
知識圖譜(一):概念與構建
一、引言
隨著網際網路的發展,網路資料內容呈現爆炸式增長的態勢。由於網際網路內容的大規模、異質多元、組織結構鬆散的特點,給人們有效獲取資訊和知識提出了挑戰。知識圖譜(Knowledge Graph) 以其強大的語義處理能力和開放組織能力,為網際網路時代的知識化組織和智慧應用奠定了基礎。最近,大規模知識圖譜庫的研究和應用在學術界和工業界引起了足夠的注意力[1-5]。一個知識圖譜旨在描述現實世界中存在的實體以及實體之間的關係。知識圖譜於2012年5月17日由[Google]正式提出[6],其初衷是為了提高搜尋引擎的能力,改善使用者的搜尋質量以及搜尋體驗。隨著人工智慧的技術發展和應用,知識圖譜作為關鍵技術之一,已被廣泛應用於智慧搜尋、智慧問答、個性化推薦、內容分發等領域。
二、知識圖譜的定義
在維基百科的官方詞條中:知識圖譜是Google用於增強其搜尋引擎功能的知識庫。本質上, 知識圖譜旨在描述真實世界中存在的各種實體或概念及其關係,其構成一張巨大的語義網路圖,節點表示實體或概念,邊則由屬性或關係構成。現在的知識圖譜已被用來泛指各種大規模的知識庫。 在具體介紹知識圖譜的定義,我們先來看下知識型別的定義:
知識圖譜中包含三種節點:
實體: 指的是具有可區別性且獨立存在的某種事物。如某一個人、某一個城市、某一種植物等、某一種商品等等。世界萬物有具體事物組成,此指實體。如圖1的“中國”、“美國”、“日本”等。,實體是知識圖譜中的最基本元素,不同的實體間存在不同的關係。
語義類(概念):具有同種特性的實體構成的集合,如國家、民族、書籍、電腦等。 概念主要指集合、類別、物件型別、事物的種類,例如人物、地理等。
內容: 通常作為實體和語義類的名字、描述、解釋等,可以由文字、影象、音視訊等來表達。
屬性(值): 從一個實體指向它的屬性值。不同的屬性型別對應於不同型別屬性的邊。屬性值主要指物件指定屬性的值。如圖1所示的“面積”、“人口”、“首都”是幾種不同的屬性。屬性值主要指物件指定屬性的值,例如960萬平方公里等。
關係: 形式化為一個函式,它把kk個點對映到一個布林值。在知識圖譜上,關係則是一個把kk個圖節點(實體、語義類、屬性值)對映到布林值的函式。

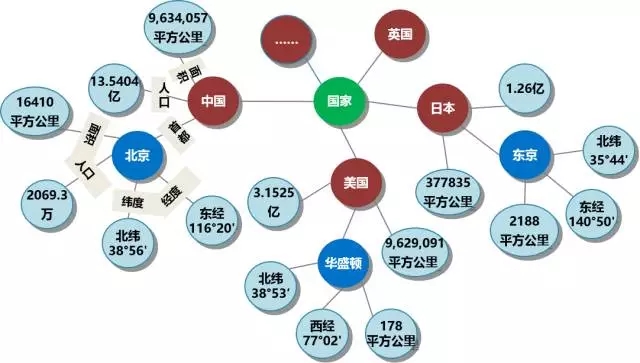
圖1 知識圖譜示例
(一)知識圖譜的架構
知識圖譜的架構包括自身的邏輯結構以及構建知識圖譜所採用的技術(體系)架構。
1) 知識圖譜的邏輯結構
知識圖譜在邏輯上可分為模式層與資料層兩個層次,資料層主要是由一系列的事實組成,而知識將以事實為單位進行儲存。如果用(實體1,關係,實體2)、(實體、屬性,屬性值)這樣的三元組來表達事實,可選擇圖資料庫作為儲存介質,例如開源的Neo4j[7]、Twitter的FlockDB[8]、sones的GraphDB[9]等。模式層構建在資料層之上,是知識圖譜的核心,通常採用本體庫來管理知識圖譜的模式層。本體是結構化知識庫的概念模板,通過本體庫而形成的知識庫不僅層次結構較強,並且冗餘程度較小。
知識圖譜可以溯源到語義技術,知識圖譜的模式層對應語義網中的本體,資料層對應語義網中的資料。
2) 知識圖譜的體系架構
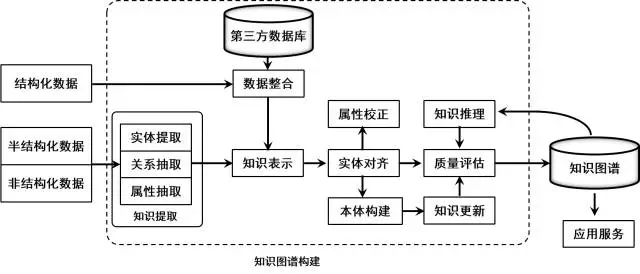
圖2 知識圖譜的技術架構
知識圖譜的體系架構是其指構建模式結構,如圖2所示。其中虛線框內的部分為知識圖譜的構建過程,也包含知識圖譜的更新過程。知識圖譜構建從最原始的資料(包括結構化、半結構化、非結構化資料)出發,採用一系列自動或者半自動的技術手段,從原始資料庫和第三方資料庫中提取知識事實,並將其存入知識庫的資料層和模式層,這一過程包含:資訊抽取、知識表示、知識融合、知識推理四個過程,每一次更新迭代均包含這四個階段。知識圖譜主要有自頂向下(top-down)與自底向上(bottom-up)兩種構建方式。自頂向下指的是先為知識圖譜定義好本體與資料模式,再將實體加入到知識庫。該構建方式需要利用一些現有的結構化知識庫作為其基礎知識庫,例如Freebase專案就是採用這種方式,它的絕大部分資料是從維基百科中得到的。自底向上指的是從一些開放連結資料中提取出實體,選擇其中置信度較高的加入到知識庫,再構建頂層的本體模式[10]。目前,大多數知識圖譜都採用自底向上的方式進行構建,其中最典型就是Google的Knowledge Vault[11]和微軟的Satori知識庫。現在也符合網際網路資料內容知識產生的特點。
(二)代表性知識圖譜庫
根據覆蓋範圍而言,知識圖譜也可分為開放域通用知識圖譜和垂直行業知識圖譜[12]。開放通用知識圖譜注重廣度,強調融合更多的實體,較垂直行業知識圖譜而言,其準確度不夠高,並且受概念範圍的影響,很難藉助本體庫對公理、規則以及約束條件的支援能力規範其實體、屬性、實體間的關係等。通用知識圖譜主要應用於智慧搜尋等領域。行業知識圖譜通常需要依靠特定行業的資料來構建,具有特定的行業意義。行業知識圖譜中,實體的屬性與資料模式往往比較豐富,需要考慮到不同的業務場景與使用人員。下圖展示了現在知名度較高的大規模知識庫。
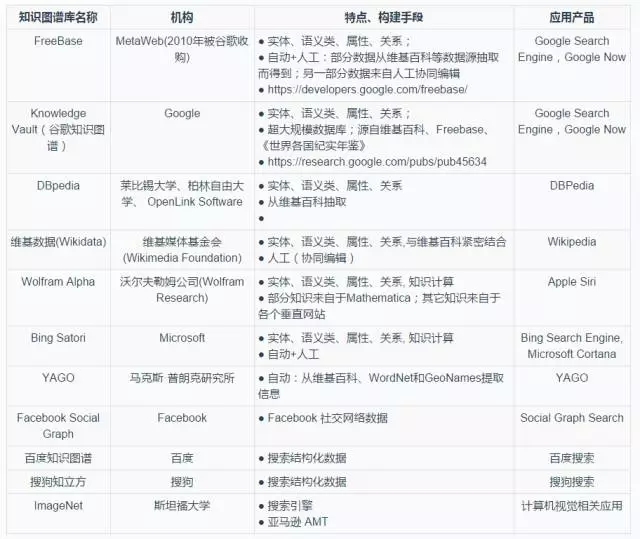
圖3 代表性知識圖譜庫概覽
三、知識圖譜構建的關鍵技術
大規模知識庫的構建與應用需要多種技術的支援。通過知識提取技術,可以從一些公開的半結構化、非結構化和第三方結構化資料庫的資料中提取出實體、關係、屬性等知識要素。知識表示則通過一定有效手段對知識要素表示,便於進一步處理使用。然後通過知識融合,可消除實體、關係、屬性等指稱項與事實物件之間的歧義,形成高質量的知識庫。知識推理則是在已有的知識庫基礎上進一步挖掘隱含的知識,從而豐富、擴充套件知識庫。分散式的知識表示形成的綜合向量對知識庫的構建、推理、融合以及應用均具有重要的意義。接下來,本文將以知識抽取、知識表示、知識融合以及知識推理技術為重點,選取代表性的方法,說明其中的相關研究進展和實用技術手段 。
