
樸素貝葉斯演算法優化與 sklearn 實現
1. 引言
上一篇日誌中,我們主要介紹了貝葉斯演算法,並提供了 python 實踐:
樸素貝葉斯演算法的推導與實踐
但執行上一篇日誌中的示例,我們發現出現了下面的結果:
['love', 'my', 'dalmation'] 屬於非侮辱類
['stupid', 'garbage'] 屬於非侮辱類
這顯然是不正確的,本文,我們就來解決這個問題,同時對演算法進行優化並使用 sklearn 來實現演算法的實踐。
2. 拉普拉斯平滑
上一篇文章中,我們利用貝葉斯分類器對文件進行分類時,需要算多個概率的乘積以獲得文件屬於某個類別的概率,即計算 p(w0|1) p(w1|1)
要降低這種影響,可以講所有詞的出現數初始化為 1,並將分母初始化為 2,這個做法就是拉普拉斯平滑。
我們將上一篇日誌中程式碼的 trainNB0 方法中的 p0Num、p1Num、p0Denom、p1Denom 賦值語句改為:
p0Num = np.ones(vocabularysNum)
p1Num = np.ones(vocabularysNum)
p0Denom = 2.0
p1Denom = 3. 下溢位問題的解決
進行拉普拉斯平滑運算後,我們執行程式,仍然得出了兩個測試樣本均屬於非侮辱類的結果,這是為什麼呢?
我們檢視最終計算出的 p0 和 p1 會發現,他們的結果都是 0,這又是為什麼呢?
這是因為出現了另一個問題 – 下溢位。
我們的概率運算中,所有參與運算的概率都太小了,小數相乘會使運算的積進一步減小,最終結果向下溢位超出了計算機浮點數的精度,就都會變成 0。
解決辦法很自然的可以想到 – 將乘法運算轉換為加法運算,但如何在保證演算法正確性的前提下進行轉換呢?
在代數中,ln(a * b) = ln(a) + ln(b),同時,自然對數可以保證運算趨勢的正確性:
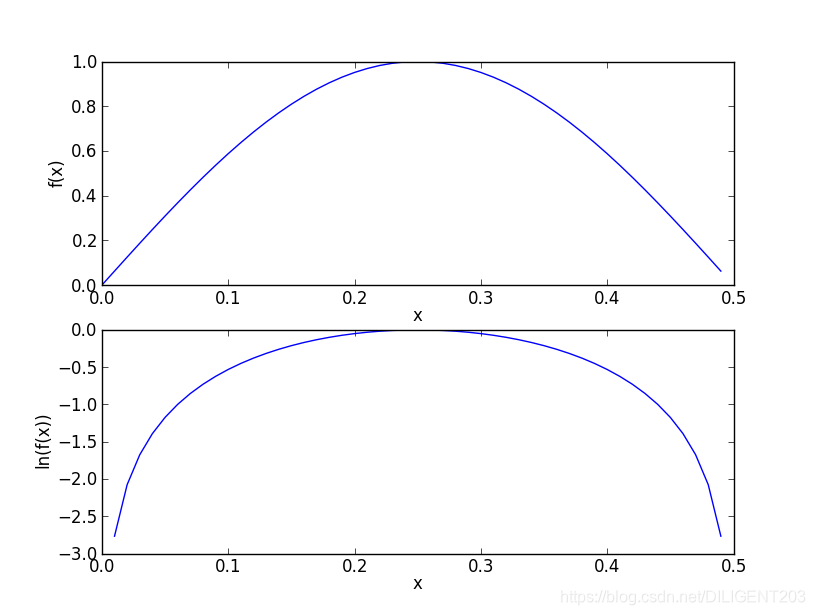
因此我們通過對數運算優化訓練函式 trainNB0 與測試函式 classifyNB:
def trainNB0(trainMap, results):
"""
樸素貝葉斯分類器訓練函式
:param trainMap: 訓練文件矩陣
:param results: 訓練類別標籤向量
:return:
p0Vect - 侮辱類的條件概率陣列
p1Vect - 非侮辱類的條件概率陣列
pAbusive - 文件屬於侮辱類的概率
"""
dataListNum = len(trainMap)
vocabularysNum = len(trainMap[0])
""" 計算文件屬於侮辱詞概率 """
pAbusive = sum(results) / float(dataListNum)
p0Num = np.ones(vocabularysNum)
p1Num = np.ones(vocabularysNum)
p0Denom = 2.0
p1Denom = 2.0
""" 將所有行按是否是侮辱類分別疊加,統計各個詞出現的次數 """
for i in range(dataListNum):
if results[i] == 1:
p1Num += trainMap[i]
p1Denom += sum(trainMap[i])
else:
p0Num += trainMap[i]
p0Denom += sum(trainMap[i])
""" 計算概率 """
p1Vect = np.log(p1Num / p1Denom)
p0Vect = np.log(p0Num / p0Denom)
return p0Vect, p1Vect, pAbusive
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
"""
樸素貝葉斯分類器分類函式
:param vec2Classify: 待分類的詞條陣列
:param p0Vec: 侮辱類的條件概率陣列
:param p1Vec: 非侮辱類的條件概率陣列
:param pClass1: 文件屬於侮辱類的概率
:return: 是否屬於侮辱類,0. 不屬於,1. 屬於
"""
p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)
print("p0: ", p0)
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1)
print("p1: ", p1)
if p1 > p0:
return 1
else:
return 0
最終我們得到了正確的結果:
p0: -7.694848072384611
p1: -9.826714493730215
['love', 'my', 'dalmation'] 屬於非侮辱類
p0: -7.20934025660291
p1: -4.702750514326955
['stupid', 'garbage'] 屬於侮辱類
4. 樸素貝葉斯演算法的優缺點
通過上一篇日誌的介紹和本文的優化,我們瞭解了樸素貝葉斯演算法的原理和應用,他是一種基於概率的分類器演算法,可以用來處理不相干因子的多分類問題,例如根據詞頻進行文字分類等問題。
那麼他又具有哪些優缺點呢?
