
Kafka 原理詳解
Kafka 原理詳解
1 kakfa基礎概念說明
Broker:訊息伺服器,就是我們部署的一個kafka服務
Partition:訊息的水平分割槽,一個Topic可以有多個分割槽,這樣實現了訊息的無限量儲存
Replica:訊息的副本,即備份訊息,儲存在其他的broker上,當leader掛掉之後,可以從存有副本的broker中選舉leader,實現了高可用
Topic:一個訊息投遞目標的名稱,這個目標可以理解為一個訊息歸類或者遞目標的名稱。對於每一個Topic,kafka會為其維護一個如下圖所示的分割槽的日誌檔案
log:每個partition分割槽是一個有序的,不可修改的,訊息組成的對了,這些訊息是不斷的appended到這個commit log上的。這些partitions之中的每個訊息都會被賦予一個叫做offset的順序id編號,用來在partition中唯一性的標識這個訊息。
kafka叢集會儲存一個時間段內所有被髮布出來的資訊,無論這個訊息是否已經被消費過,這個時間段可以進行配置。
kafka的效能與資料流不相干,所以儲存大量的訊息資料不會造成效能問題
kafka關注的每個消費者的元資料資訊也只有消費者的offset。這個offset由消費者控制,通常情況下當消費者讀取資訊時,這個數值是線性遞增的,實際上消費者可以控制這個值,以獲取較早實際的資訊。
對log進行分割槽的目的是:
這可以讓log的伸縮能力超過單臺伺服器上限,每個獨立的partition的大小受單臺伺服器的效能限制,但一個topic可以有很多partition,從而它可以處理任意大小的資料
在並行處理這方面可以作為一個獨立的單元
分散式:log的partition被分佈到kafka叢集中,每個伺服器負責處理彼此共享的partition的一部分資料和請求,每個partition被賦值成指定的份數散佈在機器之中提供故障轉移能力,對於每個partition都有一個伺服器作為它的leader,其他伺服器則作為followers,leader負責處理關於這個partition所有的讀寫請求,followers則被動的複製leader。每個伺服器作為某些partition的leader的同時也作為其他伺服器的followers,從而實現叢集的負載均衡。
Producer:生產者,將資料釋出到指定的topic的partition上,這個選擇策略可以配置
Consumer:消費者,kafka提供了一個consumer group的模式,一個組的所有消費者視為同一個抽象的消費者,每個消費者都有自己的消費組名稱標示
訊息通訊通常有兩種模式:
佇列模式,一組消費者可能從一個伺服器讀取訊息,每個訊息被髮送給了其中一個消費者,在kafka中,如果所有的消費者都處於同一個組,則這個結構就是佇列模式

訂閱模式,訊息被廣播給了所有的消費者,在kafka中,如果所有消費者都處於不同的組,則這個結構就是訂閱模式

Guarantees:生產者傳送Topic某個partition的訊息都被有序的追加到之前傳送的訊息之後,對於特定的消費者,它觀察到的訊息的順序與訊息儲存到log中的順序一致,對於一個複製N份的topic,系統能保證在N-1臺伺服器失效的情況下不丟失任何已提交到log中的資訊
kafka提供的訊息順序保證機制:
傳統的訊息佇列在伺服器上有序的儲存訊息,當有多個消費者的時候訊息也是按序傳送訊息。但是因為訊息投遞到消費者的過程是非同步的,所以訊息到達消費者的順序可能是亂序的。這就意味著在平行計算的場景下,訊息的有序性已經喪失了。訊息系統通常採用一個“排他消費者”的概念來規避這個問題,但這樣就意味著失去了並行處理的能力。
Kafka 在這一點上做的更優秀。Kafka 有一個 Topic 中按照 partition 並行的概念,這使它即可以提供訊息的有序性擔保,又可以提供消費者之間的負載均衡。這是通過將 Topic 中的partition 繫結到消費者組中的具體消費者實現的。通過這種方案我們可以保證消費者是某個partition 唯一消費者,從而完成訊息的有序消費。因為 Topic有多個 partition所以在消費者例項之間還是負載均衡的。注意,雖然有以上方案,但是如果想擔保訊息的有序性那麼我們就不能為一個partition 註冊多個消費者了。