(一)知識提取
知識抽取主要是面向開放的連結資料,通常典型的輸入是自然語言文字或者多媒體內容文件(影象或者視訊)等。然後通過自動化或者半自動化的技術抽取出可用的知識單元,知識單元主要包括實體(概念的外延)、關係以及屬性3個知識要素,並以此為基礎,形成一系列高質量的事實表達,為上層模式層的構建奠定基礎。
1實體抽取
實體抽取也稱為命名實體學習(named entity learning) 或命名實體識別 (named entity recognition),指的是從原始資料語料中自動識別出命名實體。由於實體是知識圖譜中的最基本元素,其抽取的完整性、準確率、召回率等將直接影響到知識圖譜構建的質量。因此,實體抽取是知識抽取中更為基礎與關鍵的一步。參照文獻[13],我們可以將實體抽取的方法分為4種:基於百科站點或垂直站點提取、基於規則與詞典的方法、基於統計機器學習的方法以及面向開放域的抽取方法。基於百科站點或垂直站點提取則是一種很常規基本的提取方法;基於規則的方法通常需要為目標實體編寫模板,然後在原始語料中進行匹配;基於統計機器學習的方法主要是通過機器學習的方法對原始語料進行訓練,然後再利用訓練好的模型去識別實體;面向開放域的抽取將是面向海量的Web語料[14]。
1) 基於百科或垂直站點提取
基於百科站點或垂直站點提取這種方法是從百科類站點(如維基百科、百度百科、互動百科等)的標題和連結中提取實體名。這種方法的優點是可以得到開放網際網路中最常見的實體名,其缺點是對於中低頻的覆蓋率低。與一般性通用的網站相比,垂直類站點的實體提取可以獲取特定領域的實體。例如從豆瓣各頻道(音樂、讀書、電影等)獲取各種實體列表。這種方法主要是基於爬取技術來實現和獲取。基於百科類站點或垂直站點是一種最常規和基本的方法。
2) 基於規則與詞典的實體提取方法
早期的實體抽取是在限定文字領域、限定語義單元型別的條件下進行的,主要採用的是基於規則與詞典的方法,例如使用已定義的規則,抽取出文字中的人名、地名、組織機構名、特定時間等實體[15]。文獻[16]首次實現了一套能夠抽取公司名稱的實體抽取系統,其中主要用到了啟發式演算法與規則模板相結合的方法。然而,基於規則模板的方法不僅需要依靠大量的專家來編寫規則或模板,覆蓋的領域範圍有限,而且很難適應資料變化的新需求。
3) 基於統計機器學習的實體抽取方法
鑑於基於規則與詞典實體的侷限性,為具更有可擴充套件性,相關研究人員將機器學習中的監督學習演算法用於命名實體的抽取問題上。例如文獻[17]利用KNN演算法與條件隨機場模型,實現了對Twitter文字資料中實體的識別。單純的監督學習演算法在效能上不僅受到訓練集合的限制,並且演算法的準確率與召回率都不夠理想。相關研究者認識到監督學習演算法的制約性後,嘗試將監督學習演算法與規則相互結合,取得了一定的成果。例如文獻[18]基於字典,使用較大熵演算法在Medline論文摘要的GENIA資料集上進行了實體抽取實驗,實驗的準確率與召回率都在70%以上。近年來隨著深度學習的興起應用,基於深度學習的命名實體識別得到廣泛應用。在文獻[19],介紹了一種基於雙向LSTM深度神經網路和條件隨機場的識別方法,在測試資料上取得的較好的表現結果。
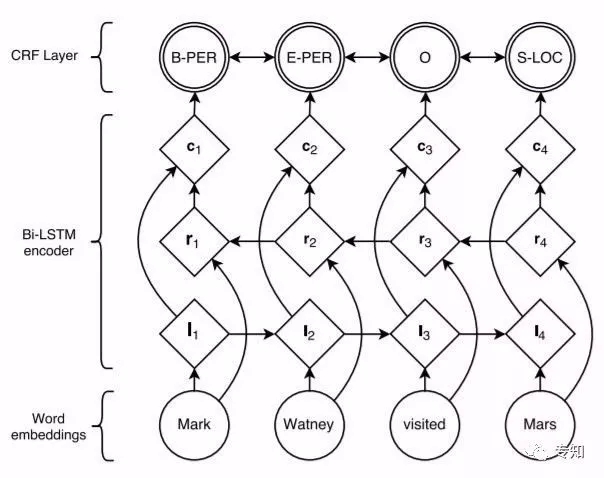
圖4 基於BI-LSTM和CRF的架構
4) 面向開放域的實體抽取方法
針對如何從少量實體例項中自動發現具有區分力的模式,進而擴充套件到海量文字去給實體做分類與聚類的問題,文獻[20]提出了一種通過迭代方式擴充套件實體語料庫的解決方案,其基本思想是通過少量的實體例項建立特徵模型,再通過該模型應用於新的資料集得到新的命名實體。文獻[21]提出了一種基於無監督學習的開放域聚類演算法,其基本思想是基於已知實體的語義特徵去搜索日誌中識別出命名的實體,然後進行聚類。
2語義類抽取
語義類抽取是指從文字中自動抽取資訊來構造語義類並建立實體和語義類的關聯, 作為實體層面上的規整和抽象。以下介紹一種行之有效的語義類抽取方法,包含三個模組:並列度相似計算、上下位關係提取以及語義類生成 [22]。
1) 並列相似度計算
並列相似度計算其結果是詞和詞之間的相似性資訊,例如三元組(蘋果,梨,s1)表示蘋果和梨的相似度是s1。兩個詞有較高的並列相似度的條件是它們具有並列關係(即同屬於一個語義類),並且有較大的關聯度。按照這樣的標準,北京和上海具有較高的並列相似度,而北京和汽車的並列相似度很低(因為它們不屬於同一個語義類)。對於海淀、朝陽、閔行三個市轄區來說,海淀和朝陽的並列相似度大於海淀和閔行的並列相似度(因為前兩者的關聯度更高)。
當前主流的並列相似度計算方法有分佈相似度法(distributional similarity) 和模式匹配法(pattern Matching)。分佈相似度方法[23-24]基於哈里斯(Harris)的分佈假設(distributional hypothesis)[25],即經常出現在類似的上下文環境中的兩個詞具有語義上的相似性。分佈相似度方法的實現分三個步驟:第一步,定義上下文;第二步,把每個詞表示成一個特徵向量,向量每一維代表一個不同的上下文,向量的值表示本詞相對於上下文的權重;第三步,計算兩個特徵向量之間的相似度,將其作為它們所代表的詞之間的相似度。 模式匹配法的基本思路是把一些模式作用於源資料,得到一些詞和詞之間共同出現的資訊,然後把這些資訊聚集起來生成單詞之間的相似度。模式可以是手工定義的,也可以是根據一些種子資料而自動生成的。分佈相似度法和模式匹配法都可以用來在數以百億計的句子中或者數以十億計的網頁中抽取詞的相似性資訊。有關分佈相似度法和模式匹配法所生成的相似度資訊的質量比較參見文獻。
