding position pointer ahead length of original_char _string;
}
If ( the current coding position pointer is the end of message) return ; }
}
_______________________________________________________________________________
我們還是來看一個示例。設輸入報文是(AABBCBBAABC),搜尋視窗長度為 10,最小匹配長度 MINIMUM_MATCHED_LENGTH=2。
從第一輪迴圈開始,直到編碼位置移動到 5 為止,由於搜尋不到等於或大於 2 的匹配模式,因此得到的輸出編碼是原字元序列 AABBC 的拷貝。這之後,當前編碼位置移到了第 6 個字元 B,演算法接著在視窗中搜索,結果找到 BB 這一匹配模式,偏移量等於 3,長度為 2,所以演算法將編碼(3,2)新增到壓縮報文尾部,得到 AABBC(3,2)。接著將當前編碼位置移到第 8 個字元,開始新一輪搜尋,結果找到 AAB 這個匹配模式,偏移量為 7,匹配長度等於 3,
因此將編碼(7,3)新增到輸出資料尾部,得到 AABBC(3,2)(7,3)。最後輸出為拷貝的字元 C,從而得到最終壓縮結果 AABBC(3,2)(7,3)C。
在相同的計算環境下,LZSS 演算法的壓縮效率比 LZ77 演算法高,而譯碼同樣簡單。這也就是為什麼這種演算法成為開發新演算法的基礎,許多後來開發的文件壓縮程式都使用了 LZSS 演算法。例如,PKZip、ARJ、LHArc 和 ZOO 等等,其差別僅僅是指標的長短和視窗的大小等有所不同。此外,LZSS 演算法常常與熵編碼聯合使用,例如 ARJ 就與霍夫曼編碼聯用,而 PKZip 則與夏農-範諾演算法聯用,它的後續版本也集成了霍夫曼編碼技術。