2 Kafka設計思想
2.1 持久化
kafka的訊息是儲存在硬碟上的,因為“磁碟慢”這個普遍性的認知,常常使人們懷疑一個這樣的持久化結構是否能提供所需的效能。但實際上磁碟因為使用的方式不同,它可能比人們預想的慢很多也可能比人們預想的快很多;而且一個合理設計的磁碟檔案結構常常可以使磁碟執行得和網路一樣快。
kafka的設計是將所有的資料被直接寫入檔案系統上一個可暫不執行磁碟 flush 操作的持久化日誌檔案中。實際上這意味著這些資料是被傳送到了核心的頁快取上。
我們在上一節討論了磁碟效能。 一旦消除了磁碟訪問模式不佳的情況,該類系統性能低下的主要原因就剩下了兩個:
大量的小型 I/O 操作(小包問題),以及過多的位元組拷貝(ZeroCopy)
小型的 I/O 操作發生在客戶端和服務端之間以及服務端自身的持久化操作中。
為了避免這種情況,我們的協議是建立在一個 “訊息塊” 的抽象基礎上,合理將訊息分組。 這使得網路請求將多個訊息打包成一組,而不是每次傳送一條訊息,從而使整組訊息分擔網路中往返的開銷。伺服器一次性的將多個訊息快依次追加到日誌檔案中, Consumer 也是每次獲取多個大型有序的訊息塊。這個簡單的優化對速度有著數量級的提升。批處理允許更大的網路資料包,更大的順序讀寫磁碟操作,連續的記憶體塊等等,所有這些都使 KafKa 能將隨機性突發性的訊息寫操作變成順序性的寫操作最終流向消費者。
另一個低效率的操作是位元組拷貝,在訊息量少時,這不是什麼問題。但是在高負載的情況下,影響就不容忽視。為了避免這種情況,我們讓 producer ,broker 和 consumer 都共享的標準化的二進位制訊息格式,這樣資料塊不用修改就能在他們之間傳遞。
broker 維護的訊息日誌本身就是一個檔案目錄,每個檔案都由一系列以相同格式寫入到磁碟的訊息集合組成,這種寫入格式被 producer 和 consumer 共用。保持這種通用格式可以對一些很重要的操作進行優化:持久化日誌塊的網路傳輸。 現代的 unix 作業系統提供了高度優化的資料路徑,用於將資料從 pagecache 轉移到 socket 網路連線中;在 Linux 中系統呼叫sendfile 做到這一點。
為了理解 sendfile 的意義,首先要了解資料從檔案到套接字的一般資料傳輸路徑:
作業系統從磁碟讀取資料到核心空間的 pagecache
應用程式讀取核心空間的資料到使用者空間的緩衝區
應用程式將資料(使用者空間的緩衝區)寫回核心空間的套接字緩衝區(核心空間)
作業系統將資料從套接字緩衝區(核心空間)複製到通過網路傳送的 NIC 緩衝區
這顯然是低效的,有四次 copy 操作和兩次系統呼叫。使用 sendfile 方法,可以允許作業系統將資料從 pagecache 直接傳送到網路,這樣避免重複資料複製。所以這種優化方式,只需要最後一步的 copy 操作,將資料複製到 NIC 緩衝區。我們預期的使用場景是一個 topic 被多個消費者消費。使用 zero-copy (零拷貝)優化,資料僅僅會被複制到 pagecache 一次,在後續的消費過程中都可以複用,而不是儲存在記憶體中在每次消費時再複製到核心空間。這使得訊息能夠以接近網路連線的速度被消費。
pagecache 和 sendfile 的組合使用意味著,在一個 Kafka 叢集中,大多數的(緊跟生產者的)consumer 消費時,將看不到磁碟上的讀取活動,因為資料完全由快取提供。
2.2 端到端的批量壓縮
Kafka 以高效的批處理格式支援一批訊息可以壓縮在一起傳送到伺服器。這批訊息將以壓縮格式寫入,並且在日誌中保持壓縮,只會在 consumer 消費時解壓縮。
Kafka 支援 GZIP,Snappy 和 LZ4 壓縮協議。
2.3 The Producer
生產者直接傳送資料到主分割槽的伺服器上,不需要經過任何中間路由。