2) 上下位關係提取
該該模組從文件中抽取詞的上下位關係資訊,生成(下義詞,上義詞)資料對,例如(狗,動物)、(悉尼,城市)。提取上下位關係最簡單的方法是解析百科類站點的分類資訊(如維基百科的“分類”和百度百科的“開放分類”)。這種方法的主要缺點包括:並不是所有的分類詞條都代表上位詞,例如百度百科中“狗”的開放分類“養殖”就不是其上位詞;生成的關係圖中沒有權重資訊,因此不能區分同一個實體所對應的不同上位詞的重要性;覆蓋率偏低,即很多上下位關係並沒有包含在百科站點的分類資訊中。
在英文資料上用Hearst 模式和IsA 模式進行模式匹配被認為是比較有效的上下位關係抽取方法。下面是這些模式的中文版本(其中NPC 表示上位詞,NP 表示下位詞):
NPC { 包括| 包含| 有} {NP、}* [ 等| 等等]
NPC { 如| 比如| 像| 象} {NP、}*
{NP、}* [{ 以及| 和| 與} NP] 等 NPC
{NP、}* { 以及| 和| 與} { 其它| 其他} NPC
NP 是 { 一個| 一種| 一類} NPC
此外,一些網頁表格中包含有上下位關係資訊,例如在帶有表頭的表格中,表頭行的文字是其它行的上位詞。
3) 語義類生成
該模組包括聚類和語義類標定兩個子模組。聚類的結果決定了要生成哪些語義類以及每個語義類包含哪些實體,而語義類標定的任務是給一個語義類附加一個或者多個上位詞作為其成員的公共上位詞。此模組依賴於並列相似性和上下位關係資訊來進行聚類和標定。有些研究工作只根據上下位關係圖來生成語義類,但經驗表明並列相似性資訊對於提高最終生成的語義類的精度和覆蓋率都至關重要。
3屬性和屬性值抽取
屬性提取的任務是為每個本體語義類構造屬性列表(如城市的屬性包括面積、人口、所在國家、地理位置等),而屬性值提取則為一個語義類的實體附加屬性值。屬性和屬性值的抽取能夠形成完整的實體概念的知識圖譜維度。常見的屬性和屬性值抽取方法包括從百科類站點中提取,從垂直網站中進行包裝器歸納,從網頁表格中提取,以及利用手工定義或自動生成的模式從句子和查詢日誌中提取。
常見的語義類/ 實體的常見屬性/ 屬性值可以通過解析百科類站點中的半結構化資訊(如維基百科的資訊盒和百度百科的屬性表格)而獲得。儘管通過這種簡單手段能夠得到高質量的屬性,但同時需要採用其它方法來增加覆蓋率(即為語義類增加更多屬性以及為更多的實體新增屬性值)。
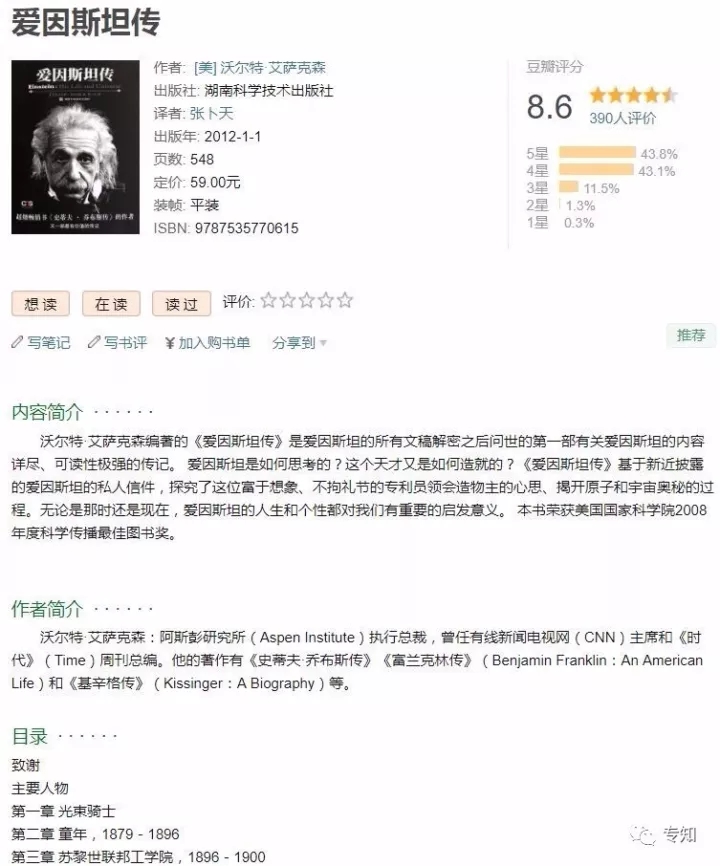
圖5 愛因斯坦資訊頁
由於垂直網站(如電子產品網站、圖書網站、電影網站、音樂網站)包含有大量實體的屬性資訊。例如上圖的網頁中包含了圖書的作者、出版社、出版時間、評分等資訊。通過基於一定規則模板建立,便可以從垂直站點中生成包裝器(或稱為模版),並根據包裝器來提取屬性資訊。從包裝器生成的自動化程度來看,這些方法可以分為手工法(即手工編寫包裝器)、監督方法、半監督法以及無監督法。考慮到需要從大量不同的網站中提取資訊,並且網站模版可能會更新等因素,無監督包裝器歸納方法顯得更加重要和現實。無監督包裝器歸納的基本思路是利用對同一個網站下面多個網頁的超文字標籤樹的對比來生成模版。簡單來看,不同網頁的公共部分往往對應於模版或者屬性名,不同的部分則可能是屬性值,而同一個網頁中重複的標籤塊則預示著重複的記錄。
屬性抽取的另一個資訊源是網頁表格。表格的內容對於人來說一目瞭然,而對於機器而言,情況則要複雜得多。由於表格型別千差萬別,很多表格製作得不規則,加上機器缺乏人所具有的背景知識等原因,從網頁表格中提取高質量的屬性資訊成為挑戰。
上述三種方法的共同點是通過挖掘原始資料中的半結構化資訊來獲取屬性和屬性值。與通過“閱讀”句子來進行資訊抽取的方法相比,這些方法繞開了自然語言理解這樣一個“硬骨頭”而試圖達到以柔克剛的效果。在現階段,計算機知識庫中的大多數屬性值確實是通過上述方法獲得的。但現實情況是隻有一部分的人類知識是以半結構化形式體現的,而更多的知識則隱藏在自然語言句子中,因此直接從句子中抽取資訊成為進一步提高知識庫覆蓋率的關鍵。當前從句子和查詢日誌中提取屬性和屬性值的基本手段是模式匹配和對自然語言的淺層處理。圖6 描繪了為語義類抽取屬性名的主框架(同樣的過程也適用於為實體抽取屬性值)。圖中虛線左邊的部分是輸入,它包括一些手工定義的模式和一個作為種子的(詞,屬性)列表。模式的例子參見表3,(詞,屬性)的例子如(北京,面積)。在只有語義類無關的模式作為輸入的情況下,整個方法是一個在句子中進行模式匹配而生成(語義類,屬性)關係圖的無監督的知識提取過程。此過程分兩個步驟,第一個步驟通過將輸入的模式作用到句子上而生成一些(詞,屬性)元組,這些資料元組在第二個步驟中根據語義類進行合併而生成(語義類,屬性)關係圖。在輸入中包含種子列表或者語義類相關模式的情況下,整個方法是一個半監督的自舉過程,分三個步驟:
模式生成:在句子中匹配種子列表中的詞和屬性從而生成模式。模式通常由詞和屬性的環境資訊而生成。
模式匹配。
模式評價與選擇:通過生成的(語義類,屬性)關係圖對自動生成的模式的質量進行自動評價並選擇高分值的模式作為下一輪匹配的輸入。
4關係抽取
關係抽取的目標是解決實體語義連結的問題。關係的基本資訊包括引數型別、滿足此關係的元組模式等。例如關係BeCapitalOf(表示一個國家的首都)的基本資訊如下:
引數型別:(Capital, Country)
模式:
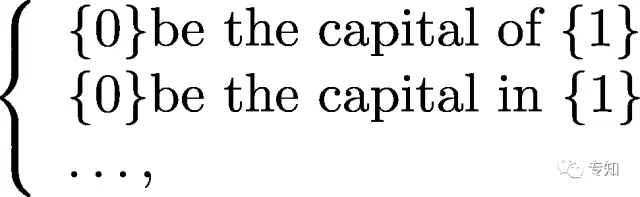
元組:(北京,中國);(華盛頓,美國);Capital 和 Country表示首都和國家兩個語義類。
