
HashMap和HashSet總結
本文是作者在專案過程中做的總結,內容既有借鑑其他大神的地方,也有自己結合當前專案的思考。若有錯誤的地方,歡迎指正!最後感謝以下作者的分享!!
參考來源1:http://www.importnew.com/7099.html
參考來源2:https://blog.csdn.net/chenssy/article/details/18323767
參考來源3:https://blog.csdn.net/chenssy/article/details/21988605
1.HashMap
它是基於雜湊表的Map介面的實現,是一種支援快速存取的資料結構,以鍵值對的形式儲存資料。在HashMap中,key-value會被當做一個整體來處理,系統會根據hash演算法來計算key-value的位置,實現通過key快速存、取value。
1.1定義
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
HashMap繼承AbstractMap類(AbstractMap實現了Map介面),在這裡又再次實現了Map介面(當初寫這段程式碼的 Josh Bloch說這就是一個寫法錯誤。詳情見https://stackoverflow.com/questions/2165204/why-does-linkedhashsete-extend-hashsete-and-implement-sete
Map介面定義了鍵對映到值的規則,而AbstractMap類提供Map介面的骨幹實現,以最大限度的減少實現此介面所需的工作。
1.2影響HashMap效能的重要引數
1.2.1初始容量
容量表示雜湊表中桶的數量,初始容量是建立雜湊表時的容量。若未指定容量,則預設初始容量為16。
1.2.2載入因子
載入因子是雜湊表在容量自動增加之前可以達到多滿的一種尺度,它衡量的是一個散列表空間的使用程度。載入因子越大表示散列表的裝填程度越高,反之愈小。對於連結串列雜湊來說,查詢一個元素的平均時間是O(1+a),因此如果負載因子越大,對空間的利用更充分,然而後果是查詢效率的降低;如果負載因子太小,那麼散列表的資料將過於稀疏,對空間造成嚴重浪費。系統預設負載因子為0.75,一般情況下我們是無需修改的。
1.3資料結構
每次新建一個HashMap,都會初始化一個table陣列。table陣列的元素為Entry節點。其中Entry為HashMap的內部類,它包含了鍵key,值value,下一個節點next以及hash值。正是由於Entry才構成了table陣列的項為連結串列。
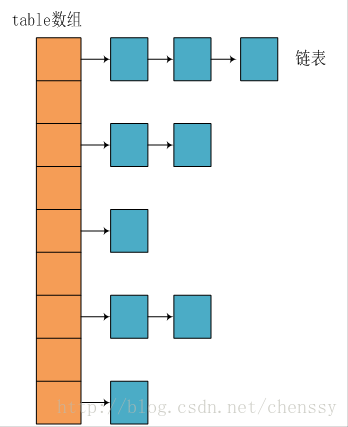
1.4儲存實現:put(key,value)
當我們向一個HashMap新增一對key-value時,首先根據key計算hash值,然後根據hash值確定在table陣列中的位置,即bucket的位置。若該位置沒有元素,則直接插入,否則迭代此處的entry節點構成的連結串列。若兩個hash值相等且key值相等(e.hash == hash && ((k = e.key) == key || key.equals(k))),則用新的entry的value覆蓋原來節點的value。如果兩個hash值相等但key值不等,則將該節點插入連結串列的鏈頭。
1.5讀取實現:get(key)
讀取的前提是:hashcode相同,bucket位置相同。hashcode相同,key不一定相同;key相同,hashcode一定相同。
通過key的hash值找到table陣列中的索引處的連結串列,遍歷連結串列,找到hash和key值相等的Entry節點。
1.6相關面試題
1.6.1你知道HashMap的工作原理嗎?
HashMap是基於hashing的原理,我們使用put(key,value)儲存物件到HashMap中,使用get(key)從HashMap中獲取物件。當我們給put方法傳遞鍵值時,我們先對鍵呼叫hashcode()方法,返回的hash值用於找到bucket位置來儲存Entry物件。
1.6.2當兩個物件的hashcode相同會發生什麼?
因為hashcode相同,bucket位置相同,‘碰撞’會發生。遍歷bucket位置的連結串列,由Entry節點構成的連結串列,若hash值和key值相等,則用新的Entry節點的value替換原來節點的value,否則將新的Entry節點插入連結串列的表頭。
1.6.3如果兩個鍵的hashcode相同,你如何獲取值物件?
通過hashcode找到bucke位置,遍歷連結串列,判斷key值是否相等,直到找到值物件。
1.6.4如果HashMap的大小超過了負載因子(load factor)定義的容量,怎麼辦?
預設的負載因子大小為0.75,也就是說,當一個map填滿了75%的bucket時候,和其它集合類(如ArrayList等)一樣,將會建立原來HashMap大小的兩倍的bucket陣列,來重新調整map的大小,並將原來的物件放入新的bucket陣列中。這個過程叫作rehashing,因為它呼叫hash方法找到新的bucket位置。
1.7Java8新特性:Map computeIfAbsent方法說明
參考來源:https://blog.csdn.net/weixin_38229356/article/details/81129320
1.8什麼時候用HashMap?
1.當一個函式需要return多個引數時,可以通過Map返回。
2.當函式形參較多或者不確定個數時,可以通過Map傳參。
3.對大量資料進行分組整理,例如:本專案中的供應商資訊根據能提供的原料id進行分組。
4.實現下拉列表key-value可以通過List<Map>的方式實現。
5.字典值 通過value找name :Map<String,Map<String,String>>
例如:訂單型別(order_type):日(day)周(week)月(month) firstMap.put("order_type",secondMap)
secondMap.put("day","日"),secondMap.put("week","周"),secondMap.put("month","月")
6.將List/array轉為Map,將判斷依據放到key,要獲取的資訊放到value,利用Map快速存取的特性實現快速判斷集合中是否包含某個元素,從而提高程式的執行效率。
7.JSONArray->JSONObject->JSONString的轉換:將JSONArray放到map中,由於JSONObject本身就是一個map,再通過JSON.toJSONString()方法將JSON物件轉化為JSON字串。
2.HashSet
HashSet是基於HashMap來實現的,底層採用HashMap來儲存元素。
2.1定義
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
Set介面是一種不包含重複元素的collection,它維持它自己的內部排序,所以隨機訪問沒有意義。簡而言之,HashSet是無序、不重複的集合。(HashMap是按照HashCode大小進行排序)
2.2基本屬性
//基於HashMap實現,底層使用HashMap儲存所有元素
private transient HashMap<E,Object> map;
//定義一個Object物件作為HashMap的value
private static final Object PRESENT = new Object();
HashSet中的所有元素都是儲存在HashMap的key中,value則是使用的PRESENT物件。由於HashMap中key不會重複,因此滿足 了HashSet中元素不會重複的特性。
2.3什麼時候用HashSet?
當集合元素需要去重且對元素的順序沒有要求時使用!例如:本專案中的獲取所有原料單位、商品單位、選單id。