客戶端控制訊息傳送資料到哪個分割槽,這個可以實現隨機的負載均衡方式,或者使用一些特定語義的分割槽函式。我們有提供特定分割槽的介面讓用於根據指定的鍵值進行 hash 分割槽(當然也有選項可以重寫分割槽函式),例如,如果使用使用者 ID 作為 key,則使用者相關的所有資料都會被分發到同一個分割槽上。這允許消費者在消費資料時做一些特定的本地化處理。這樣的分割槽風格經常被設計用於一些對本地處理比較敏感的消費者。
批處理是提升效能的一個主要驅動,為了允許批量處理,kafka 生產者會嘗試在記憶體中彙總資料,並用一次請求批次提交資訊。 批處理,不僅僅可以配置指定的訊息數量,也可以指定等待特定的延遲時間(如 64k 或 10ms),這允許彙總更多的資料後再發送,在伺服器端也會減少更多的 IO 操作。 該緩衝是可配置的,並給出了一個機制,通過權衡少量額外的延遲時間獲取更好的吞吐量。
2.4 The Consumer
Kafka consumer 通過向 broker 發出一個“fetch”請求來獲取它想要消費的 partition。consumer 的每個請求都在 log 中指定了對應的 offset,並接收從該位置開始的一大塊資料。並且可以在需要的時候通過回退到該位置再次消費對應的資料。
持續追蹤已經被消費的內容是訊息系統的關鍵效能點之一。
Kafka 使用完全不同的方式解決訊息丟失問題。Kafka 的 topic 被分割成了一組完全有序的partition,其中每一個 partition 在任意給定的時間內只能被每個訂閱了這個 topic 的consumer 組中的一個 consumer 消費。這意味著 partition 中 每一個consumer 的位置僅僅是一個數字,即下一條要消費的訊息的 offset。這使得被消費的訊息的狀態資訊相當少,每partition只需要一個數字。這個狀態資訊還可以作為週期性的 checkpoint。這以非常低的代價實現了和訊息確認機制等同的效果。
這種方式還有一個附加的好處。consumer 可以回退到之前的 offset 來再次消費之前的資料,這個操作違反了佇列的基本原則,但事實證明對大多數 consumer 來說這是一個必不可少的特性。 例如,如果 consumer 的程式碼有 bug,並且在 bug 被發現前已經有一部分資料被消費了,那麼 consumer 可以在 bug 修復後通過回退到之前的 offset 來再次消費這些資料。
離線資料載入
可伸縮的持久化特性允許 consumer 只進行週期性的消費,例如批量資料載入,週期性將資料載入到諸如 Hadoop 和關係型資料庫之類的離線系統中。
在 Hadoop 的應用場景中,我們通過將資料載入分配到多個獨立的 map 任務來實現並行化,每一個 map 任務負責一個 node/topic/partition,從而達到充分並行化。Hadoop 提供了任務管理機制,失敗的任務可以重新啟動而不會有重複資料的風險,只需要簡單的從原來的位置重啟即可。
2.5 訊息交付語義
Kafka 可以提供的訊息交付語義保證有:
At most once - 訊息可能會丟失但絕不重傳
At least once - 訊息可以重傳但絕不丟失
Exactly once - 這可能是使用者真正想要的,每條訊息只被傳遞一次
2.6 Replication
Kafka 允許 topic 的 partition 擁有若干副本,你可以在 server 端配置 partition 的副本數量。
當叢集中的節點出現故障時,能自動進行故障轉移,保證資料的可用性。
建立副本的單位是 topic 的 partition ,正常情況下,每個分割槽都有一個 leader 和零或多個followers 。總的副本數是包含 leader 的總和。所有的讀寫操作都由 leader 處理,一般partition 的數量都比 broker 的數量多的多,各分割槽的 leader 均勻的分佈在 brokers 中。所有的 followers 節點都同步 leader 節點的日誌,日誌中的訊息和偏移量都和 leader 中的一致。(當然,在任何給定時間,leader 節點的日誌末尾時可能有幾個訊息尚未被備份完成)。
Followers 節點就像普通的 consumer 那樣從 leader 節點那裡拉取訊息並儲存在自己的日誌檔案中。Followers 節點可以從 leader 節點那裡批量拉取訊息日誌到自己的日誌檔案中。
