
語義分割論文閱讀
之前看了一些介紹語義分割的論文,但是沒有記筆記,因為想把時間花在跑模型,增強工程能力上。現在參照別人的文章,把看過的幾篇論文做一個簡單的總結。
1. FCN
網路結構如下圖,即輸入圖片通過CNN網路提取特徵,之後經過上取樣,將特徵恢復成原圖大小,從而達到畫素級別的分割:
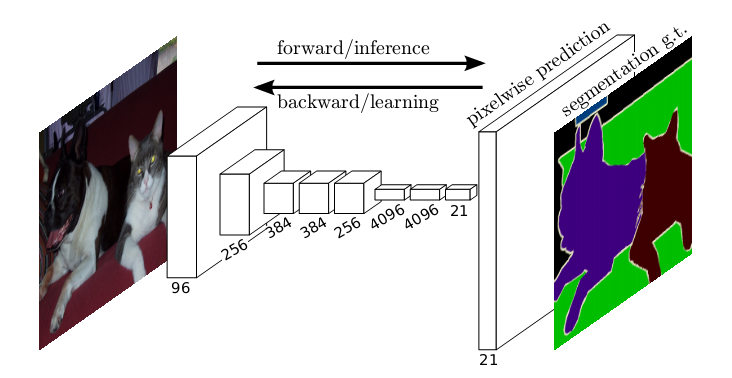
全卷積網路,有三個特點:
1. 將全連線層替換為全卷積層,即最後一層是通過卷積生成,1*1*2046個特徵,而非直接變成全連線層。 我理解去掉全連線層好處是,卷積層可以對任意大小的feature map 進行卷積,從而最開始輸入的圖片大小就可變了。而全連線層由於計算方法的區別,必須對輸入的feature map進行統一大小,不然就無法計算。其他方面應該是一樣的。可以自己手推一下。如圖所示,將全連線層替換為全卷積層
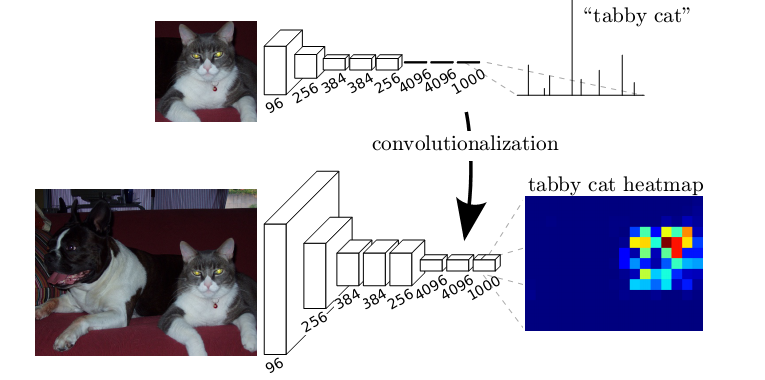
2. 上取樣。我覺得這點很重要,將提取的高維抽象特徵,經過上取樣恢復成原圖大小,各個channel再疊加起來,完成了畫素級別的特徵提取。上取樣方法和CNN 反向傳播求梯度時的上取樣方法一樣, 此處可參考其他人手推的BP演算法在CNN網路中的實現。這個實現很重要,有必要自己學會如何手推。
3. 跨層連線。這點沒什麼好說的,目的就是通過獲取多層特徵,從而對feature的還原度好一點。論文實現了32倍,16倍和8倍上取樣(三種框架),上取樣方法如下圖所示.
