
知識圖譜構建淺析
知識圖譜應用如圖所示,目前各大互聯網公司已落地多個知識圖譜產品,或者正在積極構建知識圖譜,圖譜技術成為“兵家必爭”之地。

1. 什麽是知識圖譜?
知識圖譜(Knowledge Graph)的概念由谷 歌 2012 年正式提出,旨在實現更智能的搜索引擎,並且於 2013 年以後開始在學術界和業界普及,並在智能問答、情報分析、反欺詐等應用 中發揮重要作用。
知識圖譜以語義網( Semantic Web) 和領域本體( Ontology) 為其關鍵技術的大規模語義網絡知識庫。
Knowledge Graph是結構化的語義知識庫,用於以符號形式描述物理世界中的概念及其相互關系。其基本組成單位是“實體-關系-實體”三元組,以及實體及其相關屬性-值對,實體間通過關系相互聯結,構成網狀的知識結構。Knowledge Graph本質是以語義三元組為基礎的結構化的海量知識庫。
知識圖譜的定義讓人不明覺厲,那實際構建的知識圖譜是什麽樣子?

2. 知識圖譜的幾個關鍵概念
2.1 本體
領域術語集合。本體最為抽象,簡單理解就是一堆概念,這堆概念集合能夠描述某個具體的domain裏的一切事物的共有特征,然後概念間又有一定的關系,所有構成一個具有層級特征的結構。所以在語義網裏ontology和schema基本不分家。
在上面知識圖譜的例子中,本體是足球領域schema
2.2 類型 type
具有相同特點或屬性的實體集合的抽象,如足球球員、足球聯賽、足球教練等。
2.3 實體
實體就是type的實例,如足球球員--梅西,足球聯賽--西甲等。
2.4 關系
實體與實體之間通過關系關聯起來,如梅西是巴塞羅那的球員。
2.5 屬性
實體自帶信息是屬性,如梅西 出生日期 1987年6月24日, 身高 1.7米等。
2.6 知識圖譜
圖狀具有關聯性的知識集合。可以由三元組(實體entity,實體關系relation,實體entity)表示。
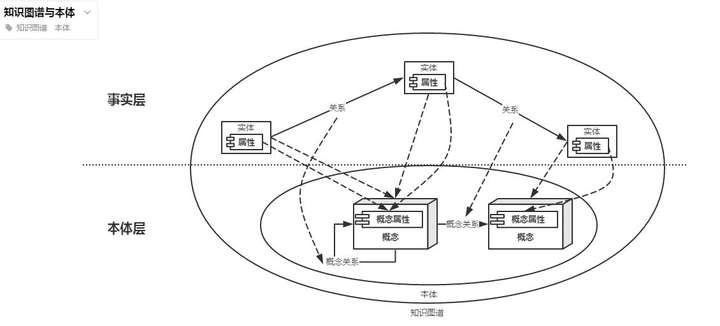
這幅圖描述了知識圖譜中的概念之間的關系。
2.7 知識庫
知識庫(Knowledge Base),就是一個知識數據庫,包含了知識的本體和知識。Freebase是一個知識庫(結構化),維基百科也可以看成一個知識庫(半結構化),等等。知識圖譜可以看成是由圖數據庫存儲的知識庫。
3. 工業界如何構建知識圖譜?
- 美圖知識圖譜技術鏈:

- 轉轉的二手電商知識圖譜構建

工業界的特點是它有細分的領域,有良好的業務模型,有大量的數據沈澱。他們一開始先構建Schema,數據有一部分來自於結構化數據,另外需要從半結構化、非結構化數據中獲取知識。轉轉的知識圖譜物品詞庫的構建,大部分數據來自 自有的結構化數據。
知識圖譜本身就是圖狀的知識,關鍵就是知識獲取,獲取圖中的元素:點、邊,即抽取實體、關系。
4. 學術界如如構建知識圖譜?
知識圖譜構建流程

知識圖譜技術

學術界是先抽取實體、關系,然後在這些數據的基礎上進行本體抽取,而且難度比較大,涉及大量本體構建的工作。
5. 小結
本體的構建大體有兩種方式:自頂向下和自底向上。
開放域知識圖譜的本體構建通常用自底向上的方法,自動地從知識圖譜中抽取概念、概念層次和概念之間的關系。這也很好理解,開放的世界太過復雜,用自頂向下的方法無法考慮周全,且隨著世界變化,對應的概念還在增長。 其中最典型就是Google的Knowledge Vault。
領域知識圖譜多采用自頂向下的方法來構建本體。一方面,相對於開放域知識圖譜,領域知識圖譜涉及的概念和範圍都是固定或者可控的;另一方面,對於領域知識圖譜,我們要求其滿足較高的精度。現在大家接觸到的一些語音助手背後對接的知識圖譜大多都是領域知識圖譜,比如音樂知識圖譜、體育知識圖譜、烹飪知識圖譜等等。正因為是這些領域知識圖譜來滿足用戶的大多數需求,更需要保證其精度。自頂向下是先為知識圖譜定義好本體與數據模式,再將實體加入到知識庫。該構建方式需要利用一些現有的結構化知識庫作為其基礎知識庫,例如Freebase項目就是采用這種方式,它的絕大部分數據是從維基百科中得到的。
學術界的本體構建一般采用自底向下,工業界一般采用自頂向下的方式構建。
知識圖譜的很多構建細節,在後續的文章中再詳細展示。
參考文獻
- https://www.zhihu.com/question/34835422/answer/272405066
- 知識圖譜的技術與應用(18版)
- 美團餐飲娛樂知識圖譜——美團大腦揭秘
- 知識圖譜基礎(一)-什麽是知識圖譜
- 本體、知識庫、知識圖譜、知識圖譜識別之間的關系?
- https://blog.csdn.net/u011801161/article/details/78910988
- 知識圖譜構建技術綜述
- 知識圖譜技術綜述
- 知識圖譜研究進展
知識圖譜構建淺析