與大多數分散式系統一樣,自動處理故障需要精確定義節點 “alive” 的概念。Kafka 判斷節點是否存活有兩種方式:
節點必須可以維護和 ZooKeeper 的連線,Zookeeper 通過心跳機制檢查每個節點的連線。
如果節點是個 follower ,它必須能及時的同步 leader 的寫操作,並且延時不能太久。
我們認為滿足這兩個條件的節點處於 “in sync” 狀態,區別於 “alive” 和 “failed” 。Leader 會追蹤所有 “in sync” 的節點。如果有節點掛掉了,或是寫超時,或是心跳超時,leader 就會把它從同步副本列表中移除。 同步超時和寫超時的時間由 replica.lag.time.max.ms 配置確定。
分散式系統中,我們只嘗試處理 “fail/recover” 模式的故障,即節點突然停止工作,然後又恢復(節點可能不知道自己曾經掛掉)的狀況。Kafka 沒有處理所謂的 “Byzantine” 故障,即一個節點出現了隨意響應和惡意響應(可能由於 bug 或 非法操作導致)。
當所有的分割槽上 in sync repicas 都應用到 log 上時,訊息可以認為是 “committed”,只有committed 訊息才會給 consumer。這意味著 consumer 不需要擔心潛在因為 leader 失敗而丟失訊息。而對於 producer 來說,可以依據 latency 和 durability 來權衡選擇是否等待訊息被committed ,這個行動由 producer 使用的 acks 設定來決定。
在所有時間裡,Kafka 保證只要有至少一個同步中的節點存活,提交的訊息就不會丟失。
節點掛掉後,經過短暫的故障轉移後,Kafka 將仍然保持可用性,但在網路分割槽( networkpartitions )的情況下可能不能保持可用性。
2.7 可靠性和永續性的保證
向 Kafka 寫資料時,producers 設定 ack 是否提交完成,
0:不等待 broker 返回確認訊息,
1: leader 儲存成功返回或,
-1(all): 所有備份都儲存成功返回。
請注意。設定 “ack = all” 並不能保證所有的副本都寫入了訊息。預設情況下,當 acks = all 時,只要 ISR 副本同步完成,就會返回訊息已經寫入。例如,一個 topic 僅僅設定了兩個副本,那麼只有一個 ISR 副本,那麼當設定 acks = all 時返回寫入成功時,剩下了的那個副本資料也可能資料沒有寫入。儘管這確保了分割槽的最大可用性,但是對於偏好資料永續性而不是可用性的一些使用者,可能不想用這種策略,因此,我們提供了兩個 topic 配置,可用於優先配置訊息資料永續性:
禁用 unclean leader 選舉機制 - 如果所有的備份節點都掛了,分割槽資料就會不可用,直到最近的 leader 恢復正常。這種策略優先於資料丟失的風險,參看上一節的 uncleanleader 選舉機制。
指定最小的 ISR 集合大小,只有當 ISR 的大小大於最小值,分割槽才能接受寫入操作,以防止僅寫入單個備份的訊息丟失造成訊息不可用的情況,這個設定只有在生產者使acks = all 的情況下才會生效,這至少保證訊息被 ISR 副本寫入。此設定是一致性和可用性 之間的折衷,對於設定更大的最小 ISR 大小保證了更好的一致性,因為它保證將訊息被寫入了更多的備份,減少了訊息丟失的可能性。但是,這會降低可用性,因為如果ISR 副本的數量低於最小閾值,那麼分割槽將無法寫入。
2.8 備份管理
上面關於 replicated logs 的討論僅僅侷限於單一 log ,比如一個 topic 分割槽。但是 Kafka 叢集需要管理成百上千個這樣的分割槽。我們嘗試輪流的方式來在叢集中平衡分割槽來避免在小節點上處理大容量的 topic。
同樣關於 leadership 選舉的過程也同樣的重要,這段時間可能是無法服務的間隔。一個原始的 leader 選舉實現是當一個節點失敗時會在所有的分割槽節點中選主。相反,我們選用 broker之一作為 “controller”, 這個 controller 檢測 broker 失敗,並且為所有受到影響的分割槽改變leader。這個結果是我們能夠將許多需要變更 leadership 的通知整合到一起,讓選舉過程變得更加容易和快速。如果 controller 失敗了,存活的 broker 之一會變成新的 controller。
2.9 日誌壓縮
日誌壓縮可確保 Kafka 始終至少為單個 topic partition 的資料日誌中的每個 message key 保留最新的已知值。這樣的設計解決了應用程式崩潰、系統故障後恢復或者應用在執行維護過程中重啟後重新載入快取的場景。接下來讓我們深入討論這些在使用過程中的更多細節,闡述在這個過程中它是如何進行日誌壓縮的。
迄今為止,我們只介紹了簡單的日誌保留方法(當舊的資料保留時間超過指定時間、日誌檔案大小達到設定大小後就丟棄)。這樣的策略非常適用於處理那些暫存的資料,例如記錄每條訊息之間相互獨立的日誌。然而在實際使用過程中還有一種非常重要的場景 – 根據 key 進行資料變更(例如更改資料庫表內容),使用以上的方式顯然不行。
讓我們來討論一個關於處理這樣流式資料的具體的例子。假設我們有一個 topic,裡面的內容包含使用者的 email 地址;每次使用者更新他們的 email 地址時,我們傳送一條訊息到這個topic,這裡使用使用者 Id 作為訊息的 key 值。現在,我們在一段時間內為 id 為 123 的使用者傳送一些訊息,每個訊息對應 email 地址的改變。
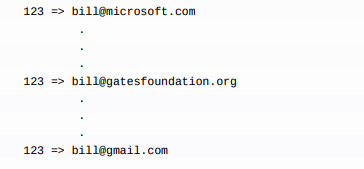
日誌壓縮為我們提供了更精細的保留機制,所以我們至少保留每個 key 的最後一次更新(例如:[email protected])。這樣我們保證日誌包含每一個 key 的最終值而不只是最近變更的完整快照。這意味著下游的消費者可以獲得最終的狀態而無需拿到所有的變化的訊息資訊。
資料庫更改訂閱。通常需要在多個數據系統設定擁有一個數據集,這些系統中通常有一個是某種型別的資料庫(無論是 RDBMS 或者新流行的 key-value 資料庫)。 例如,你可能有一個數據庫,快取,搜尋引擎叢集或者 Hadoop 叢集。每次變更資料庫,也同時需要變更快取、搜尋引擎以及 hadoop 叢集。 在只需處理最新日誌的實時更新的情況下,你只需要最近的日誌。但是,如果你希望能夠重新載入快取或恢復搜尋失敗的節點,你可能需要一個完整的資料集。
事件源。 這是一種應用程式設計風格,它將查詢處理與應用程式設計相結合,並使用變更的日誌作為應用程式的主要儲存。
日誌高可用。 執行本地計算的程序可以通過登出對其本地狀態所做的更改來實現容錯,以便另一個程序可以重新載入這些更改並在出現故障時繼續進行。 一個具體的例子就是在流查詢系統中進行計數,聚合和其他類似“group by”的操作。實時流處理框架Samza,使用這個特性 正是出於這一原因。
日誌壓縮機制是更細粒度的、每個記錄都保留的機制,而不是基於時間的粗粒度。這個理念是選擇性刪除那些有更新的變更的記錄的日誌。這樣最終日誌至少包含每個 key 的記錄的最後一個狀態。
這種保留策略可以針對每一個 topci 進行設定,遮掩一個叢集中,可以讓部分 topic 通過時間和大小保留日誌,另一些可以通過壓縮策略保留。
日誌壓縮基礎
這是一個高級別的日誌邏輯圖,展示了 kafka 日誌的每條訊息的 offset 邏輯結構。

Log head 中包含傳統的 Kafka 日誌,它包含了連續的 offset 和所有的訊息。日誌壓縮增加了處理 tail Log 的選項。上圖展示了日誌壓縮的的 Log tail 的情況。tail 中的訊息儲存了初次寫入時的 offset。 即使該 offset 的訊息被壓縮,所有 offset 仍然在日誌中是有效的。在這個場景中,無法區分和下一個出現的更高 offset 的位置。如上面的例子中,36、37、38 是屬於相同位置的,從他們開始讀取日誌都將從 38 開始。