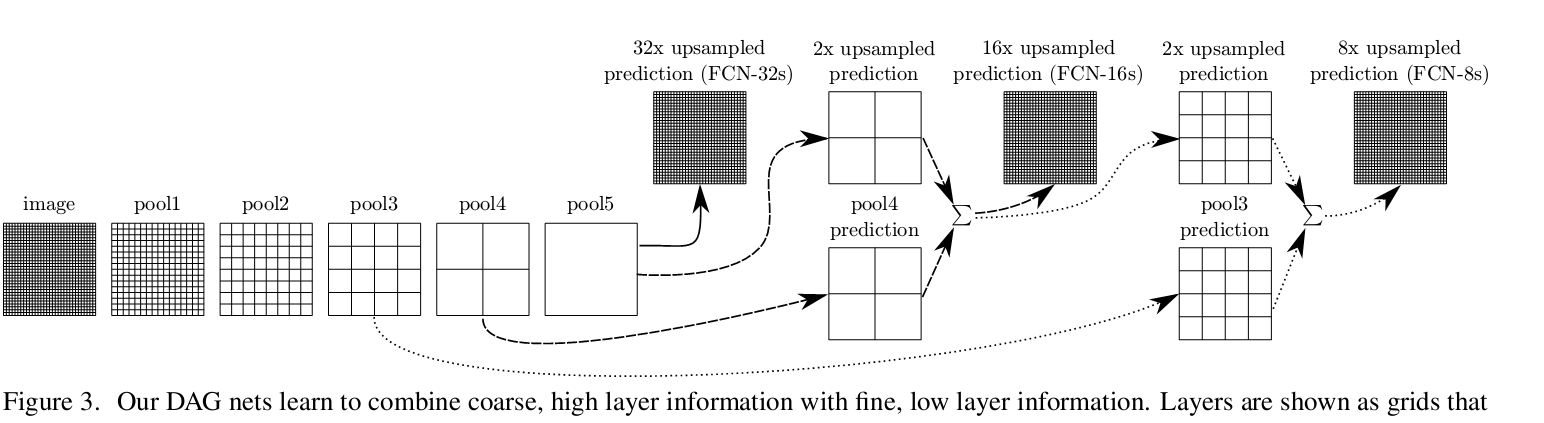
下圖是3種倍數的上取樣的分割效果,可以看到8倍上取樣的分割效果最好。論文裡也嘗試融合更多層特徵,之後再上取樣,但是改善效果不大

損失函式,參照我上一篇部落格相關介紹:

2. U-net
這個框架經常被用來進行Kaggle比賽,用作baseline,應該是因為模型簡單,非常快,用少量影象也訓練得比較好。而且最開始也是用作醫學影象標記的,對小物體效果也很好。不過現在已將發展到DeepLab V3及Mask-RCNN了,我覺得後面兩個模型更好。
下圖就是網路結構。由此也可以看出來為毛要叫U-net了。對FCN的一種改進吧,上取樣過程中融合了更多層的原feature map的資訊,同時注意是通過增加channel的方式來進行的融合,先裁剪成2*2,之後按通道加到上取樣後的通道中,而非FCN的直接求和來疊加feature map的資訊。這點可以從channel數量看出來。通道數很大,這樣可以將上下文資訊傳到解析度更高的層中去。
左邊是下采樣,不斷提取特徵,同時解析度下降,右邊是上取樣,增大解析度,同時融合原feature map資訊,目的是增強位置資訊。因為越抽象到高層,特徵所表達的位置資訊就越若。增加底層的feature map的資訊,就可增強上下文資訊。這點下一篇部落格會專門寫一下相關網路架構。

說一下其損失函式的定義。這個定義的損失函式比價複雜,原因是為了將相互接觸的目標分開,是按照位置賦予畫素一個權重,對比機器學習KNN及線性分類器及SVM這種,很像按高斯核來確定的一個權重。畢竟細胞是相互接觸的,實際Kaggle中用的U-net損失函式定義和其他無區別,因為比賽重疊的物體很少。
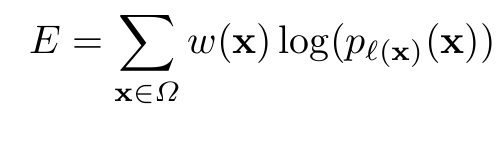
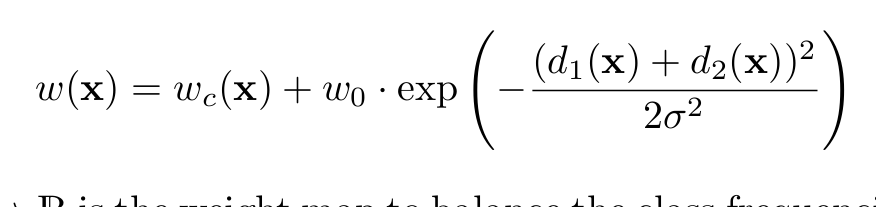
3. Segnet
沒什麼好說的,看網路結構,感覺和U-net很像,都是編碼解碼過程,而且看後面感覺也沒什麼人用,就沒怎麼看。創新點是池化過程中記住了位置資訊,上取樣時按位置資訊恢復可以更好還原影象。 我本來以為之前所有的都是按這種形式做得,這個以後有時間要看下tensorflow的原始碼上取樣實現過程了
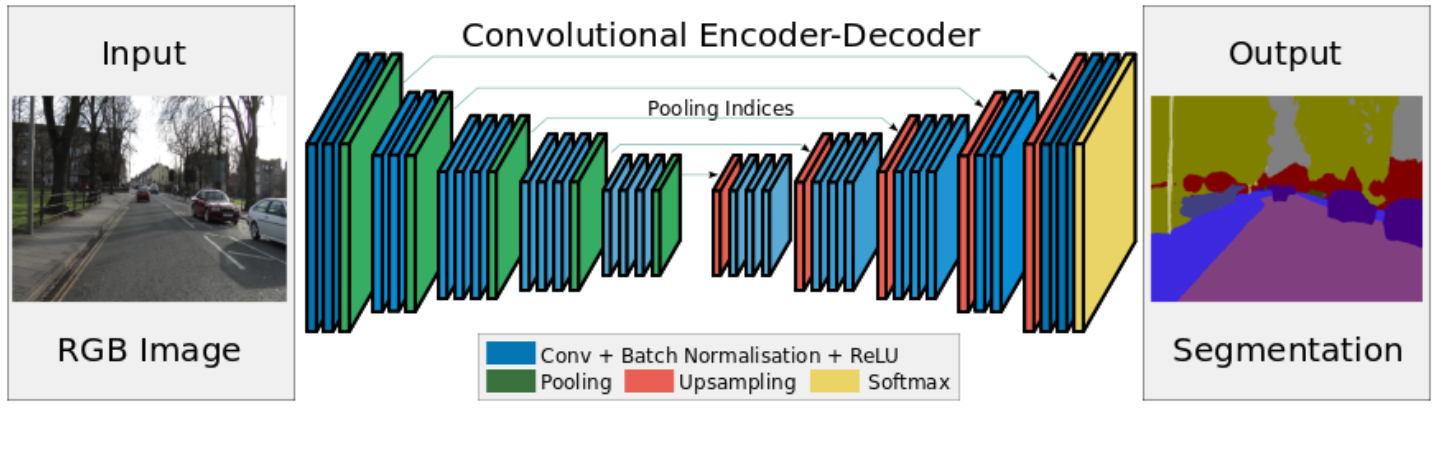
4. Deeplab系列
deeplabv1&v2
Deeplab講一下空洞卷積的概念。其實後面是用條件隨機場做過影象處理,增強影象位置資訊,但是條件隨機場,概率圖這部分看著頭大,公式推過幾遍,但是當時學的時候沒有用到什麼演算法例項,而且DeeplabV3把這部分也去掉了,就先不寫。下面就是整體的流程。j簡單講一下v1,v2,其實也沒怎麼看。感覺不如直接講V3和V3+。
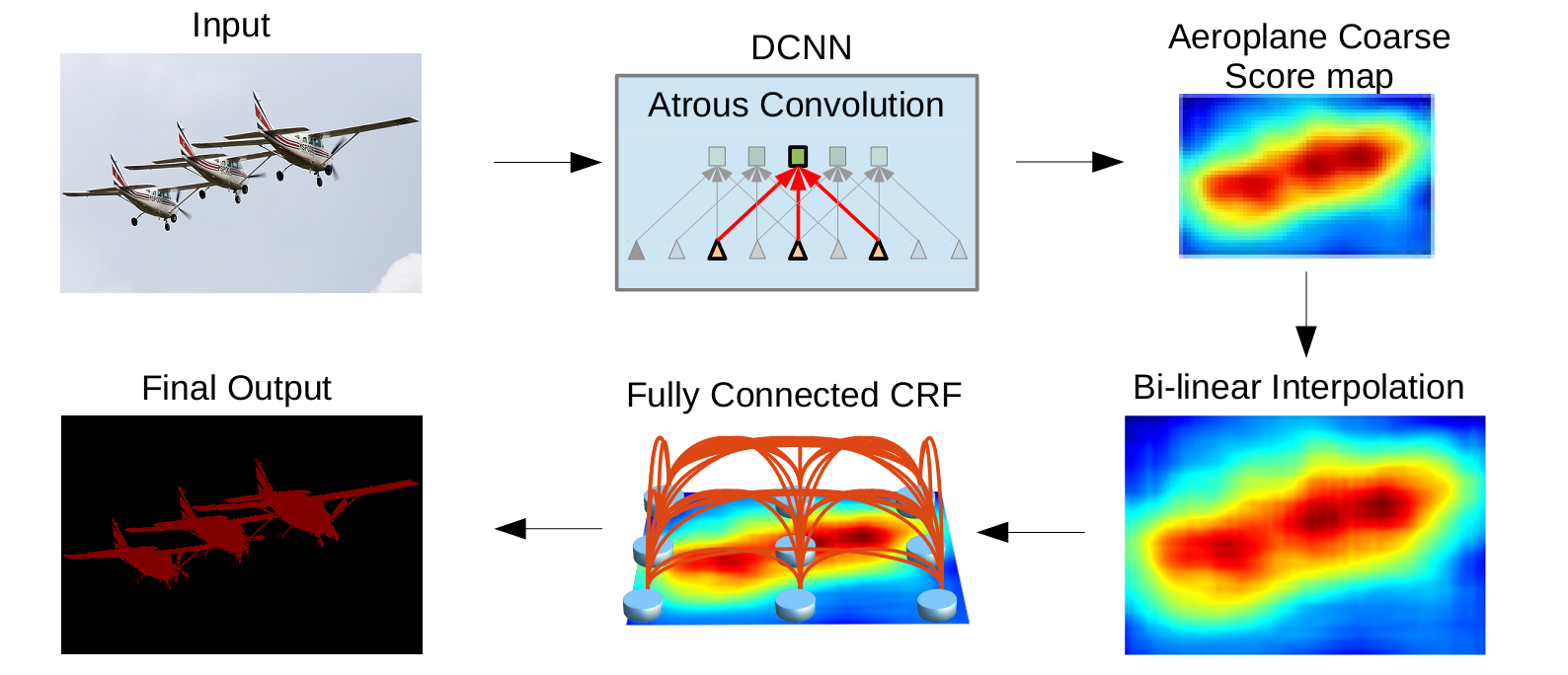
空洞卷積的引入就是在不減小解析度的情況下增加感受野。上一篇部落格講過。空洞率rate就是空洞的個數+1. 可以看到對相個數同的畫素點進行卷積操作,空洞卷積的感受野明顯增大。

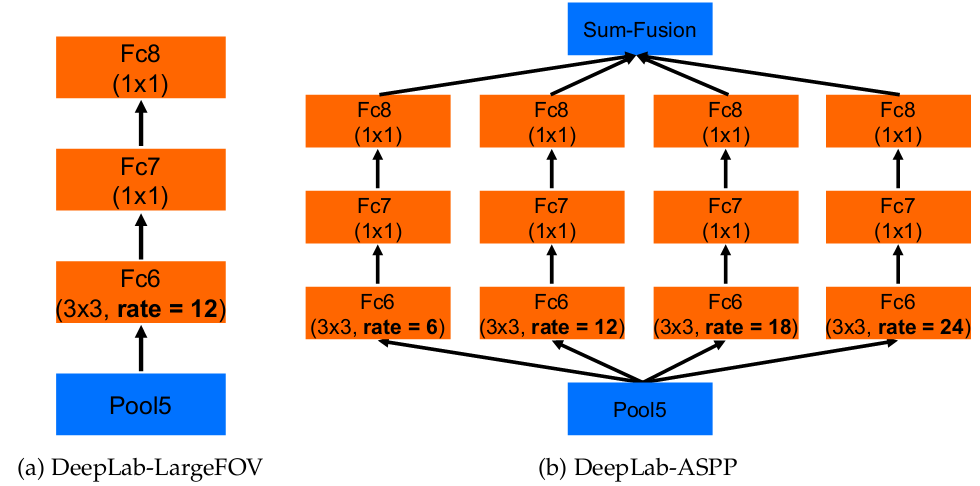
Deeplab V2相比V1其實就是增加了使用不同空洞率的卷積核來進行卷積,就好像增加了不同尺度的feature map,之後對這些進行了融合。沒仔細看,不講了,簡單如下圖

Deeplab V3
感覺相比前兩種,V3改進就是嘗試了ASPP模組的改進,基礎網路還是resnet。V3和V3+這兩篇論文比較重要,也看了原始碼,但是暫時沒時間仔細看,看完原始碼之後再寫篇部落格專門寫一下。
最開始,如圖所示有以下幾種級聯方式。
1.不同尺寸的影象進行輸入,之後將feature map融合進來。常見於人臉檢測中。
2. 編碼解碼方式。比如U-net
3. 串聯結構
4.並聯結構
後兩種結構均在本文做了嘗試
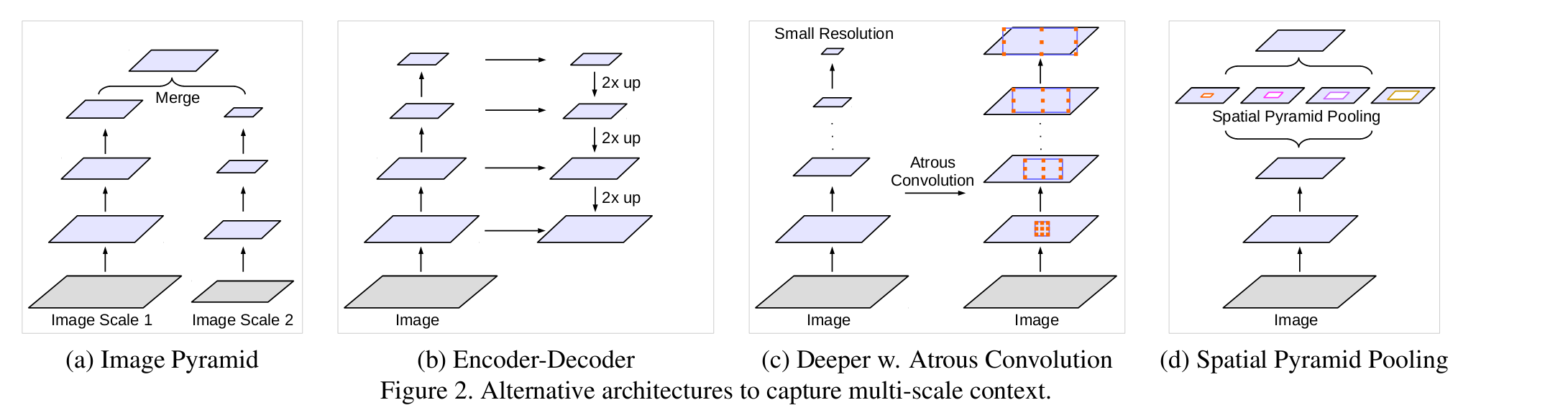
並聯方式改進如下,增加了1*1的卷積和全域性池化層。1*1卷積可以看成空洞rate特別大的卷積,而image pooling 相當於對全域性圖片進行平均池化,成為一個點,之後經過一個1*1的卷積後,採用雙線性差值進行上取樣:

論文也嘗試過串聯結構,但是貌似效果不好?

DeeplabV3+
18頁的論文,真是。。太麻煩了。其實就兩點,對DeeplabV3的進一步優化,加入了編碼解碼結構。ASPP結構是編碼,後續上取樣加入了底層的featur map資訊,目的是增強位置敏感性?第二點就是基礎模型的改進。。
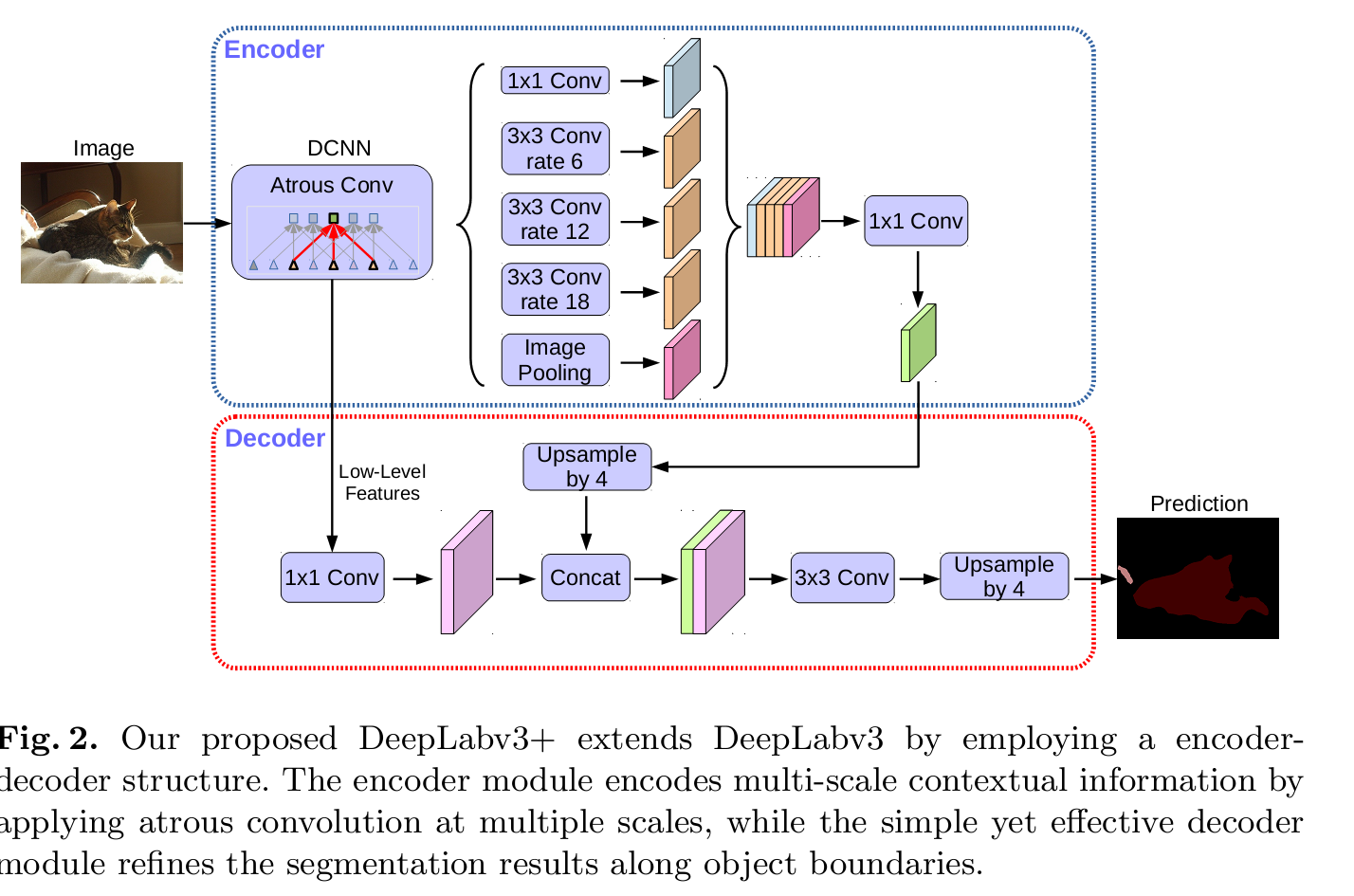
網路結構不再是Resnet,變成了Xception.不會的可以參考下其他人的部落格。。我下一篇也會寫這個模型。。。
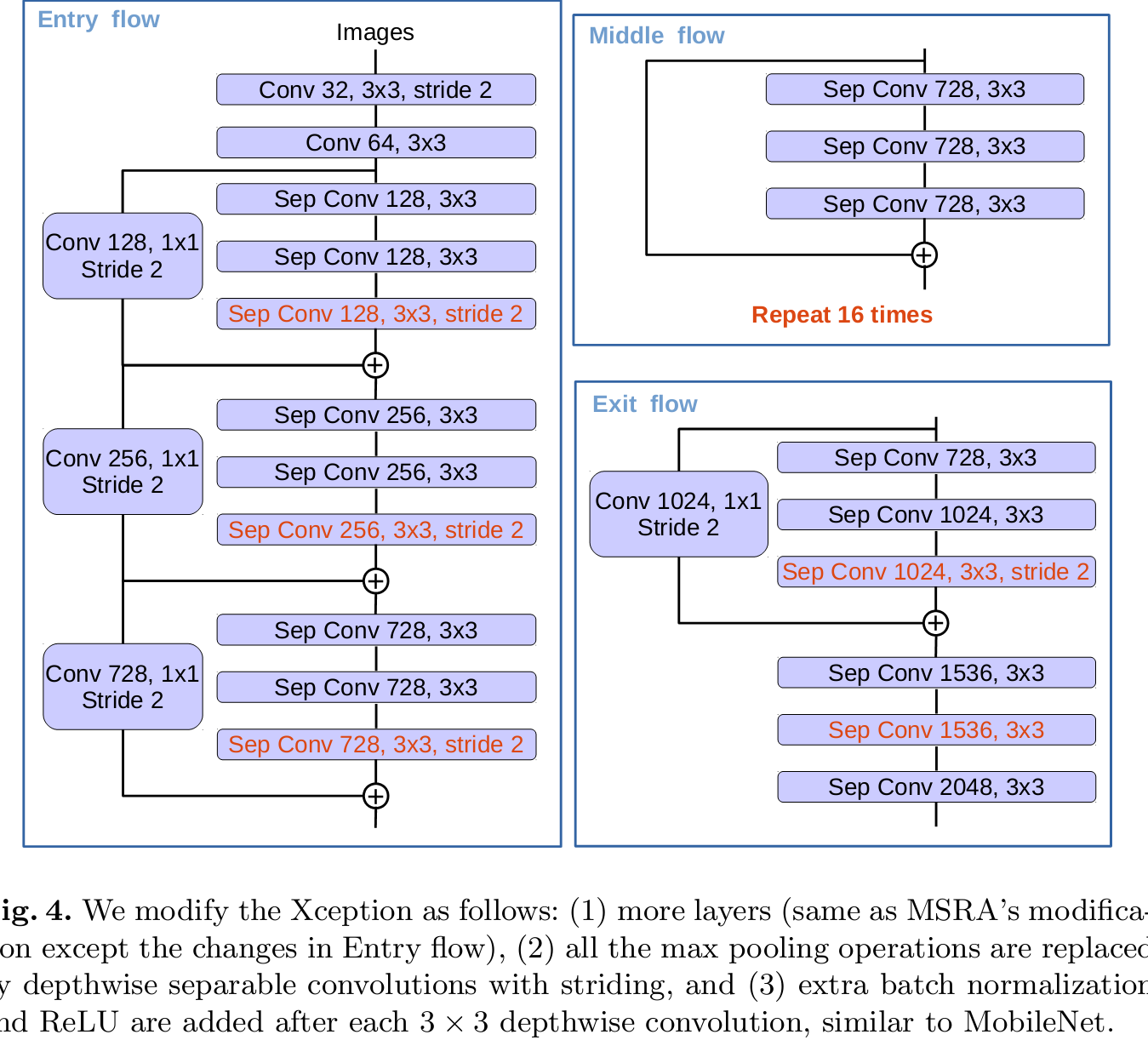
Deeplab系列就這樣吧。這一系列看的有點著急,而且是好久之前看的重新寫心得,其實很有必要實現下原始碼增強理解。。下週會寫一份原始碼的閱讀記錄。。。
PSPnet
PSPnet其實在DeeplapV3之前,DeeplabV3就是吸取了它的global pooling層的特點做得一個改進。global pooling的意義就是吸取不同尺度的特徵資訊,也包含了位置的資訊。經過不同尺度的global pooling,形成1*1,2*2,3*3和6*6後的feature map,之後卷積,減小通道個數。在進行上取樣(雙線性差值方法)和未經過pooling的層進行融合。進行分割。整體過程如下圖:

Large Kernel matters
大卷積有利於掌握全域性資訊,但是前面global pooling和1*1會損失位置資訊,且單純大卷積會造成計算量大,所以本文采用了GCN形式,且通過殘差模組來提高邊緣資訊。我不是很理解GCN是怎麼實現的,難道padding是使用的same padding?沒有看原始碼,只看了下大致的結構。流程如下,看到增加的新模組是GCN和BR結構。

Refinet 沒看,以後再補上
Mask-RCNN
Mask-RCNN是很厲害的一個網路了,這個的原始碼是必須要看的。而且在Kaggle比賽中也有用這個打比賽的,效果很好。整體還從語義分割直接連線到的例項分割的層次,即有目標檢測加語義分割兩個的融合。
對Fster-RCNN的改進:
1. 增加mask分支,增加畫素級別分類。採用了FCN結構,效果反映在loss函式上對預測目標的進一步優化結構如下:


loss函式如下,對每一個畫素預測一個二值掩膜,即0,1。即對每一個RPN預測K(類別)個m*m個值,每個類別損失函式單獨算。m*m個2值,由此來計算損失:

2. 對池化進行了優化,採用ROIalign,即使用線性插值方法對池化操作進行優化,目的是達到畫素級別的對準。感覺這個很早就用在了語義分割裡?具體如下:

這套方案將目標檢測和語義分割結合起來,不是單獨的用畫素塊標記出物體,同時還可以告訴你這個畫素塊屬於哪一種類別。結果如下:
