文字聚類演算法之一趟聚類(One-pass Cluster)演算法的python實現
阿新 • • 發佈:2019-01-25
一、演算法簡介
一趟聚類演算法是由蔣盛益教授提出的無監督聚類演算法,該演算法具有高效、簡單的特點。資料集只需要遍歷一遍即可完成聚類。演算法對超球狀分佈的資料有良好的識別,對凸型資料分佈識別較差。一趟聚類可以在大規模資料,或者二次聚類中,或者聚類與其他演算法結合的情況下,發揮其高效、簡單的特點;
演算法流程:
1. 初始時從資料集讀入一個新的物件
2. 以這個物件構建一個新的簇
3. 若達到資料集末尾,則轉6,否則讀入一個新的物件;計算它與每個已有簇之間的距離,並選擇與它距離最小的簇。
4. 若最小距離超過給定的閾值r,轉2
5. 否則將物件併入該簇,並更新簇心,轉3
6. 結束
在本演算法中,採用的是歐式距離公式計算節點與簇心之間的距離
歐式距離公式:
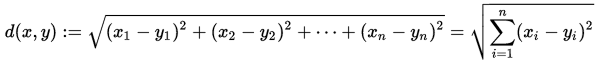
二、實驗
實驗資料集:
中國天氣的資料集,包括中國各個城市每年的最低和最高溫以及該城市的x,y座標。
實驗資料:
python程式碼:
# coding=utf-8 import numpy as np from math import sqrt import time import matplotlib.pylab as pl # 定義一個簇單元 class ClusterUnit: def __init__(self): self.node_list = [] # 該簇存在的節點列表 self.node_num = 0 # 該簇節點數 self.centroid = None # 該簇質心 def add_node(self, node, node_vec): """ 為本簇新增指定節點,並更新簇心 node_vec:該節點的特徵向量 node:節點 return:null """ self.node_list.append(node) try: self.centroid = (self.node_num * self.centroid + node_vec) / (self.node_num + 1) # 更新簇心 except TypeError: self.centroid = np.array(node_vec) * 1 # 初始化質心 self.node_num += 1 # 節點數加1 def remove_node(self, node): # 移除本簇指定節點 try: self.node_list.remove(node) self.node_num -= 1 except ValueError: raise ValueError("%s not in this cluster" % node) # 該簇本身就不存在該節點,移除失敗 def move_node(self, node, another_cluster): # 將本簇中的其中一個節點移至另一個簇 self.remove_node(node=node) another_cluster.add_node(node=node) # cluster_unit = ClusterUnit() # cluster_unit.add_node(1, [1, 1, 2]) # cluster_unit.add_node(5, [2, 1, 2]) # cluster_unit.add_node(3, [3, 1, 2]) # print cluster_unit.centroid def euclidian_distance(vec_a, vec_b): # 計算向量a與向量b的歐式距離 diff = vec_a - vec_b return sqrt(np.dot(diff, diff)) # dot計算矩陣內積 class OnePassCluster: def __init__(self, t, vector_list): # t:一趟聚類的閾值 self.threshold = t # 一趟聚類的閾值 self.vectors = np.array(vector_list) self.cluster_list = [] # 聚類後簇的列表 t1 = time.time() self.clustering() t2 = time.time() self.cluster_num = len(self.cluster_list) # 聚類完成後 簇的個數 self.spend_time = t2 - t1 # 聚類花費的時間 def clustering(self): self.cluster_list.append(ClusterUnit()) # 初始新建一個簇 self.cluster_list[0].add_node(0, self.vectors[0]) # 將讀入的第一個節點歸於該簇 for index in range(len(self.vectors))[1:]: min_distance = euclidian_distance(vec_a=self.vectors[0], vec_b=self.cluster_list[0].centroid) # 與簇的質心的最小距離 min_cluster_index = 0 # 最小距離的簇的索引 for cluster_index, cluster in enumerate(self.cluster_list[1:]): # enumerate會將陣列或列表組成一個索引序列 # 尋找距離最小的簇,記錄下距離和對應的簇的索引 distance = euclidian_distance(vec_a=self.vectors[index], vec_b=cluster.centroid) if distance < min_distance: min_distance = distance min_cluster_index = cluster_index + 1 if min_distance < self.threshold: # 最小距離小於閾值,則歸於該簇 self.cluster_list[min_cluster_index].add_node(index, self.vectors[index]) else: # 否則新建一個簇 new_cluster = ClusterUnit() new_cluster.add_node(index, self.vectors[index]) self.cluster_list.append(new_cluster) del new_cluster def print_result(self, label_dict=None): # 打印出聚類結果 # label_dict:節點對應的標籤字典 print "******* one-pass cluster result ***********" for index, cluster in enumerate(self.cluster_list): print "cluster:%s" % index # 簇的序號 print cluster.node_list # 該簇的節點列表 if label_dict is not None: print " ".join([label_dict[n] for n in cluster.node_list]) # 若有提供標籤字典,則輸出該簇的標籤 print "node num: %s" % cluster.node_num print "-------------" print "the number of nodes %s" % len(self.vectors) print "the number of cluster %s" % self.cluster_num print "spend time %.9fs" % (self.spend_time / 1000) # 讀取測試集 temperature_all_city = np.loadtxt('c2.txt', delimiter=",", usecols=(3, 4)) # 讀取聚類特徵 xy = np.loadtxt('c2.txt', delimiter=",", usecols=(8, 9)) # 讀取各地經緯度 f = open('c2.txt', 'r') lines = f.readlines() zone_dict = [i.split(',')[1] for i in lines] # 讀取地區並轉化為字典 f.close() # 構建一趟聚類器 clustering = OnePassCluster(vector_list=temperature_all_city, t=9) clustering.print_result(label_dict=zone_dict) # 將聚類結果匯出圖 fig, ax = pl.subplots() fig = zone_dict c_map = pl.get_cmap('jet', clustering.cluster_num) c = 0 for cluster in clustering.cluster_list: for node in cluster.node_list: ax.scatter(xy[node][0], xy[node][1], c=c, s=30, cmap=c_map, vmin=0, vmax=clustering.cluster_num) c += 1 pl.show()
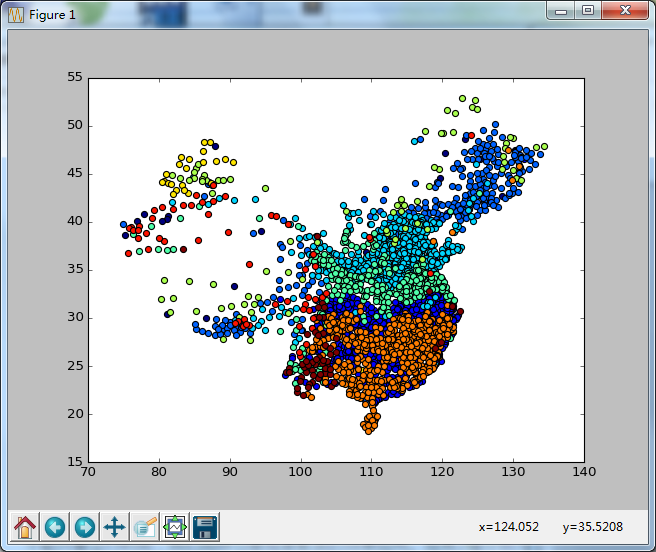
實驗結果: