
一趟聚類(One-pass Cluster)及python實現
阿新 • • 發佈:2018-12-02
最近在學資料探勘的相關基礎知識,希望對學習的內容進行整理,以下轉自很棒的師兄的部落格~
一趟聚類簡介
一趟聚類演算法是由蔣盛益教授提出的無監督聚類演算法,該演算法具有高效,簡單的特點。資料集只需要遍歷一遍即可完成聚類。演算法對超球狀分佈的資料有良好的識別,對凸型資料分佈識別較差。 一趟聚類可以在大規模資料,或者二次聚類中,或者聚類與其他演算法結合的情況下,發揮其高效,簡單的特點
演算法流程
1.初始時從資料集讀入一個新的物件
2.以這個物件構建一個新的簇
3.若達到資料集末尾,則轉6,否則讀入一個新的物件;計算它與每個已4有簇之間的距離,並選擇與它距離最小的簇
4.
5.否則將物件併入該簇,並更新簇心,轉3
6.結束
距離公式
在本演算法中,我採用的是歐氏距離公式計算節點與簇心之間的距離
歐氏距離公式

在python程式碼中,使用numpy包可以輕易地實現
import numpy as np
def euclidian_distance(vec_a, vec_b):
return np.sqrt(np.sum(np.square(np.array(vec_a) - vec_b)))程式碼實現
def clustering(self):
self.cluster_list.append(ClusterUnit()) # 初始新建一個簇 實驗
實驗說明
現有中國天氣的資料集,資料包括中國各個城市每年的最低和最高溫以及該城市的x,y座標。
現在分別使用nltk包中自帶的k-mean聚類演算法和上述的一趟聚類演算法對中國城市的氣溫情況進行聚類。每個城市的屬性只考慮2個屬性分別為最高氣溫和最低氣溫。
最後使用matplotlib包對聚類結果進行構圖。
其中k-means,初始設定的k的個數為5; 一趟聚類,閾值初始設定為9,最後聚類出10個簇。
實驗結果
執行時間
針對該份資料集,通過多次執行計算執行時間求平均值
得出:
k-means: 0.00024s
one-pass cluster: 0.00008s
不難看出一趟聚類由於演算法自身的簡單,執行速度相比於k-means有顯著的提升。
聚類效果
不能只看執行時間,我們同樣也要觀察聚類的效果如何。現有2幅分別為k-means和一趟聚類的效果圖。
k-means聚類效果圖

一趟聚類效果圖

中國年平均氣溫圖
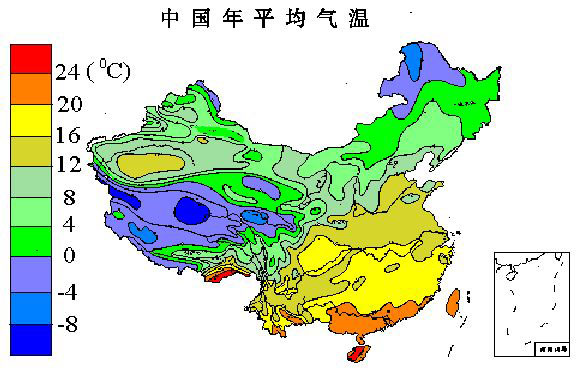
通過簡單的目測對比可得,一趟聚類和k-means聚類的效果都能夠有效地反映出中國氣溫的分佈。綜上所述,一趟聚類是一種較為有效的聚類演算法,考慮到它的演算法簡單,該演算法在處理大資料上有著顯著的優越性。
完整程式碼