
前端工程師為什麼要學習編譯原理?
轉自:https://zhuanlan.zhihu.com/p/31096468
前言
普遍的觀點認為,前端就是打好 HTML、CSS、JS 三大基礎,深刻理解語義化標籤,瞭解 N 種不同的佈局方式,掌握語言的語法、特性、內建 API。再學習一些主流的前端框架,使用社群成熟的腳手架,即可快速搭建一個前端專案。勝任前端工作非常容易。再往深處學習,你會發現前端這個領域,總是有學不完的框架、工具、庫,不斷有新的輪子出現。技術推陳出新,版本快速迭代,但萬變不離其宗。工具致力於流程自動化、規範化,服務於簡潔、優雅、高效的編碼,將問題高度抽象化、層次化。在如今前端開源界如此火熱的現狀下,框架的使用者與框架的維護者聯絡更加緊密,不僅能深入原始碼來更徹底地認識框架,還能夠提出問題,參與討論,貢獻程式碼,共同解決技術問題,推進前端生態的發展和壯大。而編譯原理,作為一門基礎理論學科,除了 JS 語言本身的編譯器之外,更成為 Babel、ESLint、Stylus、Flow、Pug、YAML、Vue、React、Marked 等開源前端框架的理論基石之一。瞭解編譯原理能夠對所接觸的框架有更充分的認識。
什麼是編譯器?
對外部來說,編譯器是一個黑盒子,能夠把一種源語言翻譯為語義上等價的另一種目標語言。從現代高階編譯器的角度講,源語言是高階程式設計語言,容易閱讀與編寫,而目標語言是機器語言,即二進位制程式碼,能夠被計算機直接識別。從語言系統的處理角度來看,由源程式生成可執行程式的整體工作流程如圖 1 所示:
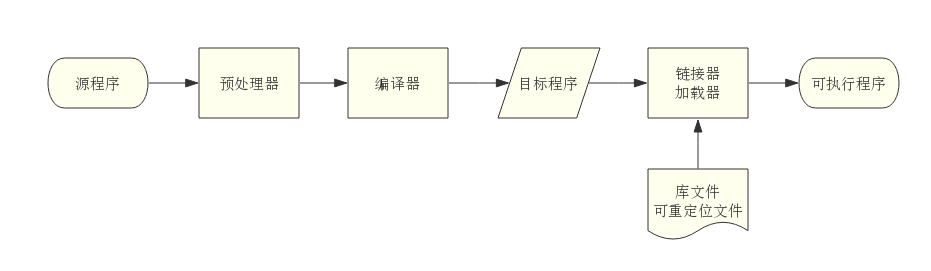 圖1 源程式生成可執行程式整體工作流程圖
圖1 源程式生成可執行程式整體工作流程圖
其中,編譯器又分為前端和後端兩個部分。前端包括詞法分析、語法分析、語義分析、中間程式碼生成,具有機器無關性,比較有代表性的工具是 Flex、Bison。後端包括中間程式碼優化、目的碼生成,具有機器相關性,比較有代表性的工具是 LLVM。在 Web 前端工程領域,由於宿主環境瀏覽器與 Node.js 的跨平臺特性,我們只需關注編譯器前端部分,就可以充分發揮它的應用價值。為了更好地理解編譯器前端的工作原理,本文將主要以目前被廣泛使用的 Babel 為例,闡述它是如何將原始碼編譯為目的碼。
Babel
作為新生代 ES 語法編譯器,Babel 在前端工具鏈中佔據了非常重要的地位,它嚴格按照 ECMA-262 語言規範,實現對最新語法的解析,而無需等待瀏覽器升級來提供對新特性的支援。Babel 內部所使用的語法解析器是 Babylon,抽象語法樹(簡寫為 AST)的結點型別定義則參考了 Mozilla JS 引擎 SpiderMonkey,並對其進行擴充套件增強,且支援對 Flow、JSX、TypeScript 語法的解析。它所使用的 Babylon 實現了編譯器中兩個部分,詞法分析和語法分析。
詞法分析
詞法分析是處理源程式的第一部分,主要任務是逐個掃描輸入字元,轉換為詞法單元(Token)序列,傳遞給語法分析器進行語法分析。Token 是一個不可分割的最小單元。例如 var 這三個字元,它只能作為一個整體,語義上不能再被分解,因此它是一個 Token。每個 Token 物件都有能夠被單獨識別的型別屬性和其它附加屬性(操作符優先順序、行列號等)。在 Babylon 詞法分析器裡,每個關鍵字是一個 Token ,每個識別符號是一個 Token,每個操作符是一個 Token,每個標點符號也都是一個 Token。除此之外,還會過濾掉源程式中的註釋和空白字元(換行符、空格、製表符等)。
對於 Token 的匹配規則,可以根據正則表示式來描述。舉個例子,要匹配一個 Number 型別的 Token,可以檢測是否以 [0-9] 開頭,接著迴圈或遞迴掃描緊連的後續字元,且需要特別留意 0b、0o、0x 開頭的非十進位制數值、科學計數法 e 或 E、小數點等特殊字元,指標不斷後移直至不滿足匹配規則或者到達行末尾。最後生成一個 Number 型別的 Token,附帶值、檔案位置等屬性,並加入到 Token 序列中,繼續下一輪掃描。
一個簡單的 Number 型別狀態轉換如圖 2 所示:
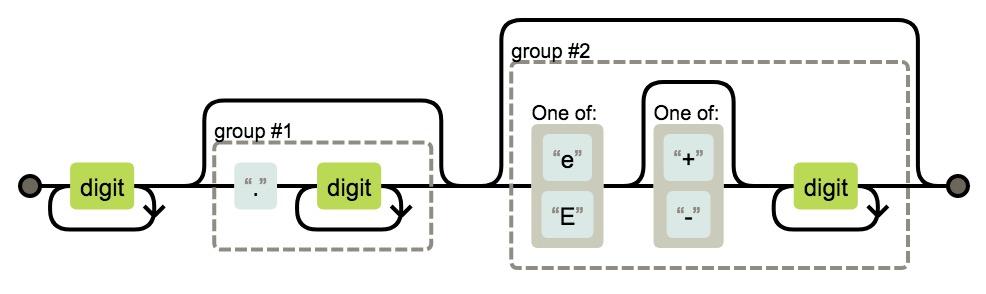 圖2 Number 型別狀態轉換示意圖
圖2 Number 型別狀態轉換示意圖
當然除了 Babylon 手寫詞法分析器之外,這個過程還可以採用有窮自動機(DFA/NFA)的方式實現,通過詞法分析器生成器,把輸入程式(模式匹配規則)自動轉換成一個詞法分析器,這裡不展開闡述。
語法分析
語法分析是詞法分析的下一步,主要任務是掃描來自詞法分析器產生的 Token 序列,根據文法和結點型別定義構造出一棵 AST,傳遞給編譯器前端餘下部分。文法描述了程式設計語言的構造規則,用於指導整個語法分析的過程。它由四個部分組成,一組終結符號(也稱 Token)、一組非終結符號、一組產生式和一個開始符號。例如,函式宣告語句的產生式表示形式如圖 3 所示:
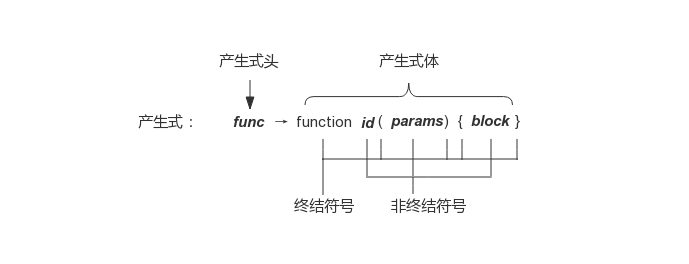 圖3 函式宣告語句的產生式
圖3 函式宣告語句的產生式
根據文法,語法分析器將 Token 逐個讀入,不斷替換文法產生式體的非終結符號,直至全部將非終結符號替換為終結符號,這個過程被稱為推導。推導又分為兩種方式,最左推導和最右推導。如果總是優先替換產生式體最左側的非終結符號,被稱為最左推導,如果總是優先替換產生式體最右側的非終結符號,被稱為最右推導。
語法分析器按照工作方式來劃分,分為自頂向下分析法和自底向上分析法。自頂向下分析法要求通過最左推導從頂部 ( 根結點 ) 開始構造 AST,常用的分析器有遞迴下降語法分析器、 LL 語法分析器。而自底向上分析法要求通過最右推導從底部 ( 葉子結點 ) 開始構造 AST,常用的分析器有 LR 語法分析器、SLR 語法分析器、LALR 語法分析器。這兩種分析方式在 Babylon 中都有所實踐。
首先是自頂向下分析法,例如變數宣告語句:
var foo = "bar";
經由詞法分析器處理後,會生成 Token 序列:
Token('var')
Token('foo') Token('=') Token('"bar"') Token(';')
由 LL(1) 語法分析器進行遞迴下降分析,每次向前檢視一個輸入 Token,來決定該用哪種產生式展開。對於變數宣告語句的 FIRST 集合(推導結果的首個 Token 集合),只需檢查輸入 Token 為 Token('var')、Token('let')、Token('const') 三者其中之一,那麼就使用該產生式展開。首先構造 AST 最頂層結點 VariableDeclaration,把 Token('var') 的值加入到該結點屬性中, 接著逐個讀入其餘 Token,根據產生式的非終結符號從左到右的順序,依次構造它的子結點,不斷遞迴下降分析,直至所有 Token 讀入完畢。最後生成的一棵 AST 如圖 4 所示:
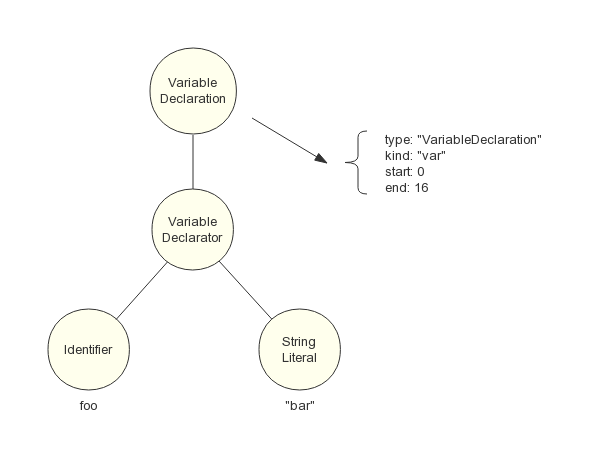 圖4 自頂向下分析法產生的 AST 樹
圖4 自頂向下分析法產生的 AST 樹
另一種是自底向上分析法,例如成員表示式語句:
foo.bar.baz.qux
我們都知道這條語句等價於:
((foo.bar).baz).qux
而不是:
foo.(bar.(baz.qux))
原因就在於它所設計的文法是左遞迴的,而 LL 語法分析器是無法做到解析左遞迴的文法,這時候只能使用 LR 語法分析器的方式,自底向上地構造 AST。LR 語法分析器的核心是移入 - 歸約分析技術,通過維護一個棧,由下一個輸入 Token 來決定是把它移入棧中還是將棧頂的部分符號進行歸約(把產生式體替換為產生式頭),先構造子結點,再構造父結點,直至棧中所有符號全部歸約。最後生成的一棵 AST 如圖 5 所示:
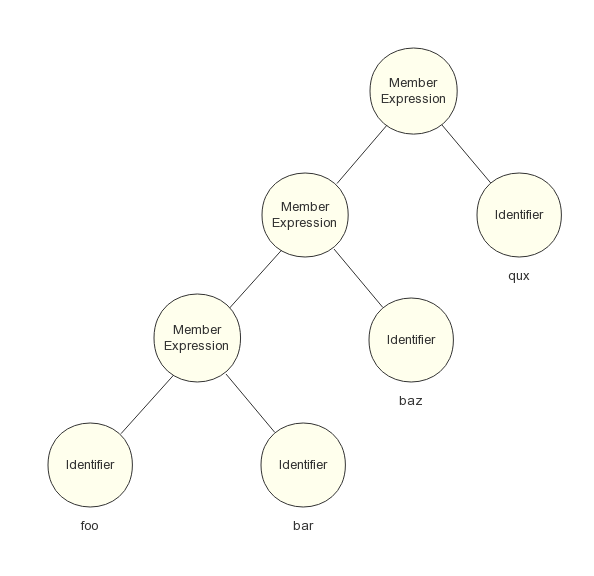 圖5 自底向上分析法產生的 AST 樹
圖5 自底向上分析法產生的 AST 樹
此外,由 Babylon 構建的完整的 AST 還擁有特殊頂層結點 File 和 Program,它們描述了檔案的基本資訊、模組型別等等。
生成程式碼
工業級別的語言編譯器,通常還會有語義分析階段,檢查程式上下文是否和語言所定義的語義一致,比如型別檢查,作用域檢查,另一個則是生成中間程式碼,比如三地址程式碼,用地址和指令來線性描述程式。但由於 Babel 的定位僅僅是對 ES 語法的轉換,這一部分工作可以交給 JS 直譯器引擎來處理。而 Babel 最為特色的部分是它的外掛機制,針對不同的瀏覽器版本環境,呼叫不同的 Babel 外掛。通過訪問者模式(一種設計模式)的介面定義,對 AST 進行一遍深度優先遍歷,對指定的匹配到的結點進行修改、刪除、新增、移位,使原先的 AST 轉換為另一棵經過修改的 AST。
一個訪問者模式的介面定義如下:
visitor: {
Identifier(path) { enter() { //遍歷AST進入Identifier結點時執行 ... }, exit() { //遍歷AST離開Identifier結點時執行 ... } }, ... }
最後一個階段則是生成目的碼,從 AST 的根結點出發,遞迴下降遍歷,對每個結點都呼叫一個相關函式,執行語義動作,不斷列印程式碼片段,最終生成目的碼,即經過 babel 編譯後的程式碼。
模板引擎
再講到模板引擎,最早誕生於服務端動態頁面的開發,如 JSP、PHP、ASP 等模板引擎,自 Node.js 快速發展以後,前端界又產出了非常多的輪子,包括 EJS、Handlebars、Pug (前身為 Jade)、Mustache 等等,數不勝數。模板引擎技術使得結合資料渲染檢視變得更加靈活,給邏輯的抽象帶來了更多的可能性,資料與內容互不依賴。模板引擎的實現方式有很多種,比較簡單的模板引擎,直接利用字串替換、拼接的方式實現,比較複雜的模板引擎,例如 Pug,則會有比較完整的詞法分析和語法分析過程,將模板預編譯成 JS 程式碼再去動態執行。
例如模板語句:
h1 hello #{name}
經由 Pug 解析器生成的 AST 如圖 6 所示:
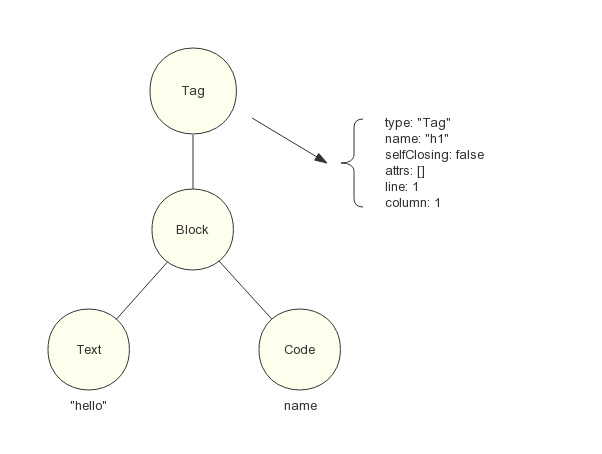 圖6 由 Pug 解析器生成的 AST
圖6 由 Pug 解析器生成的 AST
生成器生成的目的碼為(虛擬碼):
'<h1>' + 'hello' + name + '<h1>'
執行時再呼叫 new Function 來動態執行程式碼:
var compiledFn = new Function('local', ` with (local) { return '<h1>' + 'hello' + name + '<h1>'; } `) compiledFn({ name: 'world' })
最後輸出 HTML 語句:
<h1>hello world</h1>
整個過程由兩部分組成,預編譯階段和執行時階段。當然一個好的模板引擎還會考慮功能、效能與安全兼備,上面的`with`語句是要避免的,還要引入快取機制,XSS 防範機制,以及更加強大、友好、易於使用的語法糖。
另外值得一提的是以 Angular、React、Vue 為代表的前端 MVVM 框架,無一不引入了模板編譯技術。Vue 作為漸進式的前端解決方案,受到眾多開發者們的青睞,它對檢視的渲染提供了渲染函式和模板兩種方式。使用渲染函式需要呼叫核心 API 來構建 Virtual DOM 型別,過程相對複雜,編碼量非常大,一旦 DOM 層次巢狀過深,就會造成程式碼難以掌控和維護的局面。為了應對這種複雜性,另一種方式則是編寫基於 HTML 的模板,並加入 Vue 特有的標籤、指令、插值等語法,由編譯器來進行從模板到渲染函式的編譯和優化,相對前者更優雅、便捷、易於編碼。
CSS 前處理器
前端佈局方式從刀耕火種的純 CSS 年代演進到以 Sass、Less、Stylus 為代表的預處理語言,賦予了 CSS 可程式設計的能力,定義變數,函式,表示式計算、模組化等特性,極大地提升了開發人員的生產效率。這些都是編譯技術所帶來的變化。同樣,編譯器對原樣式程式碼進行詞法分析,產生 Token 序列。接著,語法分析,生成中間表示,一棵符合定義的 AST。同時,還會為每個程式塊建立一個符號表來記錄變數的名字,屬性,為程式碼生成階段的變數作用域分析提供幫助。最後,遞迴下降訪問 AST,生成能夠在瀏覽器環境中直接執行的 CSS 程式碼。
以前處理器 Stylus 語法為例:
foo = 14px
body
font-size foo
編譯生成的 AST 為圖 7 所示:
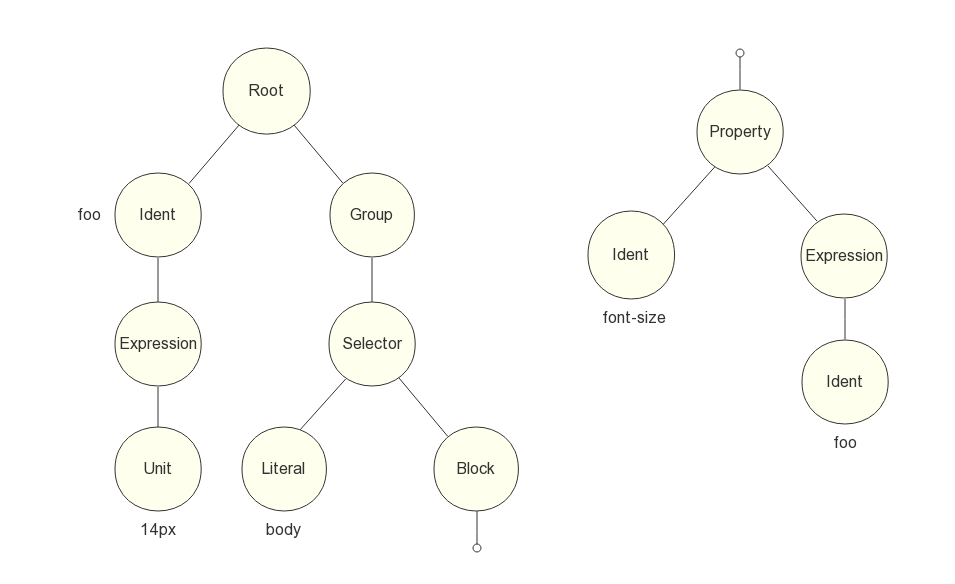 圖7 由 Stylus 解析器生成的 AST
圖7 由 Stylus 解析器生成的 AST
最後生成的目的碼為:
body {
font-size: 14px; }
看似簡單容易的程式碼轉換背後,編譯器為我們做了許多語法層面的處理,給 CSS 帶來了從未有過的強大的擴充套件能力,以及底層對編譯速度的持續優化,讓 CSS 的編寫方式更加簡潔高效,易於維護和管理。
寫在最後
寫這篇文章的目的是希望告訴讀者,編譯原理在前端工程領域的應用非常廣泛,可以用來幫助我們解決工程技術上的難點。當然在實際編碼過程中,需要非常得有耐心,細心,考慮各種文法,分析方式,優化手段,寫好測試用例等等。一個良好的編譯器需要精心打磨,不斷優化升級,全方位為開發者服務。如果你沒有學習過編譯原理相關知識,建議尋找相關書籍,系統地學習一遍知識體系。即使在實際日常工作中接觸不到編譯原理,但它對基礎知識的積累與掌握,對程式語言的認識與理解,對框架的學習與運用,對日後職業生涯的發展道路,或多或少都有幫助。
釋出於 2018-04-08