壓縮也允許刪除。通過訊息的 key 和空負載(null payload)來標識該訊息可從日誌中刪除。這個刪除標記將會引起所有之前擁有相同 key 的訊息被移除(包括擁有 key 相同的新訊息)。但是刪除標記比較特殊,它將在一定週期後被從日誌中刪除來釋放空間。這個時間點被稱為“delete retention point”,如上圖。
壓縮操作通過後臺週期性的拷貝日誌段來完成。清除操作不會阻塞讀取,並且可以被配置不超過一定 IO 吞吐來避免影響 Producer 和 Consumer。實際的日誌段壓縮過程有點像這樣:

日誌壓縮的保障措施:
任何滯留在日誌 head 中的所有消費者能看到寫入的所有訊息;這些訊息都是有序的offset。 topic 使用 min.compaction.lag.ms 來保障訊息寫入之前必須經過的最小時間長度,才能被壓縮。 這限制了一條訊息在 Log Head 中的最短存在時間。
訊息始終保持有序。壓縮永遠不會重新排序訊息,只是刪除了一些。
訊息的 Offset 永遠不會變更。這是訊息在日誌中的永久標誌。
任何從頭開始處理日誌的 Consumer 至少會拿到每個 key 的最終狀態。另外,只要Consumer 在小於 Topic 的 delete.retention.ms 設定(預設 24 小時)的時間段內到達Log head,將會看到所有刪除記錄的所有刪除標記。換句話說,因為移除刪除標記和讀取是同時發生的,Consumer 可能會因為落後超過 delete.retention.ms 而導致錯過刪除
標記。
Log壓縮的細節:
日誌壓縮由 log cleaner 執行,log cleaner 是一個後臺執行緒池,它會 recopy 日誌段檔案,移除那些 key 存在於 Log Head 中的記錄。每個壓縮執行緒工作的步驟如下:
選擇 log head 與 log tail 比率最高的日誌
在 head log 中為每個 key 最後 offset 建立一個簡單概要
從日誌的開始到結束,刪除那些在日誌中最新出現的 key 的舊值。新的、乾淨的日誌會被立即提交到日誌中,所以只需要一個額外的日誌段空間(不是日誌的完整副本)
日誌 head 的概念本質上是一個空間密集的 hash 表,每個條目使用 24 個位元組。所以如果有 8G 的整理緩衝區,則能迭代處理大約 336G 的 log head (假設訊息大小為 1k)
配置Log Cleaner
log.cleaner.enable=true
這會啟動清理執行緒池。如果要開啟特定 topic 的清理功能,需要開啟特定的 log-specific 屬性
log.cleanup.policy=compact
這個可以通過建立 topic 時配置或者之後使用 topic 命令實現。
2.10 配額
producers 和 consumer 可能會產生和消費大量的訊息從而導致獨佔 broker 資源,進而引起網路飽和,對其他 client 和 broker 造成 DOS 攻擊。資源的配額保護可以有效的防止這些問題,大型的多租戶叢集中,因為一小部分表現不佳的客戶端降低了良好的使用者體驗,這種情況下非常需要資源的配額保護。實際情況中,當把 Kafka 當做一種服務提供時,可以根據客戶端和服務端的契約對 API 呼叫做限制。
預設情況下,每個唯一的客戶端分組在叢集上配置一個固定的限額,這個限額是基於每臺伺服器的 (quota.producer.default, quota.consumer.default),每個客戶端能釋出或獲取每臺伺服器都的最大速率,我們按伺服器 (broker) 定義配置,而不是按整個叢集定義,是因為如果是叢集範圍需要額外的機制來共享配額的使用情況,這會導致配額機制的實現比較難。
覆蓋 client-ids 預設的配額是可行的。這個機制類似於每一個 topic 日誌的配置覆蓋。client-id覆蓋會被寫到 ZooKeeper,這個覆蓋會被所有的 broker 讀取並且迅速載入生效。這樣使得我們可以不需要重啟叢集中的機器而快速的改變配額。
---------------------
作者:yingziisme
來源:CSDN
原文:https://blog.csdn.net/yingziisme/article/details/83549845
版權宣告:本文為博主原創文章,轉載請附上博文連結!