早期的關係抽取主要是通過人工構造語義規則以及模板的方法識別實體關係。隨後,實體間的關係模型逐漸替代了人工預定義的語法與規則。但是仍需要提前定義實體間的關係型別。 文獻[26]提出了面向開放域的資訊抽取框架 (open information extraction,OIE),這是抽取模式上的一個巨大進步。但OIE方法在對實體的隱含關係抽取方面效能低下,因此部分研究者提出了基於馬爾可夫邏輯網、基於本體推理的深層隱含關係抽取方法[27]。
1)開放式實體關係抽取
開放式實體關係抽取可分為二元開放式關係抽取和n元開放式關係抽取。在二元開放式關係抽取中,早期的研究有KnowItAll[28]與TextRunner[27]系統,在準確率與召回率上表現一般。文獻[29]提出了一種基於Wikipedia的OIE方法WOE,經自監督學習得到抽取器,準確率較TextRunner有明顯的提高。針對WOE的缺點,文獻[30]提出了第二代OIE ReVerb系統,以動詞關係抽取為主。文獻[31]提出了第三代OIE系統OLLIE(open language learning for information extraction),嘗試彌補並擴充套件OIE的模型及相應的系統,抽取結果的準確度得到了增強。
然而,基於語義角色標註的OIE分析顯示:英文語句中40%的實體關係是n元的[32],如處理不當,可能會影響整體抽取的完整性。文獻[33]提出了一種可抽取任意英文語句中n元實體關係的方法KPAKEN,彌補了ReVerb的不足。但是由於演算法對語句深層語法特徵的提取導致其效率顯著下降,並不適用於大規模開放域語料的情況。
2)基於聯合推理的實體關係抽取
聯合推理的關係抽取中的典型方法是馬爾可夫邏輯網MLN(Markov logic network)[34],它是一種將馬爾可夫網路與一階邏輯相結合的統計關係學習框架,同時也是在OIE中融入推理的一種重要實體關係抽取模型。基於該模型,文獻[35]提出了一種無監督學習模型StatSnowball,不同於傳統的OIE,該方法可自動產生或選擇模板生成抽取器。在StatSnowball的基礎上,文獻[27,36]提出了一種實體識別與關係抽取相結合的模型EntSum,主要由擴充套件的CRF命名實體識別模組與基於StatSnowball的關係抽取模組組成,在保證準確率的同時也提高了召回率。文獻[27,37]提出了一種簡易的Markov邏輯TML(tractable Markov logic),TML將領域知識分解為若干部分,各部分主要來源於事物類的層次化結構,並依據此結構,將各大部分進一步分解為若干個子部分,以此類推。TML具有較強的表示能力,能夠較為簡潔地表示概念以及關係的本體結構。
2、知識表示
傳統的知識表示方法主要是以RDF(Resource Description Framework資源描述框架)的三元組SPO(subject,property,object)來符號性描述實體之間的關係。這種表示方法通用簡單,受到廣泛認可,但是其在計算效率、資料稀疏性等方面面臨諸多問題。近年來,以深度學習為代表的以深度學習為代表的表示學習技術取得了重要的進展,可以將實體的語義資訊表示為稠密低維實值向量,進而在低維空間中高效計算實體、關係及其之間的複雜語義關聯,對知識庫的構建、推理、融合以及應用均具有重要的意義[38-40]。
2.1 代表模型
知識表示學習的代表模型有距離模型、單層神經網路模型、雙線性模型、神經張量模型、矩陣分解模型、翻譯模型等。詳細可參見清華大學劉知遠的知識表示學習研究進展。相關實現也可參見 [39]。
1)距離模型
距離模型在文獻[41] 提出了知識庫中實體以及關係的結構化表示方法(structured embedding,SE),其基本思想是:首先將實體用向量進行表示,然後通過關係矩陣將實體投影到與實體關係對的向量空間中,最後通過計算投影向量之間的距離來判斷實體間已存在的關係的置信度。由於距離模型中的關係矩陣是兩個不同的矩陣,使得協同性較差。



2.2 複雜關係模型
知識庫中的實體關係型別也可分為1-to-1、1-to-N、N-to-1、N-to-N4種類型[47],而複雜關係主要指的是1-to-N、N-to-1、N-to-N的3種關係型別。由於TransE模型不能用在處理複雜關係上[39],一系列基於它的擴充套件模型紛紛被提出,下面將著重介紹其中的幾項代表性工作。
1)TransH模型
文獻[48]提出的TransH模型嘗試通過不同的形式表示不同關係中的實體結構,對於同一個實體而言,它在不同的關係下也扮演著不同的角色。模型首先通過關係向量與其正交的法向量選取某一個超平面F, 然後將頭實體向量和尾實體向量法向量的方向投影到F, 最後計算損失函式。TransH使不同的實體在不同的關係下擁有了不同的表示形式,但由於實體向量被投影到了關係的語義空間中,故它們具有相同的維度。

3)TransD模型
考慮到在知識庫的三元組中,頭實體和尾實體表示的含義、型別以及屬性可能有較大差異,之前的TransR模型使它們被同一個投影矩陣進行對映,在一定程度上就限制了模型的表達能力。除此之外,將實體對映到關係空間體現的是從實體到關係的語 義聯絡,而TransR模型中提出的投影矩陣僅考慮了不同的關係型別,而忽視了實體與關係之間的互動。因此,文獻[50]提出了TransD模型,模型分別定義了頭實體與尾實體在關係空間上的投影矩陣。
4)TransG模型
文獻[51]提出的TransG模型認為一種關係可能會對應多種語義,而每一種語義都可以用一個高斯分佈表示。TransG模型考慮到了關係r 的不同語義,使用高斯混合模型來描述知識庫中每個三元組(h,r,t)頭實體與尾實體之間的關係,具有較高的實體區分度。
5)KG2E模型
考慮到知識庫中的實體以及關係的不確定性,文獻[52]提出了KG2E模型,其中同樣是用高斯分佈來刻畫實體與關係。模型使用高斯分佈的均值表示實體或關係在語義空間中的中心位置,協方差則表示實體或關係的不確定度。