4.1. 優點
- 演算法原理和實現簡單,通過概率分類
- 對小規模資料表現很好,適合多分類增量式訓練任務
4.2. 缺點
- 對輸入資料的表達形式很敏感
- 需要計算先驗概率,分類決策存在錯誤率
- 要求樣本之間相互獨立,這就是“樸素”的意思,這個限制有時很難做到,或使用者誤以為符合而造成錯誤的結果
5. 使用 sklearn 實現樸素貝葉斯演算法
sklearn 提供了樸素貝葉斯演算法的實現類 – sklearn.naive_bayes.MultinomialNB。
下面的列表中,我們將分類數稱為 nc,將特徵數稱為 nf。
5.1. 構造引數
sklearn.naive_bayes.MultinomialNB 類構造引數
| 引數名 | 型別 | 可選引數 | 預設值 | 說明 |
|---|---|---|---|---|
| alpha | float | 非負浮點數 | 1 | 拉普拉斯平滑係數 |
| fit_prior | boolean | True/False | True | 是否使用先驗分類概率 |
| class_prior | array | None 或array(nc*1) | None | 如果指定 fit_prior 為 True,該引數用來提供先驗概率 |
5.2. 類屬性
sklearn.naive_bayes.MultinomialNB 類屬性
| 屬性名 | 型別 | 說明 |
|---|---|---|
| class_log_prior_ | array(nc*1) | 每個分類的平滑對數先驗概率 |
| intercept_ | array(nc*1) | 將多項式樸素貝葉斯理解為線性模型時,與 class_log_prior_ 相同 |
| feature_log_prob_ | array(nc*nf) | 每個分類的每個特徵的對數先驗概率(P(x_i|y)) |
| coef_ | array(nc*nf) | 將多項式樸素貝葉斯理解為線性模型時,與 feature_log_prob_ 相同 |
| class_count_ | array(nc*1) | 在擬合過程中每個分類的樣本數 |
| feature_count_ | array(nc*nf) | 在擬合過程中每個分類的每個特徵的樣本數 |
5.3. 類方法
- fit(X, y[, sample_weight]) – 訓練樸素貝葉斯模型
- get_params([deep]) – 獲取引數
- set_params(**params) – 設定引數
- partial_fit(X, y[, classes, sample_weight]) – 部分樣本上的增量擬合
- predict(X) – 預測
- predict_log_proba(X) – 返回測試向量X的對數概率估計
- predict_proba(X) – 返回測試向量X的概率估計
- score(X, y[, sample_weight]) – 返回模型的平均精度
5.4. 示例
import numpy as np
from sklearn.naive_bayes import MultinomialNB
if __name__ == '__main__':
X = np.random.randint(5, size=(6, 100))
y = np.array([1, 2, 3, 4, 5, 6])
clf = MultinomialNB()
clf.fit(X, y)
print(clf.predict(X[2:3]))
上面的示例,我們通過隨機數建立了一個 6*100 的矩陣,其中每個元素都是0到5的隨機數,我們用這個矩陣的每一行分別對應 1、2、3、4、5、6,最終,我們用第三行來測試這個模型,果然得到了預期的數字:3。
6. 後記
對於相互獨立的樣本來說,樸素貝葉斯是一個非常不錯的分類器,在自然語言處理和文字特徵分析、過濾等領域有著廣泛的應用。
事實上,樸素貝葉斯共有三種模型,他們的區別在於計算條件概率的公式不同:
- 高斯樸素貝葉斯 – 用於符合高斯分佈(正態分佈)的連續樣本資料的分類
- 多項式樸素貝葉斯 – 我們已經介紹的內容就是多項式樸素貝葉斯模型
- 伯努利樸素貝葉斯 – 每個特徵的取值為0或1,即計算特徵是否存在的概率,他是唯一將樣本中不存在的特徵也引入計算概率的樸素貝葉斯模型
7. 參考資料
Peter Harrington 《機器學習實戰》。
李航 《統計學習方法》。
https://zh.wikipedia.org/wiki/樸素貝葉斯分類器。
https://scikit-learn.org/dev/modules/generated/sklearn.naive_bayes.MultinomialNB.html。