
MASK R-CNN學習
MASK R-CNN是何凱明大神之作,這裡就自己的理解記錄一下MASK R-CNN的簡單流程,以便自己複習參考,如有錯誤望大家指正。
MASK R-CNN是由R-CNN, Fast R-CNN,Faster R-CNN進化而來的,具體每個演算法的簡單剖析可以參考
https://blog.csdn.net/jiongnima/article/details/79094159
在例項分割Mask R-CNN框架中,主要完成了三件事情:
1) 目標檢測:直接在結果圖上繪製了目標框(bounding box)。
2) 目標分類:對於每一個目標,需要找到對應的類別(class),區分到底是人,是車,還是其他類別。
3) 畫素級目標分割:在每個目標中,需要在畫素層面區分,什麼是前景,什麼是背景。
Mask R-CNN(區域卷積神經網路)框架分三部分:第一部分全圖通過backbone網路提取特徵圖;第二部分掃描影象並生成proposals(可能包含物件的候選區域);第三部分對proposals進行分類並生成邊界框和掩碼。它是在Faster R-CNN的基礎上添加了一個mask分支,對於每個ROI使用一個small FCN來完成畫素級的分割的。
MASK R-CNN的整體框架如下圖所示:
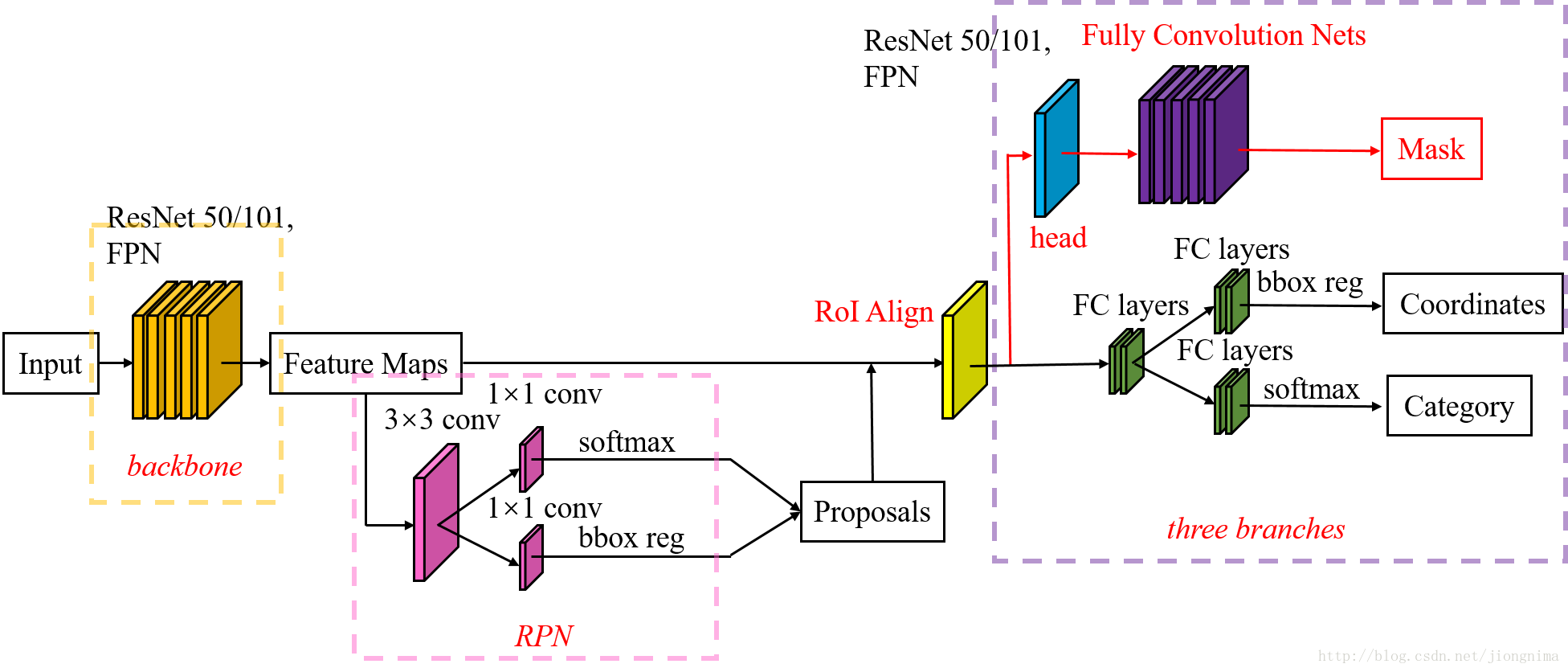
圖片參考地址:https://blog.csdn.net/jiongnima/article/details/79094159
(1)使用一個CNN神經網路對全圖提取特徵
這是一個標準的卷積神經網路(通常是ResNet50或ResNet101),我們用它來提取特徵。 較低層檢測低階特徵(邊緣和角落),後續層檢測更高級別的特徵(汽車,人物,天空)。
(2)提取的特徵圖送入RPN,修正目標區域

RPN是一個輕量級的神經網路,以滑動視窗的方式掃描影象並找到包含物件的區域。在每個滑動視窗中都會有9種初始anchor包含三種面積(128×128,256×256,512×512),每種面積又包含三種長寬比(1:1,1:2,2:1)。滑動視窗就是分佈在影象區域上的紅框,如上圖所示。不過,這只是一個簡化的檢視。實際上,由於共享特徵圖的大小約為40×60,RPN生成的初始anchor的總數約為20000個(40×60×9)。對於生成的anchor,RPN要做的事情有兩個,第一個是判斷anchor到底是前景還是背景,意思就是判斷這個anchor到底有沒有覆蓋目標;第二個是為屬於前景的anchor進行第一次座標修正。
RPN掃描速度有多快?其實很快。滑動視窗允許它並行掃描所有區域(在GPU上)。此外,RPN不會直接掃描影象(即使我們在影象上繪製錨點以便說明)。相反,RPN掃描骨幹網路生成的Feature map。這允許RPN有效地重用提取的特徵並避免大量的重複計算。根據Faster-RCNN的論文,RPN執行大約10 ms。在Mask RCNN中,我們通常使用更大的影象和更多的錨點,因此可能需要更長的時間。針對每個錨點,RPN有兩個輸出:

1.錨點的種類:前景或背景。前景類意味著該框中可能有一個物件。
2.邊界框細化:前景錨點(也稱為正錨點)可能沒有完全正對該物件。 因此,RPN會輸出一個很小的微量變化(百分比):(x, y, width, heigh),以更好地適應物體。
使用RPN預測,我們選擇可能包含物件並優化其位置和大小的頂部錨點。如果幾個錨點重疊太多,我們會保留具有最高前景分數的錨點並丟棄其餘的(稱為非極大值抑制:Non-max Suppression)。在這之後我們會得到進入下一階段的最終提案(感興趣的區)。
參考:https://blog.csdn.net/qq_15969343/article/details/80167215
(3)在Mask R-CNN中的RoI Align之後有一個"head"部分,主要作用是將RoI Align的輸出維度擴大,這樣在預測Mask時會更加精確。在Mask Branch的訓練環節,作者沒有采用FCN式的SoftmaxLoss,反而是輸出了K個Mask預測圖(為每一個類都輸出一張),並採用average binary cross-entropy loss訓練,當然在訓練Mask branch的時候,輸出的K個特徵圖中,也只是對應ground truth類別的那一個特徵圖對Mask loss有貢獻。
anchor邊框修正的訓練方法和RoI Align的詳細介紹見https://blog.csdn.net/jiongnima/article/details/79094159