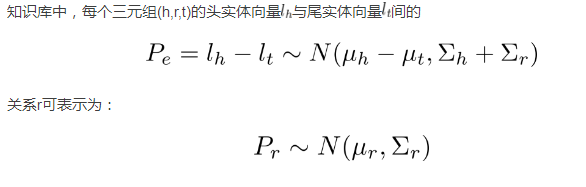
3/知識融合
通過知識提取,實現了從非結構化和半結構化資料中獲取實體、關係以及實體屬性資訊的目標。但是由於知識來源廣泛,存在知識質量良莠不齊、來自不同資料來源的知識重複、層次結構缺失等問題,所以必須要進行知識的融合。知識融合是高層次的知識組織[53],使來自不同知識源的知識在同一框架規範下進行異構資料整合、消歧、加工、推理驗證、更新等步驟[54],達到資料、資訊、方法、經驗以及人的思想的融合,形成高質量的知識庫。
3.1 實體對齊
實體對齊 (entity alignment) 也稱為實體匹配 (entity matching)或實體解析(entity resolution)或者實體連結(entity linking),主要是用於消除異構資料中實體衝突、指向不明等不一致性問題,可以從頂層建立一個大規模的統一知識庫,從而幫助機器理解多源異質的資料,形成高質量的知識。
在大資料的環境下,受知識庫規模的影響,在進行知識庫實體對齊時,主要會面臨以下3個方面的挑戰[55]:1) 計算複雜度。匹配演算法的計算複雜度會隨知識庫的規模呈二次增長,難以接受;2) 資料質量。由於不同知識庫的構建目的與方式有所不同,可能存在知識質量良莠不齊、相似重複資料、孤立資料、資料時間粒度不一致等問題[56];3) 先驗訓練資料。在大規模知識庫中想要獲得這種先驗資料卻非常困難。通常情況下,需要研究者手工構造先驗訓練資料。
基於上述,知識庫實體對齊的主要流程將包括[55]:1) 將待對齊資料進行分割槽索引,以降低計算的複雜度;2) 利用相似度函式或相似性演算法查詢匹配例項;3) 使用實體對齊演算法進行例項融合;4) 將步驟2)與步驟3)的結果結合起來,形成最終的對齊結果。對齊演算法可分為成對實體對齊與集體實體對齊兩大類,而集體實體對齊又可分為區域性集體實體對齊與全域性集體實體對齊。
1)成對實體對齊方法
① 基於傳統概率模型的實體對齊方法
基於傳統概率模型的實體對齊方法主要就是考慮兩個實體各自屬性的相似性,而並不考慮實體間的關係。文獻[57]將基於屬性相似度評分來判斷實體是否匹配的問題轉化為一個分類問題,建立了該問題的概率模型,缺點是沒有體現重要屬性對於實體相似度的影響。文獻[58]基於概率實體連結模型,為每個匹配的屬性對分配了不同的權重,匹配準確度有所提高。文獻[59]還結合貝葉斯網路對屬性的相關性進行建模,並使用較大似然估計方法對模型中的引數進行估計。
② 基於機器學習的實體對齊方法
基於機器學習的實體對齊方法主要是將實體對齊問題轉化為二分類問題。根據是否使用標註資料可分為有監督學習與無監督學習兩類,基於監督學習的實體對齊方法主要可分為成對實體對齊、基於聚類的對齊、主動學習。
通過屬性比較向量來判斷實體對匹配與否可稱為成對實體對齊。這類方法中的典型代表有決策樹 [60]、支援向量機[61]、整合學習[62]等。文獻[63]使用分類迴歸樹、線性分析判別等方法完成了實體辨析。文獻[64]基於二階段實體連結分析模型,提出了一種新的SVM分類方法,匹配準確率遠高於TAILOR中的混合演算法。
基於聚類的實體對齊演算法,其主要思想是將相似的實體儘量聚集到一起,再進行實體對齊。文獻[65]提出了一種擴充套件性較強的自適應實體名稱匹配與聚類演算法,可通過訓練樣本生成一個自適應的距離函式。文獻[66]採用類似的方法,在條件隨機場實體對齊模型中使用監督學習的方法訓練產生距離函式,然後調整權重,使特徵函式與學習引數的積較大。
在主動學習中,可通過與人員的不斷互動來解決很難獲得足夠的訓練資料問題,文獻[67]構建的ALIAS系統可通過人機互動的方式完成實體連結與去重的任務。文獻[68]採用相似的方法構建了ActiveAtlas系統。
2)區域性集體實體對齊方法
區域性集體實體對齊方法為實體本身的屬性以及與它有關聯的實體的屬性分別設定不同的權重,並通過加權求和計算總體的相似度,還可使用向量空間模型以及餘弦相似性來判別大規模知識庫中的實體的相似程度[69],演算法為每個實體建立了名稱向量與虛擬文件向量,名稱向量用於標識實體的屬性,虛擬文件向量則用於表示實體的屬性值以及其鄰居節點的屬性值的加權和值[55]。為了評價向量中每個分量的重要性,演算法主要使用TF-IDF為每個分量設定權重,併為分量向量建立倒排索引,最後選擇餘弦相似性函式計算它們的相似程度[55]。該演算法的召回率較高,執行速度快,但準確率不足。其根本原因在於沒有真正從語義方面進行考慮。
3)全域性集體實體對齊方法
① 基於相似性傳播的集體實體對齊方法
基於相似性傳播的方法是一種典型的集體實體對齊方法,匹配的兩個實體與它們產生直接關聯的其他實體也會具有較高的相似性,而這種相似性又會影響關聯的其他實體[55]。
相似性傳播集體實體對齊方法最早來源於文獻[70-71]提出的集合關係聚類演算法,該演算法主要通過一種改進的層次凝聚演算法迭代產生匹配物件。文獻[72]在以上演算法的基礎上提出了適用於大規模知識庫實體對齊的演算法SiGMa,該演算法將實體對齊問題看成是一個全域性匹配評分目標函式的優化問題進行建模,屬於二次分配問題,可通過貪婪優化演算法求得其近似解。SiGMa方法[55]能夠綜合考慮實體對的屬性與關係,通過集體實體的領域,不斷迭代發現所有的匹配對。
② 基於概率模型的集體實體對齊方法基於概率模型的集體實體對齊方法主要採用統計關係學習進行計算與推理,常用的方法有LDA模型[73]、CRF模型[74]、Markov邏輯網[75]等。
文獻[73]將LDA模型應用於實體的解析過程中,通過其中的隱含變數獲取實體之間的關係。但在大規模的資料集上效果一般。文獻[74]提出了一種基於圖劃分技術的CRF實體辨析模型,該模型以觀察值為條件產生實體判別的決策,有利於處理屬性間具有依賴關係的資料。文獻[66]在CRF實體辨析模型的基礎上提出了一種基於條件隨機場模型的多關係的實體連結演算法,引入了基於canopy的索引,提高了大規模知識庫環境下的集體實體對齊效率。文獻[75]提出了一種基於Markov邏輯網的實體解析方法。通過Markov邏輯網,可構建一個Markov網,將概率圖模型中的較大可能性計算問題轉化為典型的較大化加權可滿足性問題,但基於Markov網進行實體辨析時,需要定義一系列的等價謂詞公理,通過它們完成知識庫的集體實體對齊。
3.2 知識加工
通過實體對齊,可以得到一系列的基本事實表達或初步的本體雛形,然而事實並不等於知識,它只是知識的基本單位。要形成高質量的知識,還需要經過知識加工的過程,從層次上形成一個大規模的知識體系,統一對知識進行管理。知識加工主要包括本體構建與質量評估兩方面的內容。
1)本體構建
本體是同一領域內不同主體之間進行交流、連通的語義基礎[76],其主要呈現樹狀結構,相鄰的層次節點或概念之間具有嚴格的“IsA”關係,有利於進行約束、推理等,卻不利於表達概念的多樣性。本體在知識圖譜中的地位相當於知識庫的模具,通過本體庫而形成的知識庫不僅層次結構較強,並且冗餘程度較小[77]。
知識推理則是在已有的知識庫基礎上進一步挖掘隱含的知識,從而豐富、擴充套件知識庫。在推理的過程中,往往需要關聯規則的支援。由於實體、實體屬性以及關係的多樣性,人們很難窮舉所有的推理規則,一些較為複雜的推理規則往往是手動總結的。對於推理規則的挖掘,主要還是依賴於實體以及關係間的豐富同現情況。知識推理的物件可以是實體、實體的屬性、實體間的關係、本體庫中概念的層次結構等。知識推理方法主要可分為基於邏輯的推理與基於圖的推理兩種類別。
1) 基於邏輯的推理
基於邏輯的推理基於邏輯的推理方式主要包括一階謂詞邏輯(first order logic)、描述邏輯(description logic)以及規則等。一階謂詞邏輯推理是以命題為基本進行推理,而命題又包含個體和謂詞。邏輯中的個體對應知識庫中的實體物件,具有客觀獨立性,可以是具體一個或泛指一類,例如奧巴馬、選民等;謂詞則描述了個體的性質或個體間的關係。文獻[1]針對已有一階謂詞邏輯推理方法中存在的推理效率低下等問題,提出了一種基於謂詞變遷系統的圖形推理法,定義了描述謂詞間與/或關係的謂詞,通過謂詞圖表示變遷系統,實現了反向的推理目標。實驗結果表明:該方法推理效率較高,效能優越。描述邏輯是在命題邏輯與一階謂詞邏輯上發展而來,目的是在表示能力與推理複雜度之間追求一種平衡。基於描述邏輯的知識庫主要包括Tbox(terminology box)與ABox(assertion box)[2]。通過TBox與ABox,可將關於知識庫中複雜的實體關係推理轉化為一致性的檢驗問題,從而簡化並實現推理[3]。
通過本體的概念層次進行推理時,其中概念主要是通過OWL(Web ontology language)本體語義進行描述的。OWL文件可以表示為一個具有樹形結構的狀態空間,這樣一些對接結點的推理演算法就能夠較好地應用起來,例如文獻[4]提出了基於RDF和PD*語義的正向推理演算法,該演算法以RDF蘊涵規則為前提,結合了sesame演算法以及PD*的語義,是一個典型的迭代演算法,它主要考慮結點與推理規則的前提是否有匹配,由於該演算法的觸發條件導致推理的時間複雜度較高,文獻[5]提出了ORBO演算法,該演算法從結點出發考慮,判斷推理規則中第一條推理關係的前提是否滿足,不僅節約了時間,還降低了演算法的時間複雜度。
2)基於圖的推理
在基於圖的推理方法中,文獻[6]提出的pathconstraintrandom walk,path ranking等演算法較為典型,主要是利用了關係路徑中的蘊涵資訊,通過圖中兩個實體間的多步路徑來預測它們之間的語義關係。即從源節點開始,在圖上根據路徑建模演算法進行遊走,如果能夠到達目標節點,則推測源節點和目標節點間存在聯絡。關係路徑的建模方法研究工作尚處於初期,其中在關係路徑的可靠性計算、關係路徑的語義組合操作等方面,仍有很多工作需進一步探索並完成。
除上述兩種類別的知識推理方法外,部分研究人員將研究重點轉向跨知識庫的推理方法研究,例如文獻[7]提出的基於組合描述邏輯的Tableau演算法,該方法主要利用概念間的相似性對不同知識庫。
知識圖譜開源庫
Apache Jena(或簡稱Jena)是一個用於構建語義Web和關聯資料應用程式的自由和開源的Java框架。 該框架由不同的API組成,用於處理RDF資料。
Jena是一個用於Java語義Web應用程式的API(應用程式程式設計介面)。它不是一個程式或工具,如果這是你正在尋找,我建議或許TopBraid Composer作為一個好的選擇。因此,Jena的主要用途是幫助您編寫處理RDF和OWL文件和描述的Java程式碼。
更多詳細內容參見官網Apache Jena, 具體應用後續參考
知識圖譜構建的典型應用
知識圖譜為網際網路上海量、異構、動態的大資料表達、組織、管理以及利用提供了一種更為有效的方式,使得網路的智慧化水平更高,更加接近於人類的認知思維。目前,知識圖譜已在智慧搜尋、深度問答、社交網路以及一些垂直行業中有所應用,成為支撐這些應用發展的動力源泉。
1、智慧搜尋
基於知識圖譜的智慧搜尋是一種基於長尾的搜尋,搜尋引擎以知識卡片的形式將搜尋結果展現出來。使用者的查詢請求將經過查詢式語義理解與知識檢索兩個階段:1) 查詢式語義理解。知識圖譜對查詢式的語義分析主要包括:① 對查詢請求文字進行分詞、詞性標註以及糾錯;② 描述歸一化,使其與知識庫中的相關知識進行匹配[8];③ 語境分析。在不同的語境下,使用者查詢式中的物件會有所差別,因此知識圖譜需要結合使用者當時的情感,將使用者此時需要的答案及時反饋給使用者;④ 查詢擴充套件。明確了使用者的查詢意圖以及相關概念後,需要加入當前語境下的相關概念進行擴充套件。2) 知識檢索。經過查詢式分析後的標準查詢語句進入知識庫檢索引擎,引擎會在知識庫中檢索相應的實體以及與其在類別、關係、相關性等方面匹配度較高的實體[9]。通過對知識庫的深層挖掘與提煉後,引擎將給出具有重要性排序的完整知識體系。
智慧搜尋引擎主要以3種形式展現知識:1) 整合的語義資料。例如當用戶搜尋梵高,搜尋引擎將以知識卡片的形式給出梵高的詳細生平,並配合以圖片等資訊;2) 直接給出使用者查詢問題的答案。例如當用戶搜尋“姚明的身高是多少?”,搜尋引擎的結果是“226 cm”;3) 根據使用者的查詢給出推薦列表[7]等。
國外的搜尋引擎以谷歌的Google Search、微軟的Bing Search[10]更為典型。谷歌的知識圖譜相繼融入了維基百科、CIA世界概覽等公共資源以及從其他網站蒐集、整理的大量語義資料[11],微軟的BingSearch[10]和Facebook[11]、Twitter[12]等大型社交服務站點達成了合作協議,在使用者個性化內容的蒐集、定製化方面具有顯著的優勢。
國內的主流搜尋引擎公司,如百度、搜狗等在近兩年來相繼將知識圖譜的相關研究從概念轉向產品應用。搜狗的知立方[13]是國內搜尋引擎行業的第一款知識圖譜產品,它通過整合網際網路上的碎片化語義資訊,對使用者的搜尋進行邏輯推薦與計算,並將最核心的知識反饋給使用者。百度將知識圖譜命名為知心[14],主要致力於構建一個龐大的通用型知識網路,以圖文並茂的形式展現知識的方方面面。
2、深度問答
問答系統是資訊檢索系統的一種高階形式,能夠以準確簡潔的自然語言為使用者提供問題的解答。之所以說問答是一種高階形式的檢索,是因為在問答系統中同樣有查詢式理解與知識檢索這兩個重要的過程,並且與智慧搜尋中相應過程中的相關細節是完全一致的。多數問答系統更傾向於將給定的問題分解為多個小的問題,然後逐一去知識庫中抽取匹配的答案,並自動檢測其在時間與空間上的吻合度等,最後將答案進行合併,以直觀的方式展現給使用者。
目前,很多問答平臺都引入了知識圖譜,例如華盛頓大學的Paralex系統[15]和蘋果的智慧語音助手Siri[16],都能夠為使用者提供回答、介紹等服務;亞馬遜收購的自然語言助手Evi[17],它授權了Nuance的語音識別技術,採用True Knowledge引擎進行開發,也可提供類似Siri的服務。國內百度公司研發的小度機器人[18],天津聚問網路技術服務中心開發的大型線上問答系統OASK[19],專門為門戶、企業、媒體、教育等各類網站提供良好的互動式問答解決方案。
3、社交網路
社交網 站 Facebook 於2013 年推出了GraphSearch[20]產品,其核心技術就是通過知識圖譜將人、地點、事情等聯絡在一起,並以直觀的方式支援較精確的自然語言查詢,例如輸入查詢式:“我朋友喜歡的餐廳”“住在紐約並且喜歡籃球和中國電影的朋友”等,知識圖譜會幫助使用者在龐大的社交網路中找到與自己最具相關性的人、照片、地點和興趣等。Graph Search提供的上述服務貼近個人的生活,滿足了使用者發現知識以及尋找最具相關性的人的需求。
垂直行業應用
下面將以金融、醫療、電商行業為例,說明知識圖譜在上述行業中的典型應用。
1、金融行業
在金融行業中,反欺詐是一個重要的環節。它的難點在於如何將不同稅務子系統中的資料整合在一起。通過知識圖譜,一方面有利於組織相關的知識碎片,通過深入的語義分析與推理,可對資訊內容的一致性充分驗證,從而識別或提前發現欺詐行為;另一方面,知識圖譜本身就是一種基於圖結構的關係網路,基於這種圖結構能夠幫助人們更有效地分析複雜稅務關係中存在的潛在風險[21]。在精準營銷方面,知識圖譜可通過連結的多個數據源,形成對使用者或使用者群體的完整知識體系描述,從而更好地去認識、理解、分析使用者或使用者群體的行為。例如,金融公司的市場經理用知識圖譜去分析待銷售使用者群體之間的關係,去發現他們的共同愛好,從而更有針對性地對這類使用者人群制定營銷策略[21]。
2、醫療行業
耶魯大學擁有全球較大的神經科學資料庫Senselab[22],然而,腦科學研究還需要綜合從微觀分子層面一直到巨集觀行為層面的各個層次的知識。因此,耶魯大學的腦計劃研究人員將不同層次的,與腦研究相關的資料進行檢索、比較、分析、整合、建模、模擬,繪製出了描述腦結構的神經網路圖譜,從而解決了當前神經科學所面臨的海量資料問題,從微觀基因到巨集觀行為,從多個層次上加深了人類對大腦的理解,達到了“認識大腦、保護大腦、創造大腦”的目標。
3、電商行業
電商網站的主要目的之一就是通過對商品的文字描述、圖片展示、相關資訊羅列等視覺化的知識展現,為消費者提供最滿意的購物服務與體驗。通過知識圖譜,可以提升電商平臺的技術性、易用性、互動性等影響使用者體驗的因素[23]。
阿里巴巴是應用知識圖譜的代表電商網站之一,它旗下的一淘網不僅包含了淘寶數億的商品,更建立了商品間關聯的資訊以及從網際網路抽取的相關資訊,通過整合所有資訊,形成了阿里巴巴知識庫和產品庫,構建了它自身的知識圖譜[24]。當用戶輸入關鍵詞檢視商品時,知識圖譜會為使用者提供此次購物方面最相關的資訊,包括整合後分類羅列的商品結果、使用建議、搭配等[24]。
除此之外,另外一些垂直行業也需要引入知識圖譜,如教育科研行業、圖書館、證券業、生物醫療以及需要進行大資料分析的一些行業[25]。這些行業對整合性和關聯性的資源需求迫切,知識圖譜可以為其提供更加較精確規範的行業資料以及豐富的表達,幫助使用者更加便捷地獲取行業知識.
4、司法行業
知識圖譜在司法領域的運用悄然興起,它幫助從業人員快速地線上檢索相關的法務內容,從而提高法院審判工作質量和效率[26]。
參考文獻
描述邏輯. 描述邏輯基礎知識[EB/OL]. (2014-02-24). http://www.2cto.com/database/201402/280927.html
LEE T W, LEWICKI M S, GIROLAMI M, et al. Blind source separation of more sources than mixtures using overcomplete representation[J]. Signal Processing Letters, 1999, 6(4): 87-90.
Ian Dickinson. Imp Iementation experience with the DIG 1.1specification[EB/OL]. (2004-05-10). http://www.hpl.hp. com/semweb/publications.html.
龔資. 基於OWL描述的本體推理研究[D]. 長春: 吉林大學, 2007.
LIU Shao-yuan, HSU K H, KUO Li-jing. A semantic service match approach based on wordnet and SWRL rules[C]//Proc of the 10th IEEE Int Conf on E-Business Engineering. Piscataway, NJ: IEEE, 2013: 419-422.
LAO N, MITCHELL T, COHEN W W. Random walk inference and learning in a large scale knowledge base[C]//Proc of EMNLP. Stroudsburg, PA: ACL, 2011:529-539.
蔣勳, 徐緒堪. 面向知識服務的知識庫邏輯結構模型[J].圖書與情報, 2013(6): 23-31.
王志, 夏士雄, 牛強. 本體知識庫的自然語言查詢重寫研究[J]. 微電子學與計算機, 2009, 26(8): 137-139.
BLANCO R, CAMBAZOGLU B B, MIKE P, et al. Entity recommendation in web search[C]//Pro of the 12th International Semantic Web conference(ISWC). Berlin: Springer-Verlag, 2013: 33-48.
BRACHMAN R J. What IS-A is and isn't: an analysis of taxonomic links in semantic networks[J]. Computer; (United States), 1983, 10(1): 5-13.
Facebook. Facebook[EB/OL]. [2014-02-04]. https://www.facebook.com/.
Twitter. Twitter[EB/OL]. [2016-05-08]. https://twitter.com/.
百度百科.搜狗知立方[EB/OL]. [2016-05-07]. http://baike.baidu.com/link?url=_J_2r2xYz0qSTwlYxqPZ00ZZuYyiA_kkZAohtC5EhmIzOjSwywKheEThY2gdXdzxS
Baidu. Zhi xin[EB/OL]. [2016-06-08].
Fader. Paralex[EB/OL]. [2016-05-08]. http://knowitall.cs.washington.edu/paralex.
百度百科. Siri[EB/OL]. [2016-05-02]. http://baike.baidu.com/subview/6573497/7996501.htm.
百度百科. Evi[EB/OL]. [2016-03-18]. http://baike.baidu.com/view/7574050.htm.
百度. 度祕[EB/OL]. (2015-09-13). http://xiaodu.baidu.com/.
百度百科. OASK 問答系統[EB/OL]. [2016-03-27]. http:// baike.baidu.com/view/8206827.htm.
百度百科. Graph search[EB/OL]. [2016-01-22]. http://baike.baidu.com/view/9966007.htm.
李文哲. 網際網路金融, 如何用知識圖譜識別欺詐行為[EB/OL].
Senselab. Center for medical informatics at yale university school of medicine yale university school of medicine [EB/OL]. [2016-01-08]. http://ycmi.med.yale.edu/.
田玲, 馬麗儀. 基於使用者體驗的網站資訊服務水平綜合評價研究[J]. 生態經濟, 2013(10): 160-162.
一淘網.知識圖譜[EB/OL]. (2014-12-12). https://www.
aliyun.com/zixun/aggregation/13323.html.
李涓子. 知識圖譜: 大資料語義連結的基石[EB/OL].(2015-02-20). http://www.cipsc.org.cn/kg2/.
知識圖譜技術在司法領域的應用:國雙科技的探索與技術分享。http://mp.weixin.qq.com/s/aVEBf_VxkXpmx3Z3xUBtm